 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Optimal Testing of Discrete Distributions with High Probability
Sep 14, 2020We study the problem of testing discrete distributions with a focus on the high probability regime. Specifically, given samples from one or more discrete distributions, a property $\mathcal{P}$, and parameters $0< \epsilon, \delta <1$, we want to distinguish {\em with probability at least $1-\delta$} whether these distributions satisfy $\mathcal{P}$ or are $\epsilon$-far from $\mathcal{P}$ in total variation distance. Most prior work in distribution testing studied the constant confidence case (corresponding to $\delta = \Omega(1)$), and provided sample-optimal testers for a range of properties. While one can always boost the confidence probability of any such tester by black-box amplification, this generic boosting method typically leads to sub-optimal sample bounds. Here we study the following broad question: For a given property $\mathcal{P}$, can we {\em characterize} the sample complexity of testing $\mathcal{P}$ as a function of all relevant problem parameters, including the error probability $\delta$? Prior to this work, uniformity testing was the only statistical task whose sample complexity had been characterized in this setting. As our main results, we provide the first algorithms for closeness and independence testing that are sample-optimal, within constant factors, as a function of all relevant parameters. We also show matching information-theoretic lower bounds on the sample complexity of these problems. Our techniques naturally extend to give optimal testers for related problems. To illustrate the generality of our methods, we give optimal algorithms for testing collections of distributions and testing closeness with unequal sized samples.
The Hessian Penalty: A Weak Prior for Unsupervised Disentanglement
Aug 24, 2020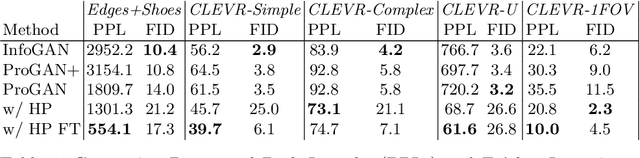

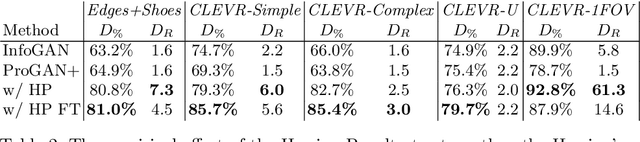

Existing disentanglement methods for deep generative models rely on hand-picked priors and complex encoder-based architectures. In this paper, we propose the Hessian Penalty, a simple regularization term that encourages the Hessian of a generative model with respect to its input to be diagonal. We introduce a model-agnostic, unbiased stochastic approximation of this term based on Hutchinson's estimator to compute it efficiently during training. Our method can be applied to a wide range of deep generators with just a few lines of code. We show that training with the Hessian Penalty often causes axis-aligned disentanglement to emerge in latent space when applied to ProGAN on several datasets. Additionally, we use our regularization term to identify interpretable directions in BigGAN's latent space in an unsupervised fashion. Finally, we provide empirical evidence that the Hessian Penalty encourages substantial shrinkage when applied to over-parameterized latent spaces.
Towards Testing Monotonicity of Distributions Over General Posets
Jul 06, 2019In this work, we consider the sample complexity required for testing the monotonicity of distributions over partial orders. A distribution $p$ over a poset is monotone if, for any pair of domain elements $x$ and $y$ such that $x \preceq y$, $p(x) \leq p(y)$. To understand the sample complexity of this problem, we introduce a new property called bigness over a finite domain, where the distribution is $T$-big if the minimum probability for any domain element is at least $T$. We establish a lower bound of $\Omega(n/\log n)$ for testing bigness of distributions on domains of size $n$. We then build on these lower bounds to give $\Omega(n/\log{n})$ lower bounds for testing monotonicity over a matching poset of size $n$ and significantly improved lower bounds over the hypercube poset. We give sublinear sample complexity bounds for testing bigness and for testing monotonicity over the matching poset. We then give a number of tools for analyzing upper bounds on the sample complexity of the monotonicity testing problem.
On the Limitations of First-Order Approximation in GAN Dynamics
Jun 03, 2018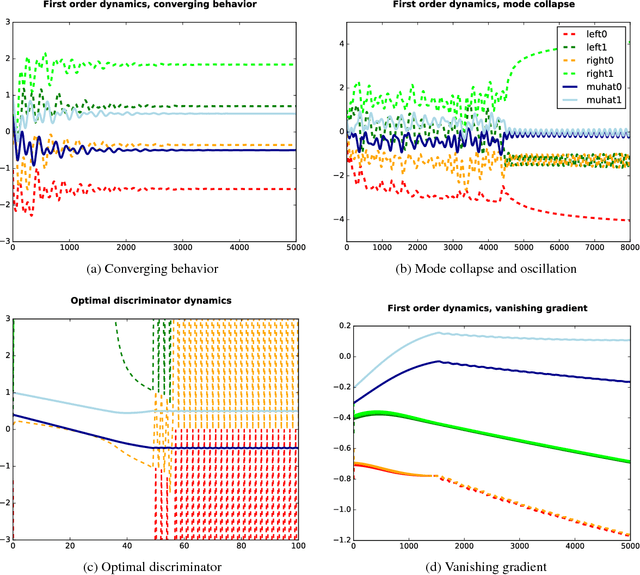
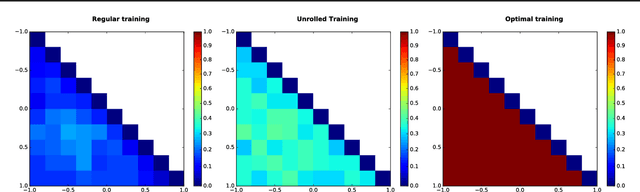
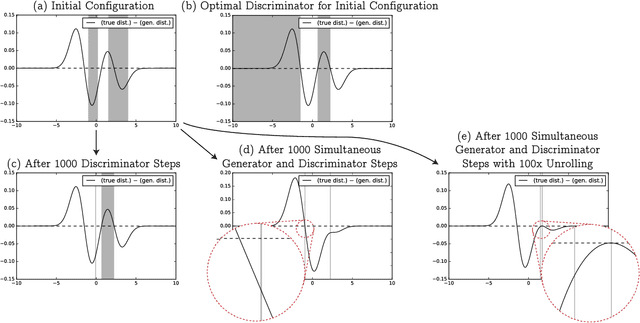
While Generative Adversarial Networks (GANs) have demonstrated promising performance on multiple vision tasks, their learning dynamics are not yet well understood, both in theory and in practice. To address this issue, we study GAN dynamics in a simple yet rich parametric model that exhibits several of the common problematic convergence behaviors such as vanishing gradients, mode collapse, and diverging or oscillatory behavior. In spite of the non-convex nature of our model, we are able to perform a rigorous theoretical analysis of its convergence behavior. Our analysis reveals an interesting dichotomy: a GAN with an optimal discriminator provably converges, while first order approximations of the discriminator steps lead to unstable GAN dynamics and mode collapse. Our result suggests that using first order discriminator steps (the de-facto standard in most existing GAN setups) might be one of the factors that makes GAN training challenging in practice.
Testing Identity of Multidimensional Histograms
Apr 10, 2018

We investigate the problem of identity testing for multidimensional histogram distributions. A distribution $p: D \rightarrow \mathbb{R}_+$, where $D \subseteq \mathbb{R}^d$, is called a {$k$-histogram} if there exists a partition of the domain into $k$ axis-aligned rectangles such that $p$ is constant within each such rectangle. Histograms are one of the most fundamental non-parametric families of distributions and have been extensively studied in computer science and statistics. We give the first identity tester for this problem with {\em sub-learning} sample complexity in any fixed dimension and a nearly-matching sample complexity lower bound. More specifically, let $q$ be an unknown $d$-dimensional $k$-histogram and $p$ be an explicitly given $k$-histogram. We want to correctly distinguish, with probability at least $2/3$, between the case that $p = q$ versus $\|p-q\|_1 \geq \epsilon$. We design a computationally efficient algorithm for this hypothesis testing problem with sample complexity $O((\sqrt{k}/\epsilon^2) \log^{O(d)}(k/\epsilon))$. Our algorithm is robust to model misspecification, i.e., succeeds even if $q$ is only promised to be {\em close} to a $k$-histogram. Moreover, for $k = 2^{\Omega(d)}$, we show a nearly-matching sample complexity lower bound of $\Omega((\sqrt{k}/\epsilon^2) (\log(k/\epsilon)/d)^{\Omega(d)})$ when $d\geq 2$. Prior to our work, the sample complexity of the $d=1$ case was well-understood, but no algorithm with sub-learning sample complexity was known, even for $d=2$. Our new upper and lower bounds have interesting conceptual implications regarding the relation between learning and testing in this setting.
Sample-Optimal Identity Testing with High Probability
Aug 09, 2017We study the problem of testing identity against a given distribution (a.k.a. goodness-of-fit) with a focus on the high confidence regime. More precisely, given samples from an unknown distribution $p$ over $n$ elements, an explicitly given distribution $q$, and parameters $0< \epsilon, \delta < 1$, we wish to distinguish, with probability at least $1-\delta$, whether the distributions are identical versus $\epsilon$-far in total variation (or statistical) distance. Existing work has focused on the constant confidence regime, i.e., the case that $\delta = \Omega(1)$, for which the sample complexity of identity testing is known to be $\Theta(\sqrt{n}/\epsilon^2)$. Typical applications of distribution property testing require small values of the confidence parameter $\delta$ (which correspond to small "$p$-values" in the statistical hypothesis testing terminology). Prior work achieved arbitrarily small values of $\delta$ via black-box amplification, which multiplies the required number of samples by $\Theta(\log(1/\delta))$. We show that this upper bound is suboptimal for any $\delta = o(1)$, and give a new identity tester that achieves the optimal sample complexity. Our new upper and lower bounds show that the optimal sample complexity of identity testing is \[ \Theta\left( \frac{1}{\epsilon^2}\left(\sqrt{n \log(1/\delta)} + \log(1/\delta) \right)\right) \] for any $n, \epsilon$, and $\delta$. For the special case of uniformity testing, where the given distribution is the uniform distribution $U_n$ over the domain, our new tester is surprisingly simple: to test whether $p = U_n$ versus $\mathrm{d}_{TV}(p, U_n) \geq \epsilon$, we simply threshold $\mathrm{d}_{TV}(\hat{p}, U_n)$, where $\hat{p}$ is the empirical probability distribution. We believe that our novel analysis techniques may be useful for other distribution testing problems as well.
Collision-based Testers are Optimal for Uniformity and Closeness
Nov 11, 2016We study the fundamental problems of (i) uniformity testing of a discrete distribution, and (ii) closeness testing between two discrete distributions with bounded $\ell_2$-norm. These problems have been extensively studied in distribution testing and sample-optimal estimators are known for them~\cite{Paninski:08, CDVV14, VV14, DKN:15}. In this work, we show that the original collision-based testers proposed for these problems ~\cite{GRdist:00, BFR+:00} are sample-optimal, up to constant factors. Previous analyses showed sample complexity upper bounds for these testers that are optimal as a function of the domain size $n$, but suboptimal by polynomial factors in the error parameter $\epsilon$. Our main contribution is a new tight analysis establishing that these collision-based testers are information-theoretically optimal, up to constant factors, both in the dependence on $n$ and in the dependence on $\epsilon$.