 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimum Methods for Quasi-Orthographic Surface Imaging
May 14, 2023The need for fast, effective and accurate surveys have become increasingly necessary. A major part of the research is supported by photographic surveys which are used for capturing expansive natural surfaces using a wide range of sensors -- visual, infrared, ultrasonic, radio, etc. Because of the unpredictability and fast-varying characteristic of natural surfaces, it is often very difficult to capture and reconstruct them accurately. Moreover, the non-smooth nature results in the occlusion of major areas when a small number of captures are used for reconstruction, resulting in loss of important and maybe significant information or surface features. In a perfect orthographic reconstruction, images must be captured normal to each point on the surface which is practically implausible. This thesis aims at proposing several algorithms for deciding optimal capture points, given a surface, such that the optimal captures can be used for an approximate orthographic reconstruction. An approximate orthographic capture has been attributed to a small field of view and a closed form relationship has been derived for evaluating local orthographic capture region which varies depending on the point of capture on the surface. Based on the formula to calculate approximate local orthographic regions, several algorithms have been developed using non-convex optimization techniques for covering the entire surface with minimum number of such capture points. The algorithms have been compared on the basis of accuracy and computational complexity and parameters have been tuned depending on the nature of the surface. A separate algorithm has been proposed to identify such capture points empirically depending on the local surface-curvatures. Given these algorithms, users can make informed choices regarding which to adopt in their application as per their requirements.
Analyzing Compression Techniques for Computer Vision
May 14, 2023Compressing deep networks is highly desirable for practical use-cases in computer vision applications. Several techniques have been explored in the literature, and research has been done in finding efficient strategies for combining them. For this project, we aimed to explore three different basic compression techniques - knowledge distillation, pruning, and quantization for small-scale recognition tasks. Along with the basic methods, we also test the efficacy of combining them in a sequential manner. We analyze them using MNIST and CIFAR-10 datasets and present the results along with few observations inferred from them.
Helping Visually Impaired People Take Better Quality Pictures
May 14, 2023Perception-based image analysis technologies can be used to help visually impaired people take better quality pictures by providing automated guidance, thereby empowering them to interact more confidently on social media. The photographs taken by visually impaired users often suffer from one or both of two kinds of quality issues: technical quality (distortions), and semantic quality, such as framing and aesthetic composition. Here we develop tools to help them minimize occurrences of common technical distortions, such as blur, poor exposure, and noise. We do not address the complementary problems of semantic quality, leaving that aspect for future work. The problem of assessing and providing actionable feedback on the technical quality of pictures captured by visually impaired users is hard enough, owing to the severe, commingled distortions that often occur. To advance progress on the problem of analyzing and measuring the technical quality of visually impaired user-generated content (VI-UGC), we built a very large and unique subjective image quality and distortion dataset. This new perceptual resource, which we call the LIVE-Meta VI-UGC Database, contains $40$K real-world distorted VI-UGC images and $40$K patches, on which we recorded $2.7$M human perceptual quality judgments and $2.7$M distortion labels. Using this psychometric resource we also created an automatic blind picture quality and distortion predictor that learns local-to-global spatial quality relationships, achieving state-of-the-art prediction performance on VI-UGC pictures, significantly outperforming existing picture quality models on this unique class of distorted picture data. We also created a prototype feedback system that helps to guide users to mitigate quality issues and take better quality pictures, by creating a multi-task learning framework.
Improving Defensive Distillation using Teacher Assistant
May 14, 2023Adversarial attacks pose a significant threat to the security and safety of deep neural networks being applied to modern applications. More specifically, in computer vision-based tasks, experts can use the knowledge of model architecture to create adversarial samples imperceptible to the human eye. These attacks can lead to security problems in popular applications such as self-driving cars, face recognition, etc. Hence, building networks which are robust to such attacks is highly desirable and essential. Among the various methods present in literature, defensive distillation has shown promise in recent years. Using knowledge distillation, researchers have been able to create models robust against some of those attacks. However, more attacks have been developed exposing weakness in defensive distillation. In this project, we derive inspiration from teacher assistant knowledge distillation and propose that introducing an assistant network can improve the robustness of the distilled model. Through a series of experiments, we evaluate the distilled models for different distillation temperatures in terms of accuracy, sensitivity, and robustness. Our experiments demonstrate that the proposed hypothesis can improve robustness in most cases. Additionally, we show that multi-step distillation can further improve robustness with very little impact on model accuracy.
Modelling Quasi-Orthographic Captures for Surface Imaging
May 14, 2023Surveillance and surveying are two important applications of empirical research. A major part of terrain modelling is supported by photographic surveys which are used for capturing expansive natural surfaces using a wide range of sensors -- visual, infrared, ultrasonic, radio, etc. A natural surface is non-smooth, unpredictable and fast-varying, and it is difficult to capture all features and reconstruct them accurately. An orthographic image of a surface provides a detailed holistic view capturing its relevant features. In a perfect orthographic reconstruction, images must be captured normal to each point on the surface which is practically impossible. In this paper, a detailed analysis of the constraints on imaging distance is also provided. A novel method is formulated to determine an approximate orthographic region on a surface surrounding the point of focus and additionally, some methods for approximating the orthographic boundary for faster computation is also proposed. The approximation methods have been compared in terms of computational efficiency and accuracy.
Patch-VQ: 'Patching Up' the Video Quality Problem
Nov 27, 2020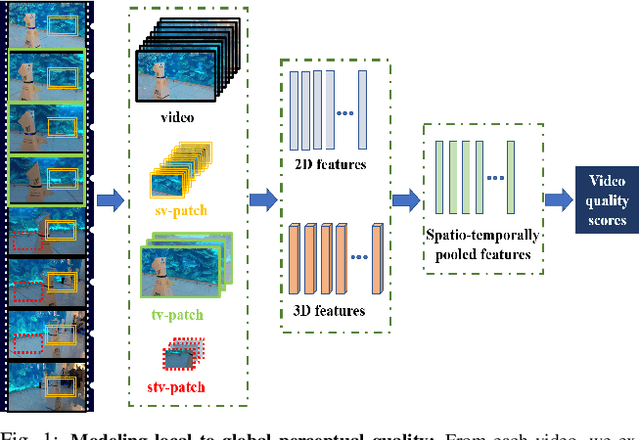
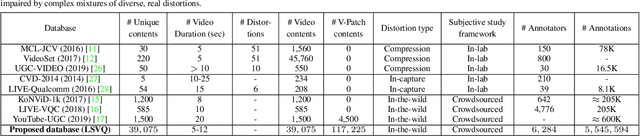


No-reference (NR) perceptual video quality assessment (VQA) is a complex, unsolved, and important problem to social and streaming media applications. Efficient and accurate video quality predictors are needed to monitor and guide the processing of billions of shared, often imperfect, user-generated content (UGC). Unfortunately, current NR models are limited in their prediction capabilities on real-world, "in-the-wild" UGC video data. To advance progress on this problem, we created the largest (by far) subjective video quality dataset, containing 39, 000 realworld distorted videos and 117, 000 space-time localized video patches ('v-patches'), and 5.5M human perceptual quality annotations. Using this, we created two unique NR-VQA models: (a) a local-to-global region-based NR VQA architecture (called PVQ) that learns to predict global video quality and achieves state-of-the-art performance on 3 UGC datasets, and (b) a first-of-a-kind space-time video quality mapping engine (called PVQ Mapper) that helps localize and visualize perceptual distortions in space and time. We will make the new database and prediction models available immediately following the review process.