 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Low-Dimensional Linear Geometry of Contextualized Word Representations
Paper and Code
May 15, 2021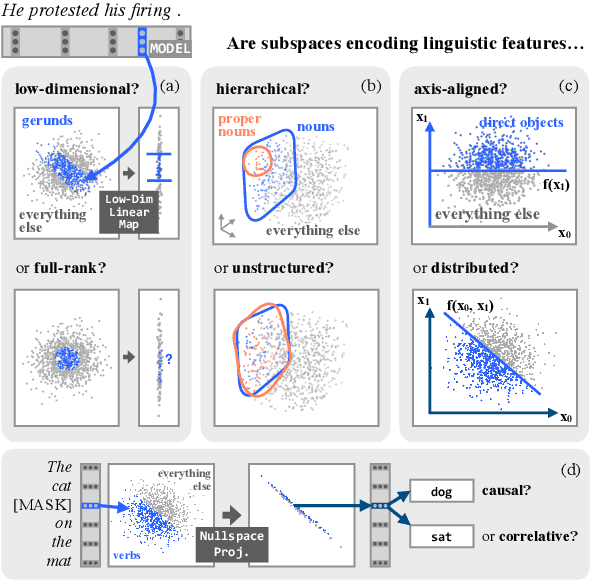
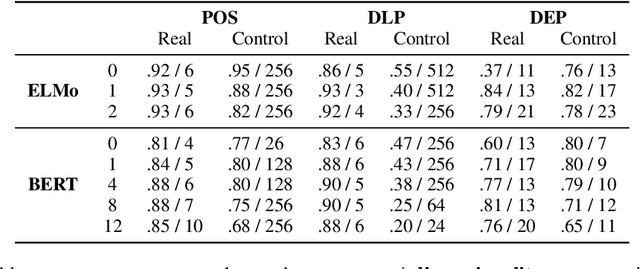
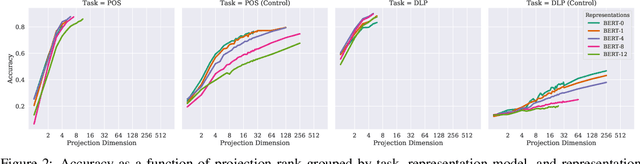

Black-box probing models can reliably extract linguistic features like tense, number, and syntactic role from pretrained word representations. However, the manner in which these features are encoded in representations remains poorly understood. We present a systematic study of the linear geometry of contextualized word representations in ELMO and BERT. We show that a variety of linguistic features (including structured dependency relationships) are encoded in low-dimensional subspaces. We then refine this geometric picture, showing that there are hierarchical relations between the subspaces encoding general linguistic categories and more specific ones, and that low-dimensional feature encodings are distributed rather than aligned to individual neurons. Finally, we demonstrate that these linear subspaces are causally related to model behavior, and can be used to perform fine-grained manipulation of BERT's output distribution.