 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparTa: Sparse Graphical Task Models from a Handful of Demonstrations
Feb 18, 2026Learning long-horizon manipulation tasks efficiently is a central challenge in robot learning from demonstration. Unlike recent endeavors that focus on directly learning the task in the action domain, we focus on inferring what the robot should achieve in the task, rather than how to do so. To this end, we represent evolving scene states using a series of graphical object relationships. We propose a demonstration segmentation and pooling approach that extracts a series of manipulation graphs and estimates distributions over object states across task phases. In contrast to prior graph-based methods that capture only partial interactions or short temporal windows, our approach captures complete object interactions spanning from the onset of control to the end of the manipulation. To improve robustness when learning from multiple demonstrations, we additionally perform object matching using pre-trained visual features. In extensive experiments, we evaluate our method's demonstration segmentation accuracy and the utility of learning from multiple demonstrations for finding a desired minimal task model. Finally, we deploy the fitted models both in simulation and on a real robot, demonstrating that the resulting task representations support reliable execution across environments.
Scaling Single Human Demonstrations for Imitation Learning using Generative Foundational Models
Feb 13, 2026Imitation learning is a popular paradigm to teach robots new tasks, but collecting robot demonstrations through teleoperation or kinesthetic teaching is tedious and time-consuming. In contrast, directly demonstrating a task using our human embodiment is much easier and data is available in abundance, yet transfer to the robot can be non-trivial. In this work, we propose Real2Gen to train a manipulation policy from a single human demonstration. Real2Gen extracts required information from the demonstration and transfers it to a simulation environment, where a programmable expert agent can demonstrate the task arbitrarily many times, generating an unlimited amount of data to train a flow matching policy. We evaluate Real2Gen on human demonstrations from three different real-world tasks and compare it to a recent baseline. Real2Gen shows an average increase in the success rate of 26.6% and better generalization of the trained policy due to the abundance and diversity of training data. We further deploy our purely simulation-trained policy zero-shot in the real world. We make the data, code, and trained models publicly available at real2gen.cs.uni-freiburg.de.
cVLA: Towards Efficient Camera-Space VLAs
Jul 02, 2025Vision-Language-Action (VLA) models offer a compelling framework for tackling complex robotic manipulation tasks, but they are often expensive to train. In this paper, we propose a novel VLA approach that leverages the competitive performance of Vision Language Models (VLMs) on 2D images to directly infer robot end-effector poses in image frame coordinates. Unlike prior VLA models that output low-level controls, our model predicts trajectory waypoints, making it both more efficient to train and robot embodiment agnostic. Despite its lightweight design, our next-token prediction architecture effectively learns meaningful and executable robot trajectories. We further explore the underutilized potential of incorporating depth images, inference-time techniques such as decoding strategies, and demonstration-conditioned action generation. Our model is trained on a simulated dataset and exhibits strong sim-to-real transfer capabilities. We evaluate our approach using a combination of simulated and real data, demonstrating its effectiveness on a real robotic system.
Neural Fields in Robotics: A Survey
Oct 26, 2024



Neural Fields have emerged as a transformative approach for 3D scene representation in computer vision and robotics, enabling accurate inference of geometry, 3D semantics, and dynamics from posed 2D data. Leveraging differentiable rendering, Neural Fields encompass both continuous implicit and explicit neural representations enabling high-fidelity 3D reconstruction, integration of multi-modal sensor data, and generation of novel viewpoints. This survey explores their applications in robotics, emphasizing their potential to enhance perception, planning, and control. Their compactness, memory efficiency, and differentiability, along with seamless integration with foundation and generative models, make them ideal for real-time applications, improving robot adaptability and decision-making. This paper provides a thorough review of Neural Fields in robotics, categorizing applications across various domains and evaluating their strengths and limitations, based on over 200 papers. First, we present four key Neural Fields frameworks: Occupancy Networks, Signed Distance Fields, Neural Radiance Fields, and Gaussian Splatting. Second, we detail Neural Fields' applications in five major robotics domains: pose estimation, manipulation, navigation, physics, and autonomous driving, highlighting key works and discussing takeaways and open challenges. Finally, we outline the current limitations of Neural Fields in robotics and propose promising directions for future research. Project page: https://robonerf.github.io
Learning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
Sep 11, 2024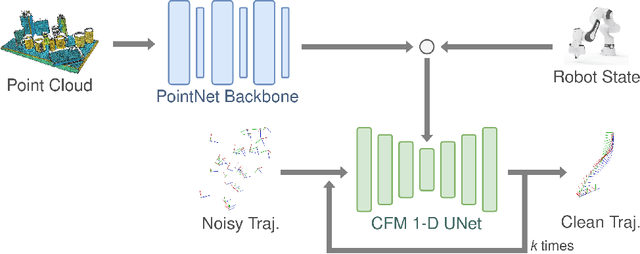



Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.
Imagine2touch: Predictive Tactile Sensing for Robotic Manipulation using Efficient Low-Dimensional Signals
May 02, 2024Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term Imagine2touch. Imagine2touch aims to predict the expected touch signal based on a visual patch representing the area to be touched. We use ReSkin, an inexpensive and compact touch sensor to collect the required dataset through random touching of five basic geometric shapes, and one tool. We train Imagine2touch on two out of those shapes and validate it on the ood. tool. We demonstrate the efficacy of Imagine2touch through its application to the downstream task of object recognition. In this task, we evaluate Imagine2touch performance in two experiments, together comprising 5 out of training distribution objects. Imagine2touch achieves an object recognition accuracy of 58% after ten touches per object, surpassing a proprioception baseline.
CenterArt: Joint Shape Reconstruction and 6-DoF Grasp Estimation of Articulated Objects
Apr 23, 2024


Precisely grasping and reconstructing articulated objects is key to enabling general robotic manipulation. In this paper, we propose CenterArt, a novel approach for simultaneous 3D shape reconstruction and 6-DoF grasp estimation of articulated objects. CenterArt takes RGB-D images of the scene as input and first predicts the shape and joint codes through an encoder. The decoder then leverages these codes to reconstruct 3D shapes and estimate 6-DoF grasp poses of the objects. We further develop a mechanism for generating a dataset of 6-DoF grasp ground truth poses for articulated objects. CenterArt is trained on realistic scenes containing multiple articulated objects with randomized designs, textures, lighting conditions, and realistic depths. We perform extensive experiments demonstrating that CenterArt outperforms existing methods in accuracy and robustness.
DITTO: Demonstration Imitation by Trajectory Transformation
Mar 22, 2024



Teaching robots new skills quickly and conveniently is crucial for the broader adoption of robotic systems. In this work, we address the problem of one-shot imitation from a single human demonstration, given by an RGB-D video recording through a two-stage process. In the first stage which is offline, we extract the trajectory of the demonstration. This entails segmenting manipulated objects and determining their relative motion in relation to secondary objects such as containers. Subsequently, in the live online trajectory generation stage, we first \mbox{re-detect} all objects, then we warp the demonstration trajectory to the current scene, and finally, we trace the trajectory with the robot. To complete these steps, our method makes leverages several ancillary models, including those for segmentation, relative object pose estimation, and grasp prediction. We systematically evaluate different combinations of correspondence and re-detection methods to validate our design decision across a diverse range of tasks. Specifically, we collect demonstrations of ten different tasks including pick-and-place tasks as well as articulated object manipulation. Finally, we perform extensive evaluations on a real robot system to demonstrate the effectiveness and utility of our approach in real-world scenarios. We make the code publicly available at http://ditto.cs.uni-freiburg.de.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024



Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.
CenterGrasp: Object-Aware Implicit Representation Learning for Simultaneous Shape Reconstruction and 6-DoF Grasp Estimation
Dec 13, 2023Reliable object grasping is a crucial capability for autonomous robots. However, many existing grasping approaches focus on general clutter removal without explicitly modeling objects and thus only relying on the visible local geometry. We introduce CenterGrasp, a novel framework that combines object awareness and holistic grasping. CenterGrasp learns a general object prior by encoding shapes and valid grasps in a continuous latent space. It consists of an RGB-D image encoder that leverages recent advances to detect objects and infer their pose and latent code, and a decoder to predict shape and grasps for each object in the scene. We perform extensive experiments on simulated as well as real-world cluttered scenes and demonstrate strong scene reconstruction and 6-DoF grasp-pose estimation performance. Compared to the state of the art, CenterGrasp achieves an improvement of 38.5 mm in shape reconstruction and 33 percentage points on average in grasp success. We make the code and trained models publicly available at http://centergrasp.cs.uni-freiburg.de.