 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
FSC-loss: A Frequency-domain Structure Consistency Learning Approach for Signal Data Recovery and Reconstruction
Jan 08, 2025



A core challenge for signal data recovery is to model the distribution of signal matrix (SM) data based on measured low-quality data in biomedical engineering of magnetic particle imaging (MPI). For acquiring the high-resolution (high-quality) SM, the number of meticulous measurements at numerous positions in the field-of-view proves time-consuming (measurement of a 37x37x37 SM takes about 32 hours). To improve reconstructed signal quality and shorten SM measurement time, existing methods explore to generating high-resolution SM based on time-saving measured low-resolution SM (a 9x9x9 SM just takes about 0.5 hours). However, previous methods show poor performance for high-frequency signal recovery in SM. To achieve a high-resolution SM recovery and shorten its acquisition time, we propose a frequency-domain structure consistency loss function and data component embedding strategy to model global and local structural information of SM. We adopt a transformer-based network to evaluate this function and the strategy. We evaluate our methods and state-of-the-art (SOTA) methods on the two simulation datasets and four public measured SMs in Open MPI Data. The results show that our method outperforms the SOTA methods in high-frequency structural signal recovery. Additionally, our method can recover a high-resolution SM with clear high-frequency structure based on a down-sampling factor of 16 less than 15 seconds, which accelerates the acquisition time over 60 times faster than the measurement-based HR SM with the minimum error (nRMSE=0.041). Moreover, our method is applied in our three in-house MPI systems, and boost their performance for signal reconstruction.
Revisiting the Robust Generalization of Adversarial Prompt Tuning
May 18, 2024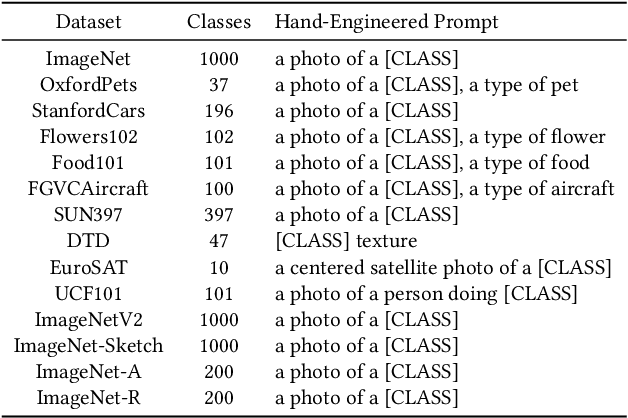
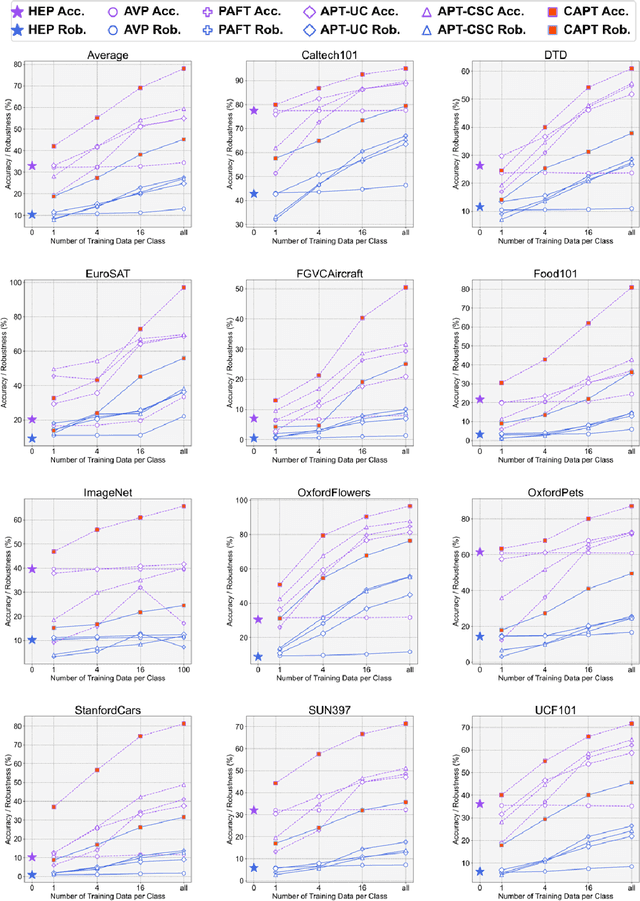
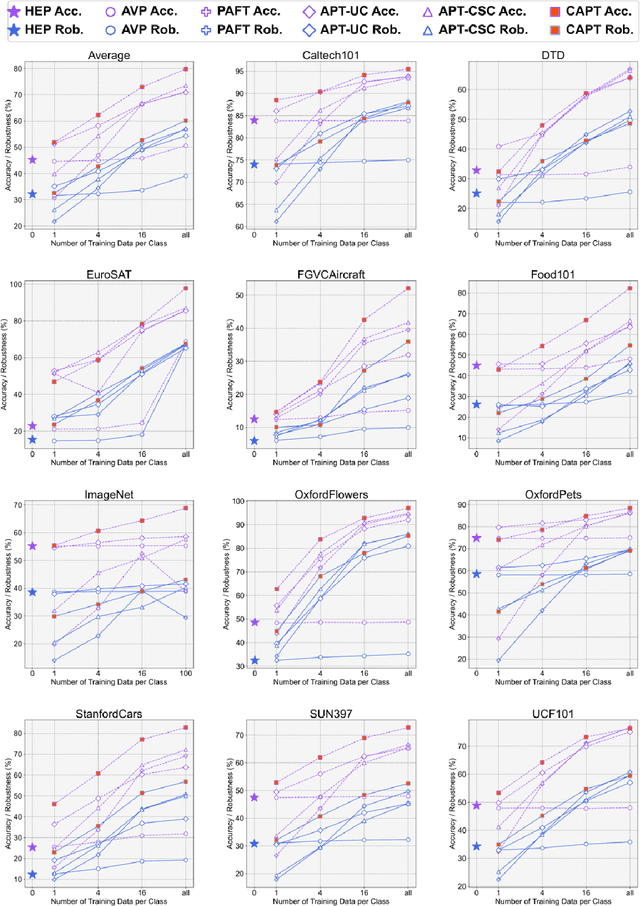
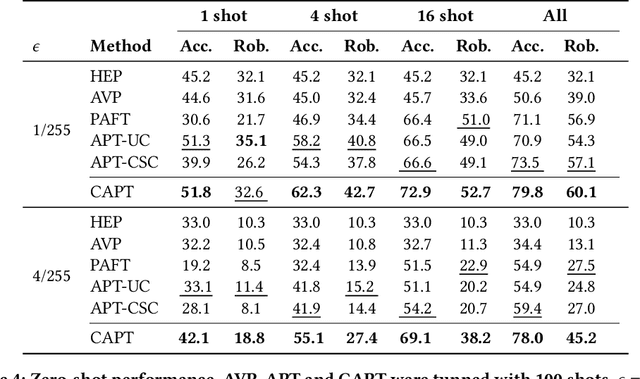
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
TripleSurv: Triplet Time-adaptive Coordinate Loss for Survival Analysis
Jan 05, 2024A core challenge in survival analysis is to model the distribution of censored time-to-event data, where the event of interest may be a death, failure, or occurrence of a specific event. Previous studies have showed that ranking and maximum likelihood estimation (MLE)loss functions are widely-used for survival analysis. However, ranking loss only focus on the ranking of survival time and does not consider potential effect of samples for exact survival time values. Furthermore, the MLE is unbounded and easily subject to outliers (e.g., censored data), which may cause poor performance of modeling. To handle the complexities of learning process and exploit valuable survival time values, we propose a time-adaptive coordinate loss function, TripleSurv, to achieve adaptive adjustments by introducing the differences in the survival time between sample pairs into the ranking, which can encourage the model to quantitatively rank relative risk of pairs, ultimately enhancing the accuracy of predictions. Most importantly, the TripleSurv is proficient in quantifying the relative risk between samples by ranking ordering of pairs, and consider the time interval as a trade-off to calibrate the robustness of model over sample distribution. Our TripleSurv is evaluated on three real-world survival datasets and a public synthetic dataset. The results show that our method outperforms the state-of-the-art methods and exhibits good model performance and robustness on modeling various sophisticated data distributions with different censor rates. Our code will be available upon acceptance.
Benefit from public unlabeled data: A Frangi filtering-based pretraining network for 3D cerebrovascular segmentation
Dec 23, 2023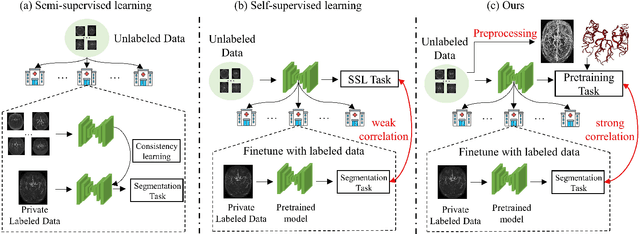
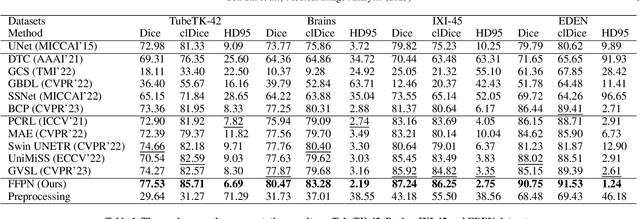
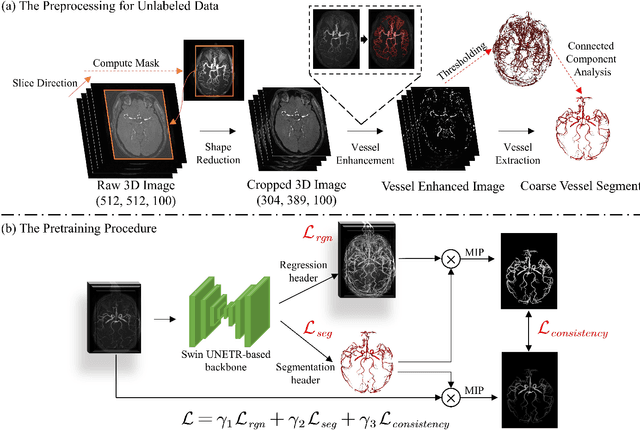
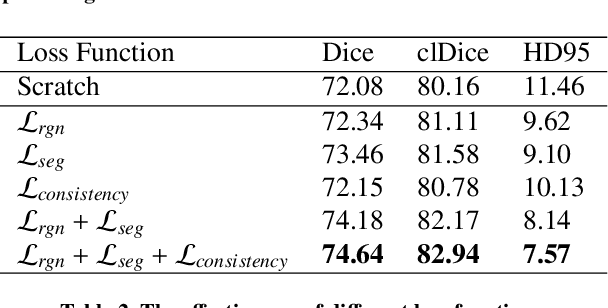
The precise cerebrovascular segmentation in time-of-flight magnetic resonance angiography (TOF-MRA) data is crucial for clinically computer-aided diagnosis. However, the sparse distribution of cerebrovascular structures in TOF-MRA results in an exceedingly high cost for manual data labeling. The use of unlabeled TOF-MRA data holds the potential to enhance model performance significantly. In this study, we construct the largest preprocessed unlabeled TOF-MRA datasets (1510 subjects) to date. We also provide three additional labeled datasets totaling 113 subjects. Furthermore, we propose a simple yet effective pertraining strategy based on Frangi filtering, known for enhancing vessel-like structures, to fully leverage the unlabeled data for 3D cerebrovascular segmentation. Specifically, we develop a Frangi filtering-based preprocessing workflow to handle the large-scale unlabeled dataset, and a multi-task pretraining strategy is proposed to effectively utilize the preprocessed data. By employing this approach, we maximize the knowledge gained from the unlabeled data. The pretrained model is evaluated on four cerebrovascular segmentation datasets. The results have demonstrated the superior performance of our model, with an improvement of approximately 3\% compared to state-of-the-art semi- and self-supervised methods. Furthermore, the ablation studies also demonstrate the generalizability and effectiveness of the pretraining method regarding the backbone structures. The code and data have been open source at: \url{https://github.com/shigen-StoneRoot/FFPN}.