 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Facial Descriptors for Accurate Face Animation
Jan 29, 2025



Face animation is a challenging task. Existing model-based methods (utilizing 3DMMs or landmarks) often result in a model-like reconstruction effect, which doesn't effectively preserve identity. Conversely, model-free approaches face challenges in attaining a decoupled and semantically rich feature space, thereby making accurate motion transfer difficult to achieve. We introduce the semantic facial descriptors in learnable disentangled vector space to address the dilemma. The approach involves decoupling the facial space into identity and motion subspaces while endowing each of them with semantics by learning complete orthogonal basis vectors. We obtain basis vector coefficients by employing an encoder on the source and driving faces, leading to effective facial descriptors in the identity and motion subspaces. Ultimately, these descriptors can be recombined as latent codes to animate faces. Our approach successfully addresses the issue of model-based methods' limitations in high-fidelity identity and the challenges faced by model-free methods in accurate motion transfer. Extensive experiments are conducted on three challenging benchmarks (i.e. VoxCeleb, HDTF, CelebV). Comprehensive quantitative and qualitative results demonstrate that our model outperforms SOTA methods with superior identity preservation and motion transfer.
Class Prototype-based Cleaner for Label Noise Learning
Dec 21, 2022



Semi-supervised learning based methods are current SOTA solutions to the noisy-label learning problem, which rely on learning an unsupervised label cleaner first to divide the training samples into a labeled set for clean data and an unlabeled set for noise data. Typically, the cleaner is obtained via fitting a mixture model to the distribution of per-sample training losses. However, the modeling procedure is \emph{class agnostic} and assumes the loss distributions of clean and noise samples are the same across different classes. Unfortunately, in practice, such an assumption does not always hold due to the varying learning difficulty of different classes, thus leading to sub-optimal label noise partition criteria. In this work, we reveal this long-ignored problem and propose a simple yet effective solution, named \textbf{C}lass \textbf{P}rototype-based label noise \textbf{C}leaner (\textbf{CPC}). Unlike previous works treating all the classes equally, CPC fully considers loss distribution heterogeneity and applies class-aware modulation to partition the clean and noise data. CPC takes advantage of loss distribution modeling and intra-class consistency regularization in feature space simultaneously and thus can better distinguish clean and noise labels. We theoretically justify the effectiveness of our method by explaining it from the Expectation-Maximization (EM) framework. Extensive experiments are conducted on the noisy-label benchmarks CIFAR-10, CIFAR-100, Clothing1M and WebVision. The results show that CPC consistently brings about performance improvement across all benchmarks. Codes and pre-trained models will be released at \url{https://github.com/hjjpku/CPC.git}.
SKFlow: Learning Optical Flow with Super Kernels
May 29, 2022
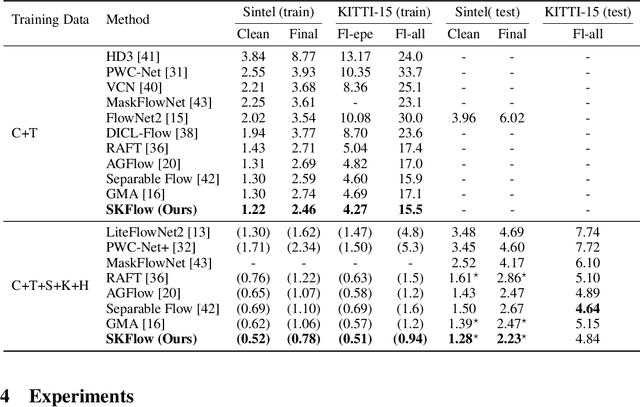
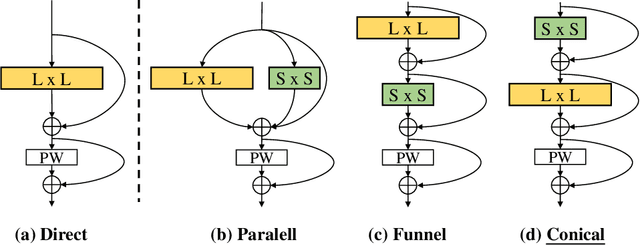
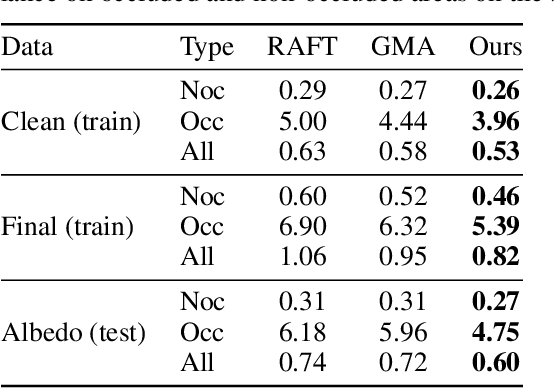
Optical flow estimation is a classical yet challenging task in computer vision. One of the essential factors in accurately predicting optical flow is to alleviate occlusions between frames. However, it is still a thorny problem for current top-performing optical flow estimation methods due to insufficient local evidence to model occluded areas. In this paper, we propose Super Kernel Flow Network (SKFlow), a CNN architecture to ameliorate the impacts of occlusions on optical flow estimation. SKFlow benefits from the super kernels which bring enlarged receptive fields to complement the absent matching information and recover the occluded motions. We present efficient super kernel designs by utilizing conical connections and hybrid depth-wise convolutions. Extensive experiments demonstrate the effectiveness of SKFlow on multiple benchmarks, especially in the occluded areas. Without pre-trained backbones on ImageNet and with modest increase in computation, SKFlow achieves compelling performance and ranks $\textbf{1st}$ among current published methods on Sintel benchmark. On the challenging Sintel final pass test set, SKFlow attains the average end-point error of $2.23$, which surpasses the best published result $2.47$ by $9.72\%$.
PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering
Sep 17, 2021
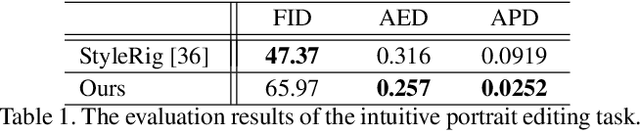
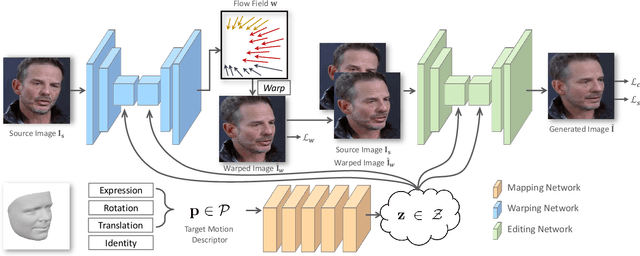

Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream. Our source code is available at https://github.com/RenYurui/PIRender.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 24, 2021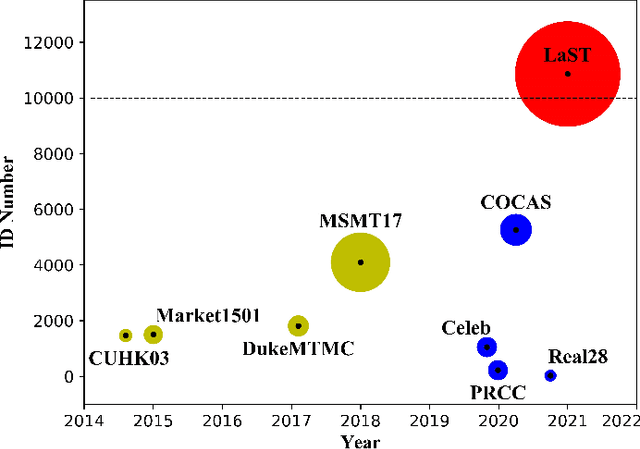
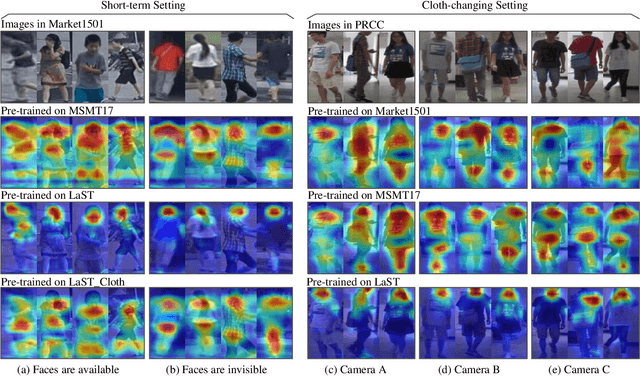
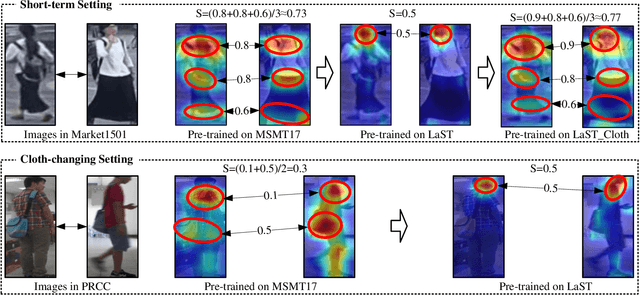

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal LaST person re-ID dataset, including 10,862 identities with more than 228k images. Compared with existing datasets, LaST presents more challenging and high-diversity re-ID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatio-temporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Low Pass Filter for Anti-aliasing in Temporal Action Localization
Apr 23, 2021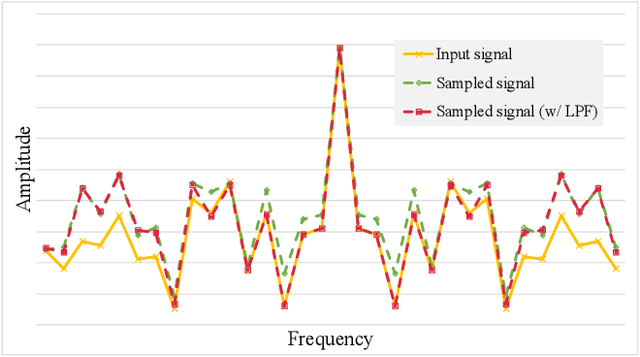

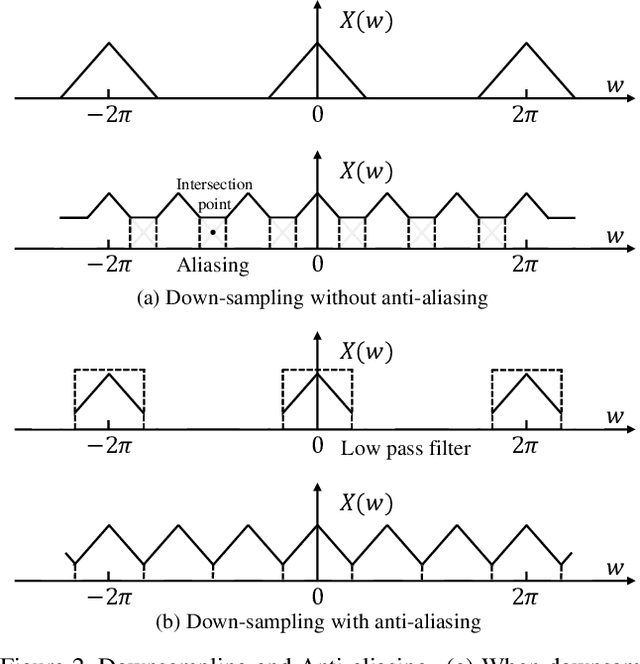
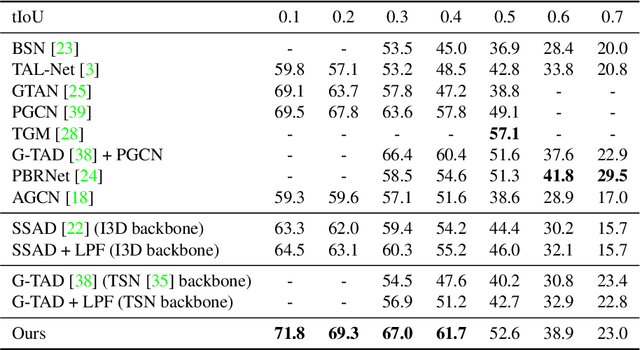
In temporal action localization methods, temporal downsampling operations are widely used to extract proposal features, but they often lead to the aliasing problem, due to lacking consideration of sampling rates. This paper aims to verify the existence of aliasing in TAL methods and investigate utilizing low pass filters to solve this problem by inhibiting the high-frequency band. However, the high-frequency band usually contains large amounts of specific information, which is important for model inference. Therefore, it is necessary to make a tradeoff between anti-aliasing and reserving high-frequency information. To acquire optimal performance, this paper learns different cutoff frequencies for different instances dynamically. This design can be plugged into most existing temporal modeling programs requiring only one additional cutoff frequency parameter. Integrating low pass filters to the downsampling operations significantly improves the detection performance and achieves comparable results on THUMOS'14, ActivityNet~1.3, and Charades datasets. Experiments demonstrate that anti-aliasing with low pass filters in TAL is advantageous and efficient.
SSD-GAN: Measuring the Realness in the Spatial and Spectral Domains
Dec 15, 2020

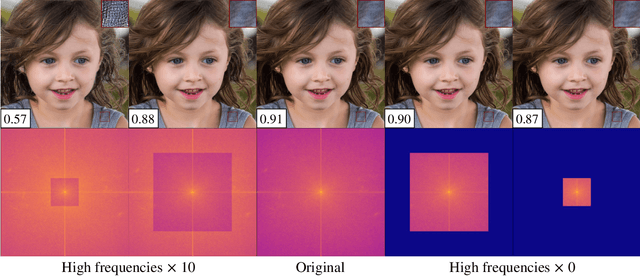

This paper observes that there is an issue of high frequencies missing in the discriminator of standard GAN, and we reveal it stems from downsampling layers employed in the network architecture. This issue makes the generator lack the incentive from the discriminator to learn high-frequency content of data, resulting in a significant spectrum discrepancy between generated images and real images. Since the Fourier transform is a bijective mapping, we argue that reducing this spectrum discrepancy would boost the performance of GANs. To this end, we introduce SSD-GAN, an enhancement of GANs to alleviate the spectral information loss in the discriminator. Specifically, we propose to embed a frequency-aware classifier into the discriminator to measure the realness of the input in both the spatial and spectral domains. With the enhanced discriminator, the generator of SSD-GAN is encouraged to learn high-frequency content of real data and generate exact details. The proposed method is general and can be easily integrated into most existing GANs framework without excessive cost. The effectiveness of SSD-GAN is validated on various network architectures, objective functions, and datasets. Code will be available at https://github.com/cyq373/SSD-GAN.
Toward Zero-Shot Unsupervised Image-to-Image Translation
Jul 28, 2020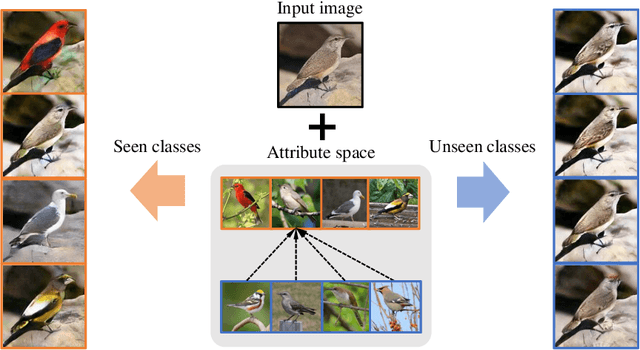
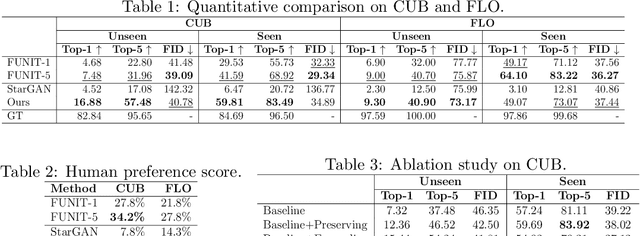
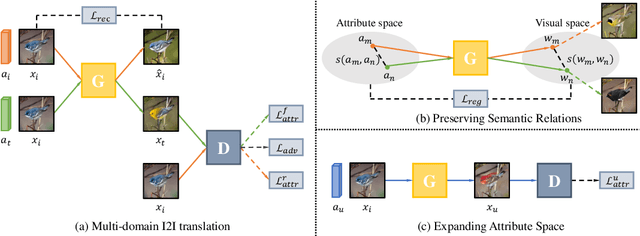

Recent studies have shown remarkable success in unsupervised image-to-image translation. However, if there has no access to enough images in target classes, learning a mapping from source classes to the target classes always suffers from mode collapse, which limits the application of the existing methods. In this work, we propose a zero-shot unsupervised image-to-image translation framework to address this limitation, by associating categories with their side information like attributes. To generalize the translator to previous unseen classes, we introduce two strategies for exploiting the space spanned by the semantic attributes. Specifically, we propose to preserve semantic relations to the visual space and expand attribute space by utilizing attribute vectors of unseen classes, thus encourage the translator to explore the modes of unseen classes. Quantitative and qualitative results on different datasets demonstrate the effectiveness of our proposed approach. Moreover, we demonstrate that our framework can be applied to many tasks, such as zero-shot classification and fashion design.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
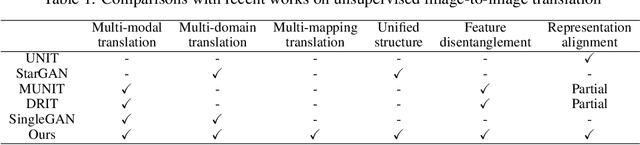


Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.