 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis for Image-to-Image Translation and Style Transfer
Aug 12, 2024



With the development of generative technologies in deep learning, a large number of image-to-image translation and style transfer models have emerged at an explosive rate in recent years. These two technologies have made significant progress and can generate realistic images. However, many communities tend to confuse the two, because both generate the desired image based on the input image and both cover the two definitions of content and style. In fact, there are indeed significant differences between the two, and there is currently a lack of clear explanations to distinguish the two technologies, which is not conducive to the advancement of technology. We hope to serve the entire community by introducing the differences and connections between image-to-image translation and style transfer. The entire discussion process involves the concepts, forms, training modes, evaluation processes, and visualization results of the two technologies. Finally, we conclude that image-to-image translation divides images by domain, and the types of images in the domain are limited, and the scope involved is small, but the conversion ability is strong and can achieve strong semantic changes. Style transfer divides image types by single image, and the scope involved is large, but the transfer ability is limited, and it transfers more texture and color of the image.
Optimizing Illuminant Estimation in Dual-Exposure HDR Imaging
Mar 04, 2024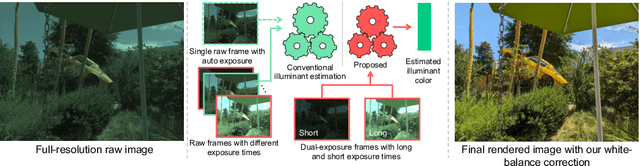
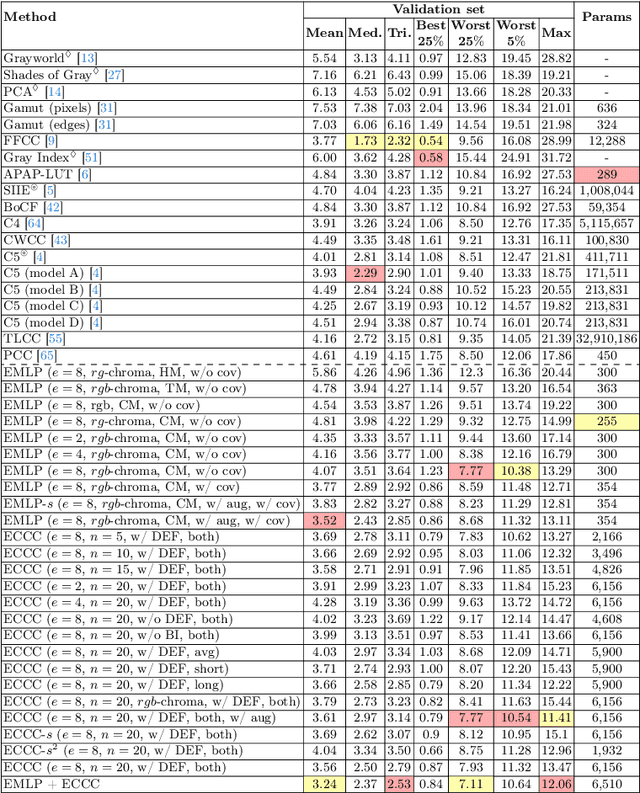
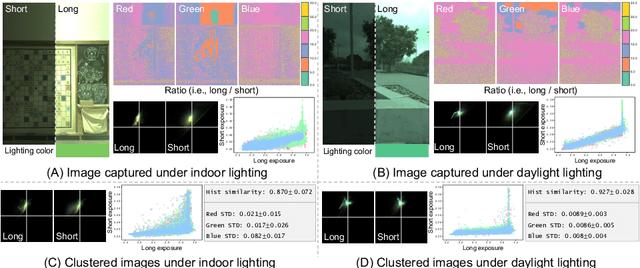
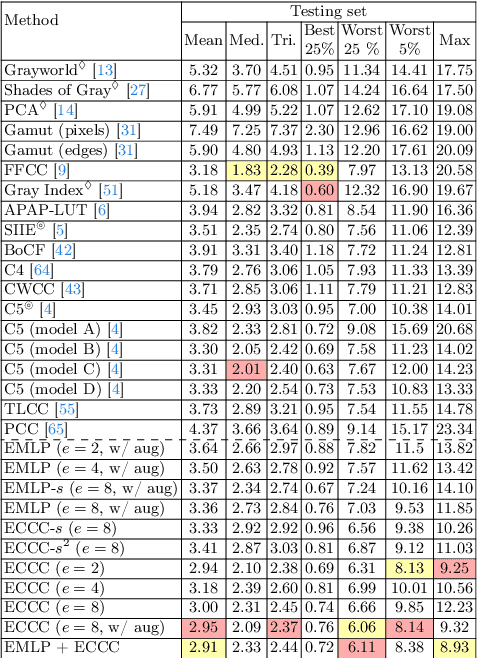
High dynamic range (HDR) imaging involves capturing a series of frames of the same scene, each with different exposure settings, to broaden the dynamic range of light. This can be achieved through burst capturing or using staggered HDR sensors that capture long and short exposures simultaneously in the camera image signal processor (ISP). Within camera ISP pipeline, illuminant estimation is a crucial step aiming to estimate the color of the global illuminant in the scene. This estimation is used in camera ISP white-balance module to remove undesirable color cast in the final image. Despite the multiple frames captured in the HDR pipeline, conventional illuminant estimation methods often rely only on a single frame of the scene. In this paper, we explore leveraging information from frames captured with different exposure times. Specifically, we introduce a simple feature extracted from dual-exposure images to guide illuminant estimators, referred to as the dual-exposure feature (DEF). To validate the efficiency of DEF, we employed two illuminant estimators using the proposed DEF: 1) a multilayer perceptron network (MLP), referred to as exposure-based MLP (EMLP), and 2) a modified version of the convolutional color constancy (CCC) to integrate our DEF, that we call ECCC. Both EMLP and ECCC achieve promising results, in some cases surpassing prior methods that require hundreds of thousands or millions of parameters, with only a few hundred parameters for EMLP and a few thousand parameters for ECCC.
A Risk-aware Planning Framework of UGVs in Off-Road Environment
Feb 04, 2024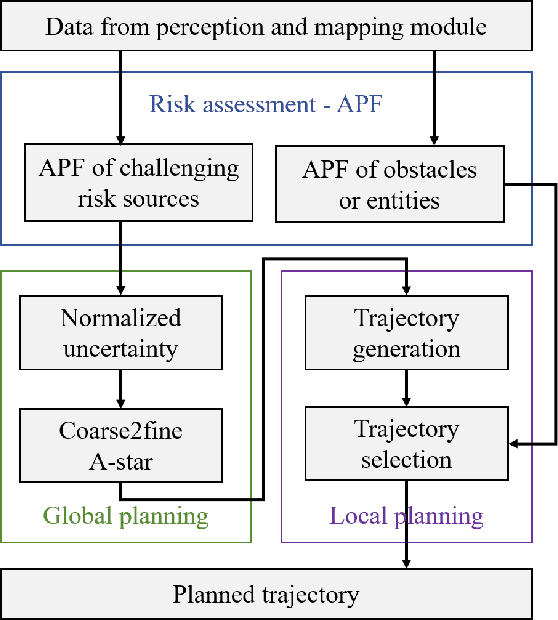
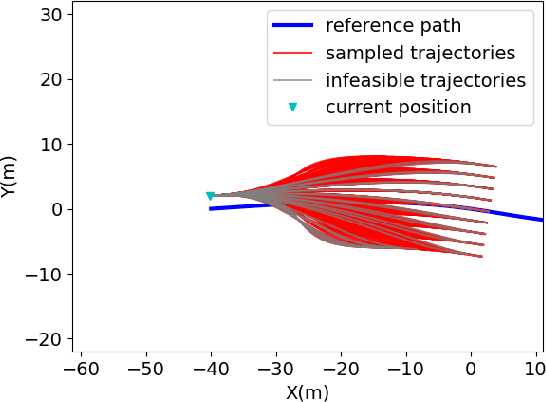
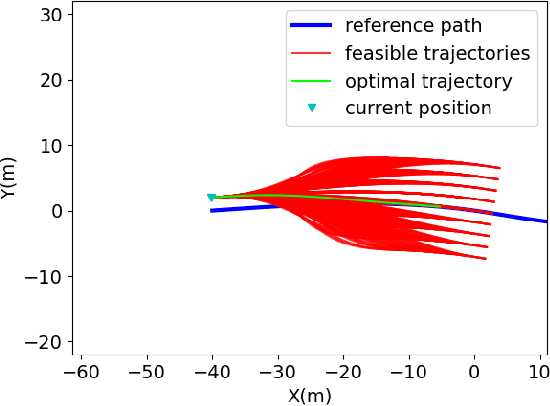
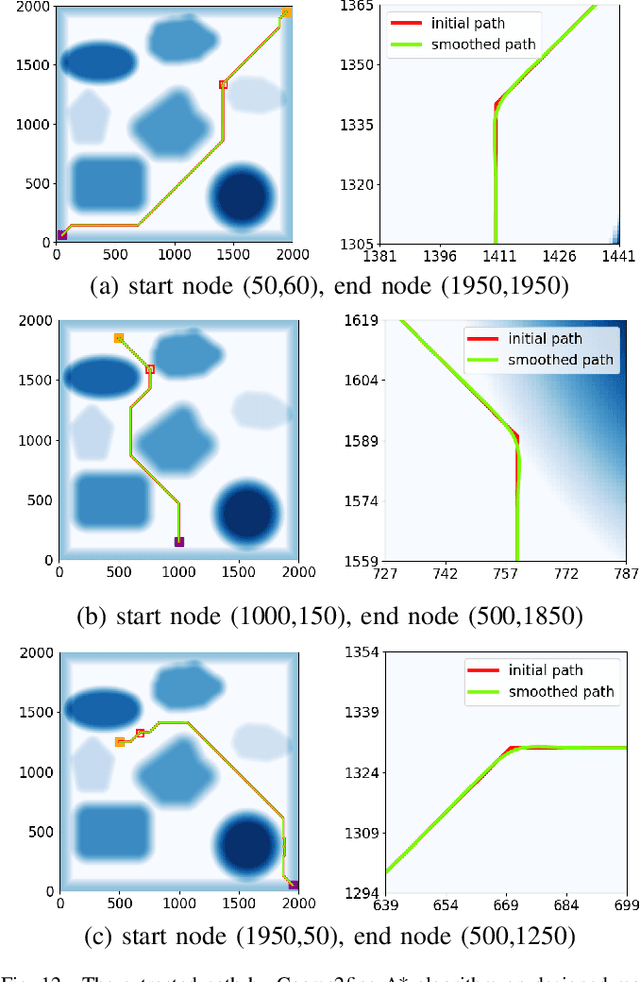
Planning module is an essential component of intelligent vehicle study. In this paper, we address the risk-aware planning problem of UGVs through a global-local planning framework which seamlessly integrates risk assessment methods. In particular, a global planning algorithm named Coarse2fine A* is proposed, which incorporates a potential field approach to enhance the safety of the planning results while ensuring the efficiency of the algorithm. A deterministic sampling method for local planning is leveraged and modified to suit off-road environment. It also integrates a risk assessment model to emphasize the avoidance of local risks. The performance of the algorithm is demonstrated through simulation experiments by comparing it with baseline algorithms, where the results of Coarse2fine A* are shown to be approximately 30% safer than those of the baseline algorithms. The practicality and effectiveness of the proposed planning framework are validated by deploying it on a real-world system consisting of a control center and a practical UGV platform.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020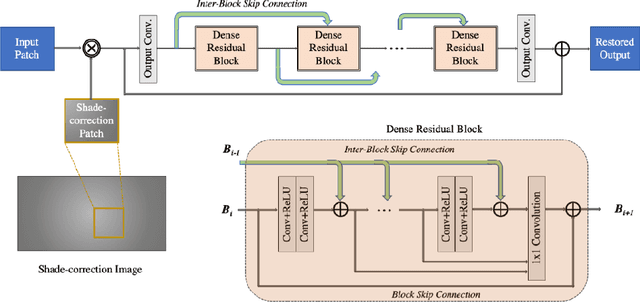
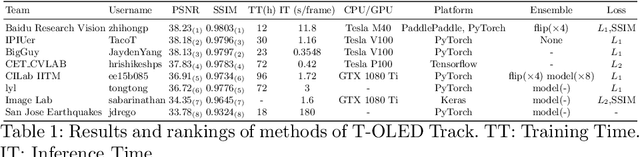
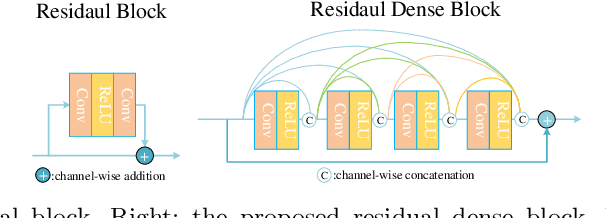
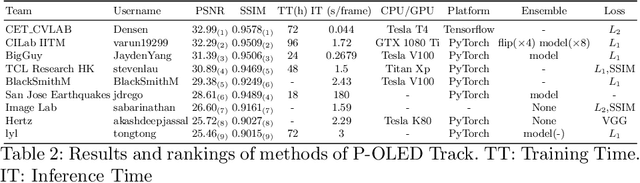
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.