 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelepresence Video Quality Assessment
Jul 20, 2022
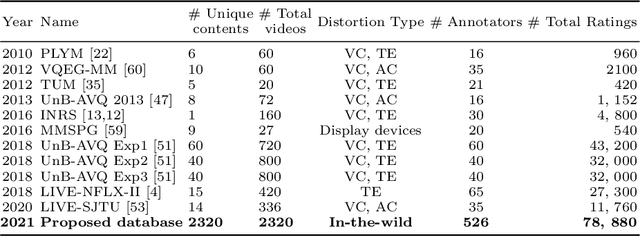

Video conferencing, which includes both video and audio content, has contributed to dramatic increases in Internet traffic, as the COVID-19 pandemic forced millions of people to work and learn from home. Global Internet traffic of video conferencing has dramatically increased Because of this, efficient and accurate video quality tools are needed to monitor and perceptually optimize telepresence traffic streamed via Zoom, Webex, Meet, etc. However, existing models are limited in their prediction capabilities on multi-modal, live streaming telepresence content. Here we address the significant challenges of Telepresence Video Quality Assessment (TVQA) in several ways. First, we mitigated the dearth of subjectively labeled data by collecting ~2k telepresence videos from different countries, on which we crowdsourced ~80k subjective quality labels. Using this new resource, we created a first-of-a-kind online video quality prediction framework for live streaming, using a multi-modal learning framework with separate pathways to compute visual and audio quality predictions. Our all-in-one model is able to provide accurate quality predictions at the patch, frame, clip, and audiovisual levels. Our model achieves state-of-the-art performance on both existing quality databases and our new TVQA database, at a considerably lower computational expense, making it an attractive solution for mobile and embedded systems.
Subjective and Objective Analysis of Streamed Gaming Videos
Mar 24, 2022
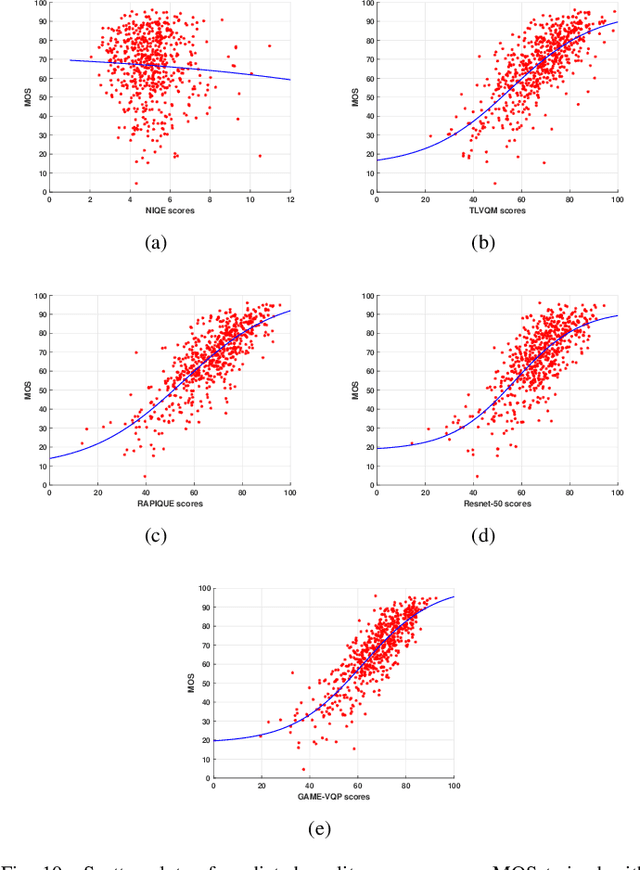
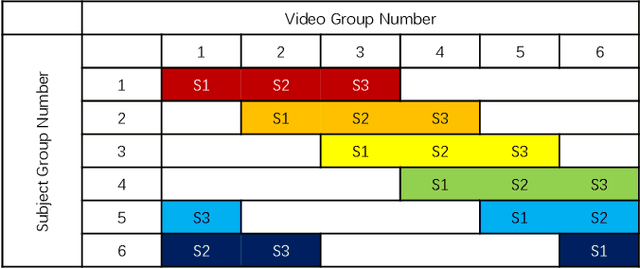
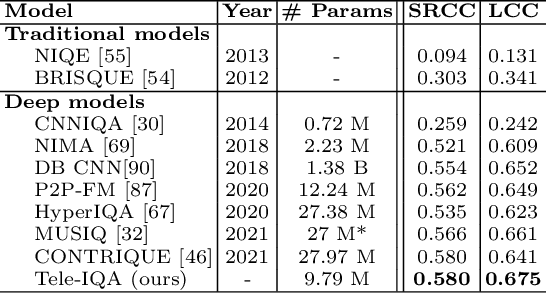
The rising popularity of online User-Generated-Content (UGC) in the form of streamed and shared videos, has hastened the development of perceptual Video Quality Assessment (VQA) models, which can be used to help optimize their delivery. Gaming videos, which are a relatively new type of UGC videos, are created when skilled gamers post videos of their gameplay. These kinds of screenshots of UGC gameplay videos have become extremely popular on major streaming platforms like YouTube and Twitch. Synthetically-generated gaming content presents challenges to existing VQA algorithms, including those based on natural scene/video statistics models. Synthetically generated gaming content presents different statistical behavior than naturalistic videos. A number of studies have been directed towards understanding the perceptual characteristics of professionally generated gaming videos arising in gaming video streaming, online gaming, and cloud gaming. However, little work has been done on understanding the quality of UGC gaming videos, and how it can be characterized and predicted. Towards boosting the progress of gaming video VQA model development, we conducted a comprehensive study of subjective and objective VQA models on UGC gaming videos. To do this, we created a novel UGC gaming video resource, called the LIVE-YouTube Gaming video quality (LIVE-YT-Gaming) database, comprised of 600 real UGC gaming videos. We conducted a subjective human study on this data, yielding 18,600 human quality ratings recorded by 61 human subjects. We also evaluated a number of state-of-the-art (SOTA) VQA models on the new database, including a new one, called GAME-VQP, based on both natural video statistics and CNN-learned features. To help support work in this field, we are making the new LIVE-YT-Gaming Database, publicly available through the link: https://live.ece.utexas.edu/research/LIVE-YT-Gaming/index.html .
Patch-VQ: 'Patching Up' the Video Quality Problem
Nov 27, 2020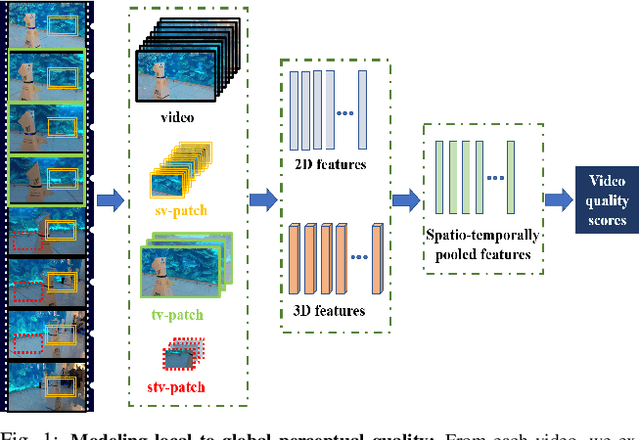
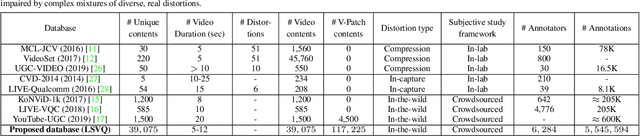


No-reference (NR) perceptual video quality assessment (VQA) is a complex, unsolved, and important problem to social and streaming media applications. Efficient and accurate video quality predictors are needed to monitor and guide the processing of billions of shared, often imperfect, user-generated content (UGC). Unfortunately, current NR models are limited in their prediction capabilities on real-world, "in-the-wild" UGC video data. To advance progress on this problem, we created the largest (by far) subjective video quality dataset, containing 39, 000 realworld distorted videos and 117, 000 space-time localized video patches ('v-patches'), and 5.5M human perceptual quality annotations. Using this, we created two unique NR-VQA models: (a) a local-to-global region-based NR VQA architecture (called PVQ) that learns to predict global video quality and achieves state-of-the-art performance on 3 UGC datasets, and (b) a first-of-a-kind space-time video quality mapping engine (called PVQ Mapper) that helps localize and visualize perceptual distortions in space and time. We will make the new database and prediction models available immediately following the review process.
180-degree Outpainting from a Single Image
Jan 13, 2020



Presenting context images to a viewer's peripheral vision is one of the most effective techniques to enhance immersive visual experiences. However, most images only present a narrow view, since the field-of-view (FoV) of standard cameras is small. To overcome this limitation, we propose a deep learning approach that learns to predict a 180{\deg} panoramic image from a narrow-view image. Specifically, we design a foveated framework that applies different strategies on near-periphery and mid-periphery regions. Two networks are trained separately, and then are employed jointly to sequentially perform narrow-to-90{\deg} generation and 90{\deg}-to-180{\deg} generation. The generated outputs are then fused with their aligned inputs to produce expanded equirectangular images for viewing. Our experimental results show that single-view-to-panoramic image generation using deep learning is both feasible and promising.
From Patches to Pictures (PaQ-2-PiQ): Mapping the Perceptual Space of Picture Quality
Dec 20, 2019
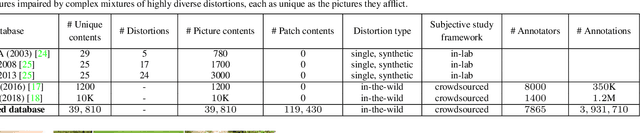


Blind or no-reference (NR) perceptual picture quality prediction is a difficult, unsolved problem of great consequence to the social and streaming media industries that impacts billions of viewers daily. Unfortunately, popular NR prediction models perform poorly on real-world distorted pictures. To advance progress on this problem, we introduce the largest (by far) subjective picture quality database, containing about 40000 real-world distorted pictures and 120000 patches, on which we collected about 4M human judgments of picture quality. Using these picture and patch quality labels, we built deep region-based architectures that learn to produce state-of-the-art global picture quality predictions as well as useful local picture quality maps. Our innovations include picture quality prediction architectures that produce global-to-local inferences as well as local-to-global inferences (via feedback).
Multi-Mapping Image-to-Image Translation with Central Biasing Normalization
Oct 11, 2018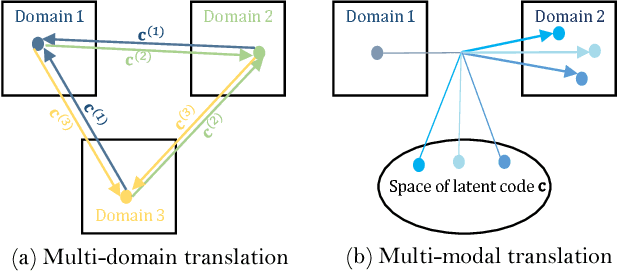
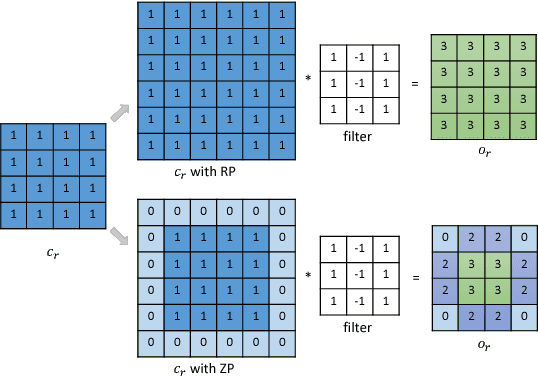
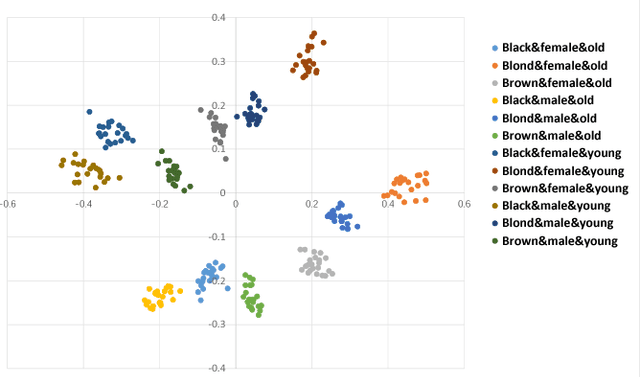

Image-to-image translation is a class of image processing and vision problems that translates an image to a different style or domain. To improve the capacity and performance of one-to-one translation models, multi-mapping image translation have been attempting to extend them for multiple mappings by injecting latent code. Through the analysis of the existing latent code injection models, we find that latent code can determine the target mapping of a generator by controlling the output statistical properties, especially the mean value. However, we find that in some cases the normalization will reduce the consistency of same mapping or the diversity of different mappings. After mathematical analysis, we find the reason behind that is that the distributions of same mapping become inconsistent after batch normalization, and that the effects of latent code are eliminated after instance normalization. To solve these problems, we propose consistency within diversity design criteria for multi-mapping networks. Based on the design criteria, we propose central biasing normalization (CBN) to replace existing latent code injection. CBN can be easily integrated into existing multi-mapping models, significantly reducing model parameters. Experiments show that the results of our method is more stable and diverse than that of existing models. https://github.com/Xiaoming-Yu/cbn .
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
Oct 11, 2018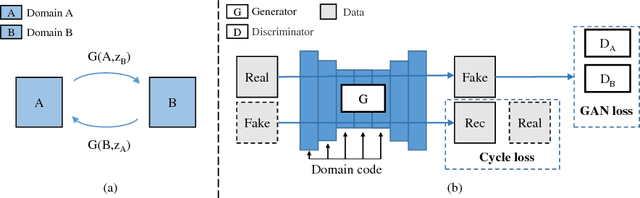
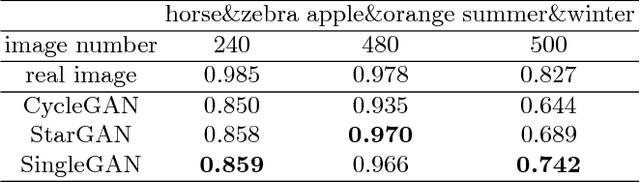
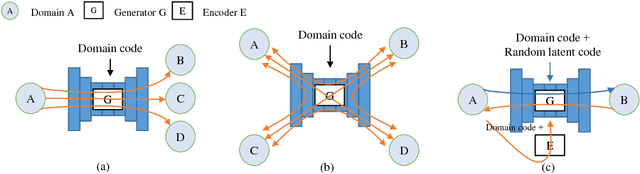
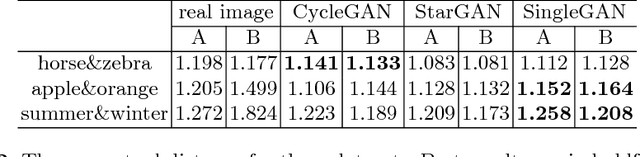
Image translation is a burgeoning field in computer vision where the goal is to learn the mapping between an input image and an output image. However, most recent methods require multiple generators for modeling different domain mappings, which are inefficient and ineffective on some multi-domain image translation tasks. In this paper, we propose a novel method, SingleGAN, to perform multi-domain image-to-image translations with a single generator. We introduce the domain code to explicitly control the different generative tasks and integrate multiple optimization goals to ensure the translation. Experimental results on several unpaired datasets show superior performance of our model in translation between two domains. Besides, we explore variants of SingleGAN for different tasks, including one-to-many domain translation, many-to-many domain translation and one-to-one domain translation with multimodality. The extended experiments show the universality and extensibility of our model.
A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement
Nov 02, 2017
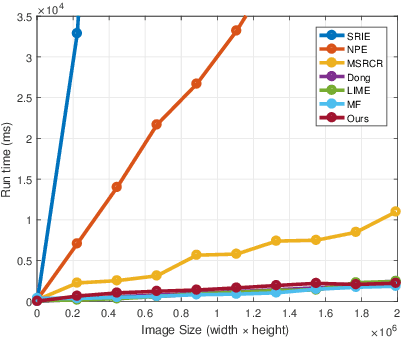

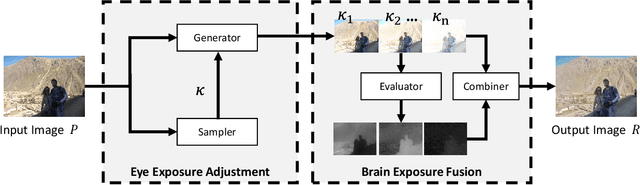
Low-light images are not conducive to human observation and computer vision algorithms due to their low visibility. Although many image enhancement techniques have been proposed to solve this problem, existing methods inevitably introduce contrast under- and over-enhancement. Inspired by human visual system, we design a multi-exposure fusion framework for low-light image enhancement. Based on the framework, we propose a dual-exposure fusion algorithm to provide an accurate contrast and lightness enhancement. Specifically, we first design the weight matrix for image fusion using illumination estimation techniques. Then we introduce our camera response model to synthesize multi-exposure images. Next, we find the best exposure ratio so that the synthetic image is well-exposed in the regions where the original image is under-exposed. Finally, the enhanced result is obtained by fusing the input image and the synthetic image according to the weight matrix. Experiments show that our method can obtain results with less contrast and lightness distortion compared to that of several state-of-the-art methods.
ORGB: Offset Correction in RGB Color Space for Illumination-Robust Image Processing
Aug 03, 2017
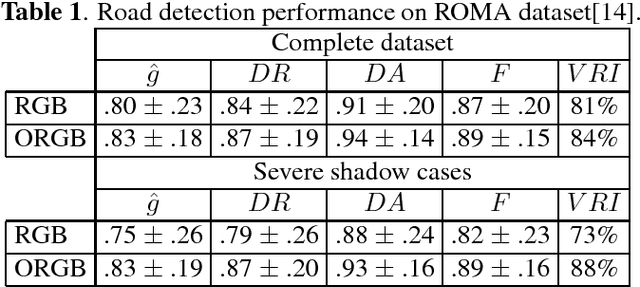
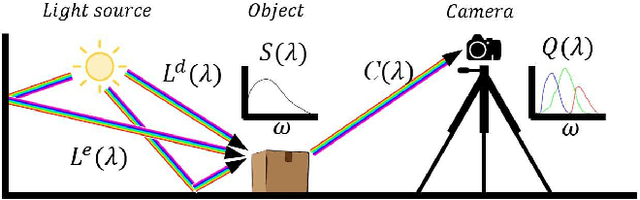
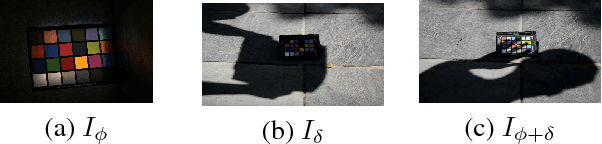
Single materials have colors which form straight lines in RGB space. However, in severe shadow cases, those lines do not intersect the origin, which is inconsistent with the description of most literature. This paper is concerned with the detection and correction of the offset between the intersection and origin. First, we analyze the reason for forming that offset via an optical imaging model. Second, we present a simple and effective way to detect and remove the offset. The resulting images, named ORGB, have almost the same appearance as the original RGB images while are more illumination-robust for color space conversion. Besides, image processing using ORGB instead of RGB is free from the interference of shadows. Finally, the proposed offset correction method is applied to road detection task, improving the performance both in quantitative and qualitative evaluations.
Searching Action Proposals via Spatial Actionness Estimation and Temporal Path Inference and Tracking
Aug 23, 2016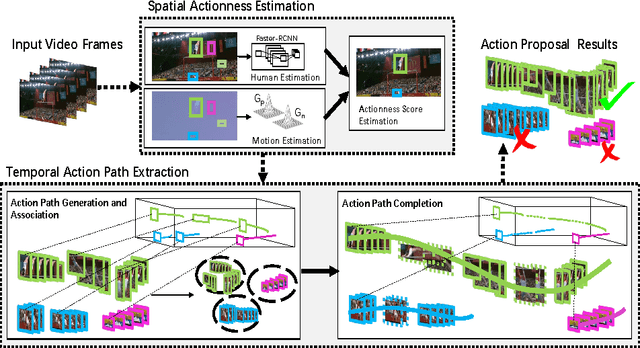
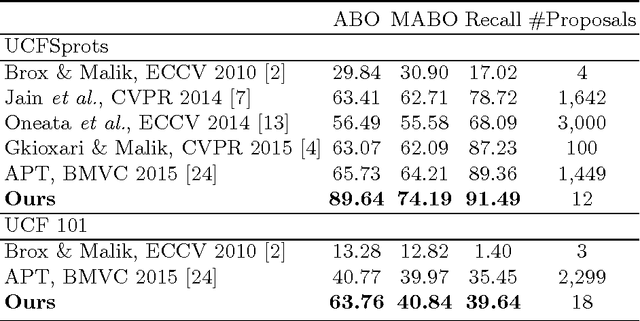

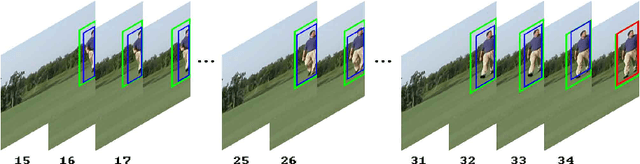
In this paper, we address the problem of searching action proposals in unconstrained video clips. Our approach starts from actionness estimation on frame-level bounding boxes, and then aggregates the bounding boxes belonging to the same actor across frames via linking, associating, tracking to generate spatial-temporal continuous action paths. To achieve the target, a novel actionness estimation method is firstly proposed by utilizing both human appearance and motion cues. Then, the association of the action paths is formulated as a maximum set coverage problem with the results of actionness estimation as a priori. To further promote the performance, we design an improved optimization objective for the problem and provide a greedy search algorithm to solve it. Finally, a tracking-by-detection scheme is designed to further refine the searched action paths. Extensive experiments on two challenging datasets, UCF-Sports and UCF-101, show that the proposed approach advances state-of-the-art proposal generation performance in terms of both accuracy and proposal quantity.