 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Optimization for Learning Controllers for Bipedal Locomotion
Paper and Code
Oct 15, 2016
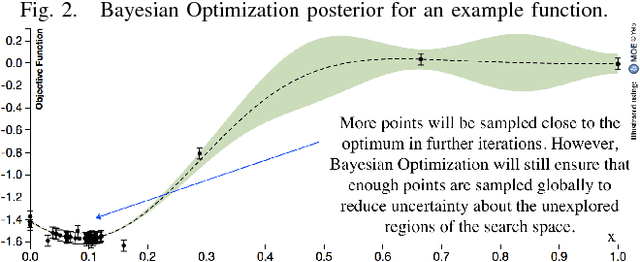
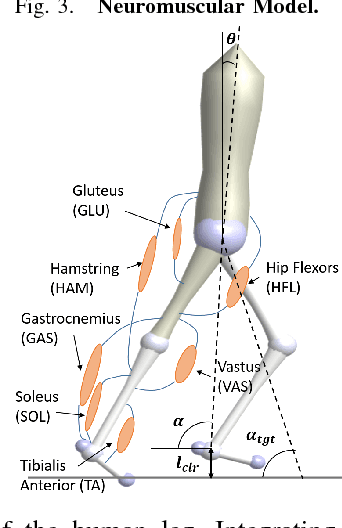
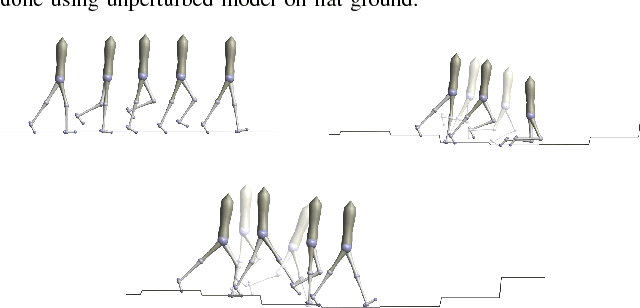
Learning policies for bipedal locomotion can be difficult, as experiments are expensive and simulation does not usually transfer well to hardware. To counter this, we need al- gorithms that are sample efficient and inherently safe. Bayesian Optimization is a powerful sample-efficient tool for optimizing non-convex black-box functions. However, its performance can degrade in higher dimensions. We develop a distance metric for bipedal locomotion that enhances the sample-efficiency of Bayesian Optimization and use it to train a 16 dimensional neuromuscular model for planar walking. This distance metric reflects some basic gait features of healthy walking and helps us quickly eliminate a majority of unstable controllers. With our approach we can learn policies for walking in less than 100 trials for a range of challenging settings. In simulation, we show results on two different costs and on various terrains including rough ground and ramps, sloping upwards and downwards. We also perturb our models with unknown inertial disturbances analogous with differences between simulation and hardware. These results are promising, as they indicate that this method can potentially be used to learn control policies on hardware.