 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
Paper and Code
Sep 11, 2024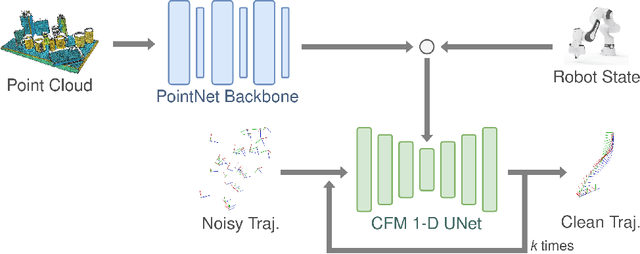



Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.