 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChorus II: Cross-Request Sparsity Reuse for Efficient Image-to-Video Generation
Jun 23, 2026Serving diffusion models for image-to-video generation is computationally expensive, posing significant challenges for large-scale deployment. Real I2V workloads often contain similar requests, such as repeated effect templates, related subjects, and recurring shot layouts. Existing cross-request acceleration methods mainly exploit this redundancy through feature reuse. We observe that similar I2V requests also share highly consistent sparse attention patterns, enabling historical sparse masks to serve as request-conditioned priors with almost no online mask-prediction overhead. We propose a cross-request reuse framework centered on \textbf{sparsity reuse}, with \textbf{feature reuse} as an optional extension safeguarded by a lightweight \textbf{guidance enhancement}. Our sparsity reuse is implemented as shared sparse mask reuse, which reuses high-quality sparse masks from similar historical requests to avoid per-request online mask prediction. Optional feature reuse applies downsampled computation to highly redundant spatiotemporal regions, mitigating boundary artifacts while preserving efficiency gains. Guidance enhancement reinforces image/text conditioning after reuse, mitigating semantic drift and condition-adherence issues. Experiments show that default sparsity reuse configuration preserves generation quality with a \textbf{2.16$\times$} speedup.
OmniHuman: A Large-scale Dataset and Benchmark for Human-Centric Video Generation
Apr 20, 2026Recent advancements in audio-video joint generation models have demonstrated impressive capabilities in content creation. However, generating high-fidelity human-centric videos in complex, real-world physical scenes remains a significant challenge. We identify that the root cause lies in the structural deficiencies of existing datasets across three dimensions: limited global scene and camera diversity, sparse interaction modeling (both person-person and person-object), and insufficient individual attribute alignment. To bridge these gaps, we present OmniHuman, a large-scale, multi-scene dataset designed for fine-grained human modeling. OmniHuman provides a hierarchical annotation covering video-level scenes, frame-level interactions, and individual-level attributes. To facilitate this, we develop a fully automated pipeline for high-quality data collection and multi-modal annotation. Complementary to the dataset, we establish the OmniHuman Benchmark (OHBench), a three-level evaluation system that provides a scientific diagnosis for human-centric audio-video synthesis. Crucially, OHBench introduces metrics that are highly consistent with human perception, filling the gaps in existing benchmarks by providing a comprehensive diagnosis across global scenes, relational interactions, and individual attributes.
PDNet: Prior-model Guided Depth-enhanced Network for Salient Object Detection
Oct 13, 2018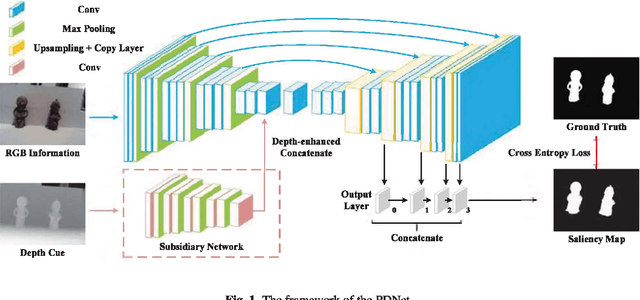
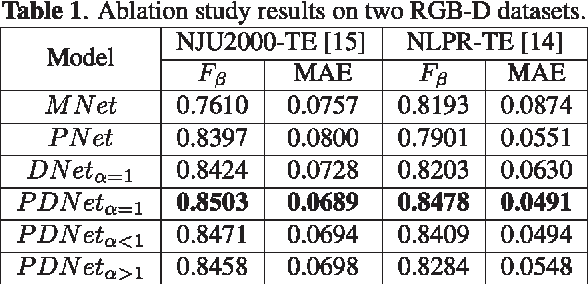

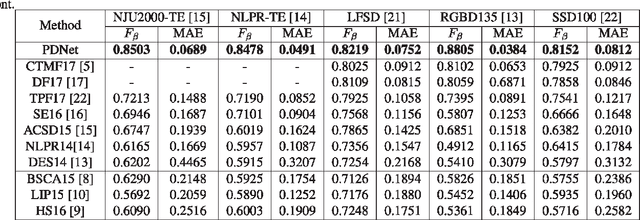
Fully convolutional neural networks (FCNs) have shown outstanding performance in many computer vision tasks including salient object detection. However, there still remains two issues needed to be addressed in deep learning based saliency detection. One is the lack of tremendous amount of annotated data to train a network. The other is the lack of robustness for extracting salient objects in images containing complex scenes. In this paper, we present a new architecture$ - $PDNet, a robust prior-model guided depth-enhanced network for RGB-D salient object detection. In contrast to existing works, in which RGB-D values of image pixels are fed directly to a network, the proposed architecture is composed of a master network for processing RGB values, and a sub-network making full use of depth cues and incorporate depth-based features into the master network. To overcome the limited size of the labeled RGB-D dataset for training, we employ a large conventional RGB dataset to pre-train the master network, which proves to contribute largely to the final accuracy. Extensive evaluations over five benchmark datasets demonstrate that our proposed method performs favorably against the state-of-the-art approaches.
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
Oct 11, 2018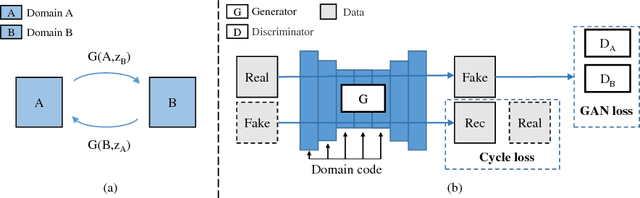
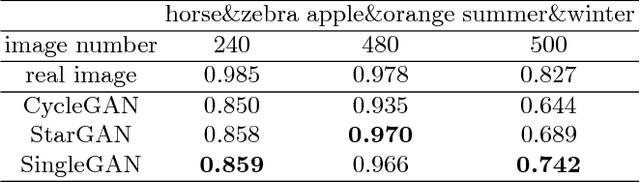
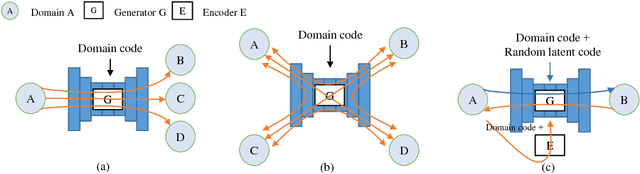
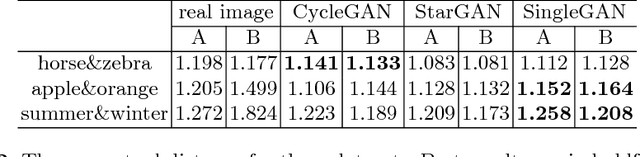
Image translation is a burgeoning field in computer vision where the goal is to learn the mapping between an input image and an output image. However, most recent methods require multiple generators for modeling different domain mappings, which are inefficient and ineffective on some multi-domain image translation tasks. In this paper, we propose a novel method, SingleGAN, to perform multi-domain image-to-image translations with a single generator. We introduce the domain code to explicitly control the different generative tasks and integrate multiple optimization goals to ensure the translation. Experimental results on several unpaired datasets show superior performance of our model in translation between two domains. Besides, we explore variants of SingleGAN for different tasks, including one-to-many domain translation, many-to-many domain translation and one-to-one domain translation with multimodality. The extended experiments show the universality and extensibility of our model.