 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep AutoEncoder-based Lossy Geometry Compression for Point Clouds
Apr 18, 2019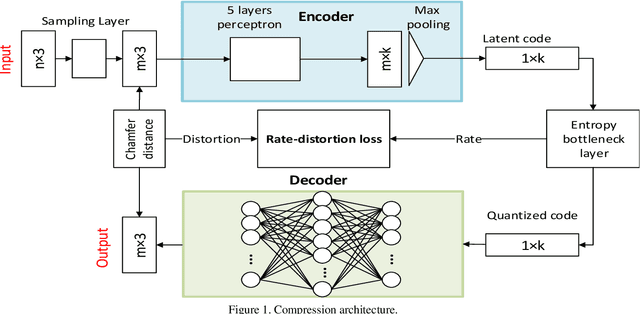
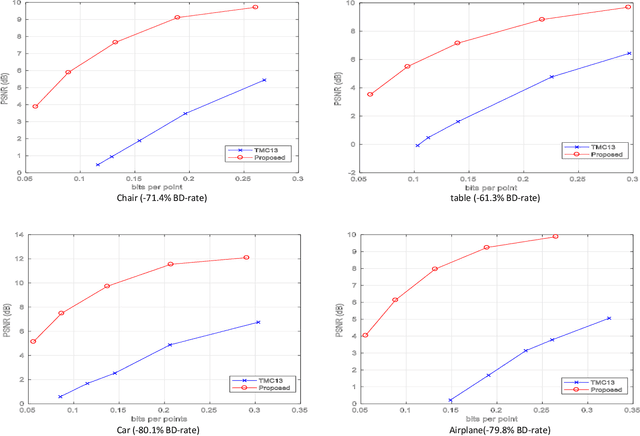

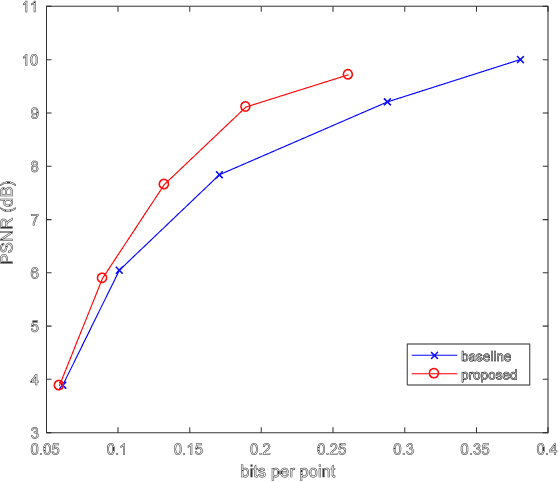
Point cloud is a fundamental 3D representation which is widely used in real world applications such as autonomous driving. As a newly-developed media format which is characterized by complexity and irregularity, point cloud creates a need for compression algorithms which are more flexible than existing codecs. Recently, autoencoders(AEs) have shown their effectiveness in many visual analysis tasks as well as image compression, which inspires us to employ it in point cloud compression. In this paper, we propose a general autoencoder-based architecture for lossy geometry point cloud compression. To the best of our knowledge, it is the first autoencoder-based geometry compression codec that directly takes point clouds as input rather than voxel grids or collections of images. Compared with handcrafted codecs, this approach adapts much more quickly to previously unseen media contents and media formats, meanwhile achieving competitive performance. Our architecture consists of a pointnet-based encoder, a uniform quantizer, an entropy estimation block and a nonlinear synthesis transformation module. In lossy geometry compression of point cloud, results show that the proposed method outperforms the test model for categories 1 and 3 (TMC13) published by MPEG-3DG group on the 125th meeting, and on average a 73.15\% BD-rate gain is achieved.
PDNet: Prior-model Guided Depth-enhanced Network for Salient Object Detection
Oct 13, 2018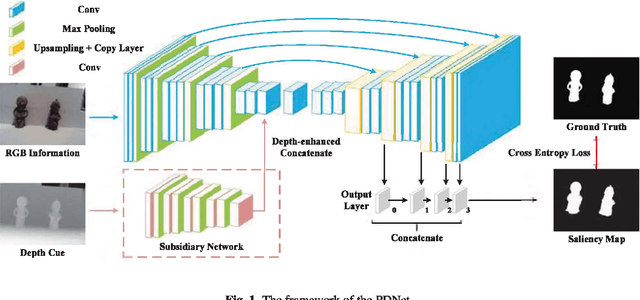
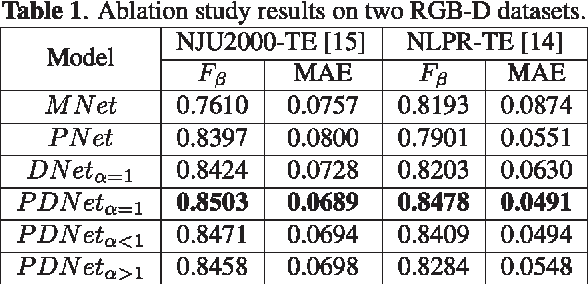

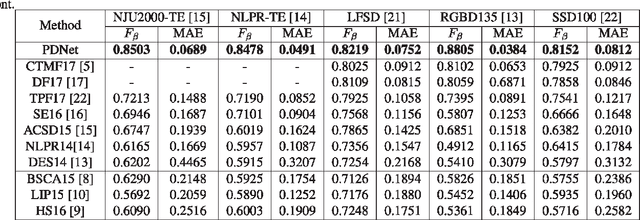
Fully convolutional neural networks (FCNs) have shown outstanding performance in many computer vision tasks including salient object detection. However, there still remains two issues needed to be addressed in deep learning based saliency detection. One is the lack of tremendous amount of annotated data to train a network. The other is the lack of robustness for extracting salient objects in images containing complex scenes. In this paper, we present a new architecture$ - $PDNet, a robust prior-model guided depth-enhanced network for RGB-D salient object detection. In contrast to existing works, in which RGB-D values of image pixels are fed directly to a network, the proposed architecture is composed of a master network for processing RGB values, and a sub-network making full use of depth cues and incorporate depth-based features into the master network. To overcome the limited size of the labeled RGB-D dataset for training, we employ a large conventional RGB dataset to pre-train the master network, which proves to contribute largely to the final accuracy. Extensive evaluations over five benchmark datasets demonstrate that our proposed method performs favorably against the state-of-the-art approaches.