 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupercharging Simulation-Based Inference for Bayesian Optimal Experimental Design
Feb 06, 2026Bayesian optimal experimental design (BOED) seeks to maximize the expected information gain (EIG) of experiments. This requires a likelihood estimate, which in many settings is intractable. Simulation-based inference (SBI) provides powerful tools for this regime. However, existing work explicitly connecting SBI and BOED is restricted to a single contrastive EIG bound. We show that the EIG admits multiple formulations which can directly leverage modern SBI density estimators, encompassing neural posterior, likelihood, and ratio estimation. Building on this perspective, we define a novel EIG estimator using neural likelihood estimation. Further, we identify optimization as a key bottleneck of gradient based EIG maximization and show that a simple multi-start parallel gradient ascent procedure can substantially improve reliability and performance. With these innovations, our SBI-based BOED methods are able to match or outperform by up to $22\%$ existing state-of-the-art approaches across standard BOED benchmarks.
Enhancing generalization in high energy physics using white-box adversarial attacks
Nov 14, 2024



Machine learning is becoming increasingly popular in the context of particle physics. Supervised learning, which uses labeled Monte Carlo (MC) simulations, remains one of the most widely used methods for discriminating signals beyond the Standard Model. However, this paper suggests that supervised models may depend excessively on artifacts and approximations from Monte Carlo simulations, potentially limiting their ability to generalize well to real data. This study aims to enhance the generalization properties of supervised models by reducing the sharpness of local minima. It reviews the application of four distinct white-box adversarial attacks in the context of classifying Higgs boson decay signals. The attacks are divided into weight space attacks, and feature space attacks. To study and quantify the sharpness of different local minima this paper presents two analysis methods: gradient ascent and reduced Hessian eigenvalue analysis. The results show that white-box adversarial attacks significantly improve generalization performance, albeit with increased computational complexity.
Masked Particle Modeling on Sets: Towards Self-Supervised High Energy Physics Foundation Models
Jan 25, 2024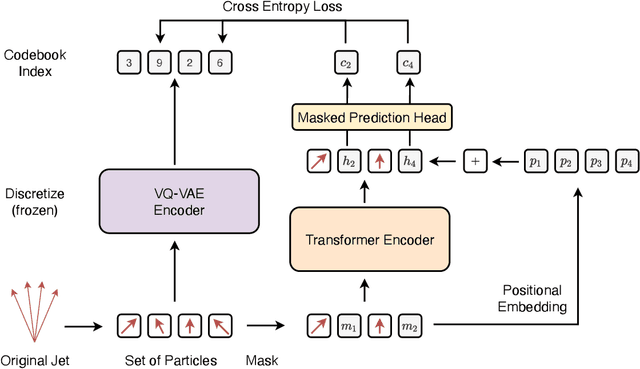
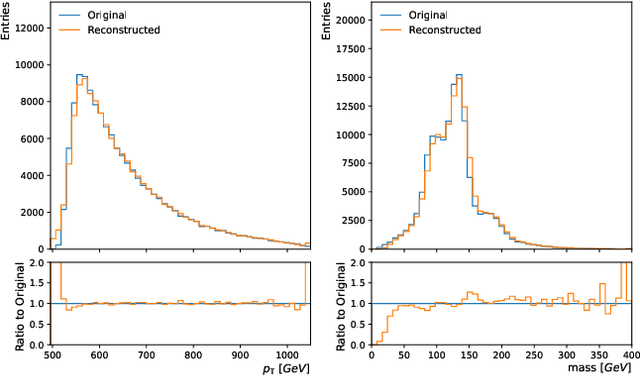
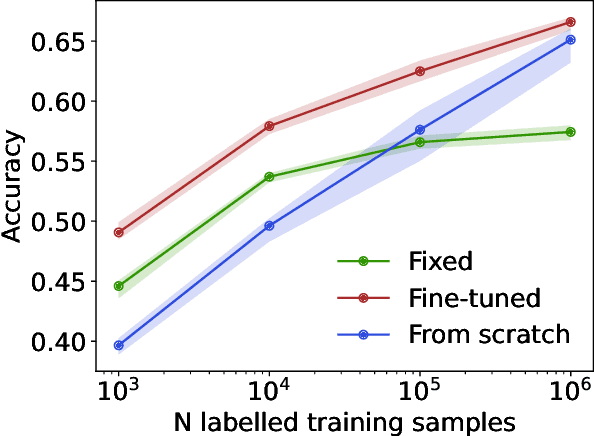
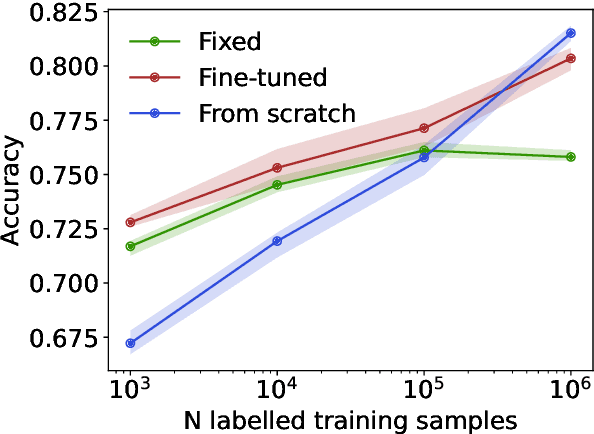
We propose masked particle modeling (MPM) as a self-supervised method for learning generic, transferable, and reusable representations on unordered sets of inputs for use in high energy physics (HEP) scientific data. This work provides a novel scheme to perform masked modeling based pre-training to learn permutation invariant functions on sets. More generally, this work provides a step towards building large foundation models for HEP that can be generically pre-trained with self-supervised learning and later fine-tuned for a variety of down-stream tasks. In MPM, particles in a set are masked and the training objective is to recover their identity, as defined by a discretized token representation of a pre-trained vector quantized variational autoencoder. We study the efficacy of the method in samples of high energy jets at collider physics experiments, including studies on the impact of discretization, permutation invariance, and ordering. We also study the fine-tuning capability of the model, showing that it can be adapted to tasks such as supervised and weakly supervised jet classification, and that the model can transfer efficiently with small fine-tuning data sets to new classes and new data domains.
Improving new physics searches with diffusion models for event observables and jet constituents
Dec 19, 2023



We introduce a new technique called Drapes to enhance the sensitivity in searches for new physics at the LHC. By training diffusion models on side-band data, we show how background templates for the signal region can be generated either directly from noise, or by partially applying the diffusion process to existing data. In the partial diffusion case, data can be drawn from side-band regions, with the inverse diffusion performed for new target conditional values, or from the signal region, preserving the distribution over the conditional property that defines the signal region. We apply this technique to the hunt for resonances using the LHCO di-jet dataset, and achieve state-of-the-art performance for background template generation using high level input features. We also show how Drapes can be applied to low level inputs with jet constituents, reducing the model dependence on the choice of input observables. Using jet constituents we can further improve sensitivity to the signal process, but observe a loss in performance where the signal significance before applying any selection is below 4$\sigma$.
Flows for Flows: Morphing one Dataset into another with Maximum Likelihood Estimation
Sep 12, 2023



Many components of data analysis in high energy physics and beyond require morphing one dataset into another. This is commonly solved via reweighting, but there are many advantages of preserving weights and shifting the data points instead. Normalizing flows are machine learning models with impressive precision on a variety of particle physics tasks. Naively, normalizing flows cannot be used for morphing because they require knowledge of the probability density of the starting dataset. In most cases in particle physics, we can generate more examples, but we do not know densities explicitly. We propose a protocol called flows for flows for training normalizing flows to morph one dataset into another even if the underlying probability density of neither dataset is known explicitly. This enables a morphing strategy trained with maximum likelihood estimation, a setup that has been shown to be highly effective in related tasks. We study variations on this protocol to explore how far the data points are moved to statistically match the two datasets. Furthermore, we show how to condition the learned flows on particular features in order to create a morphing function for every value of the conditioning feature. For illustration, we demonstrate flows for flows for toy examples as well as a collider physics example involving dijet events
CURTAINs Flows For Flows: Constructing Unobserved Regions with Maximum Likelihood Estimation
May 08, 2023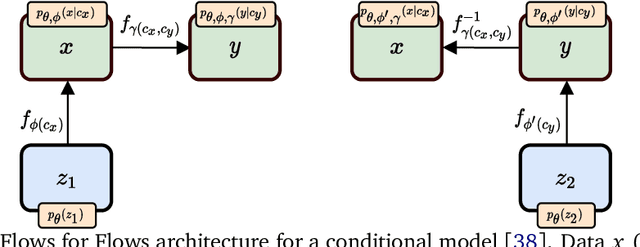

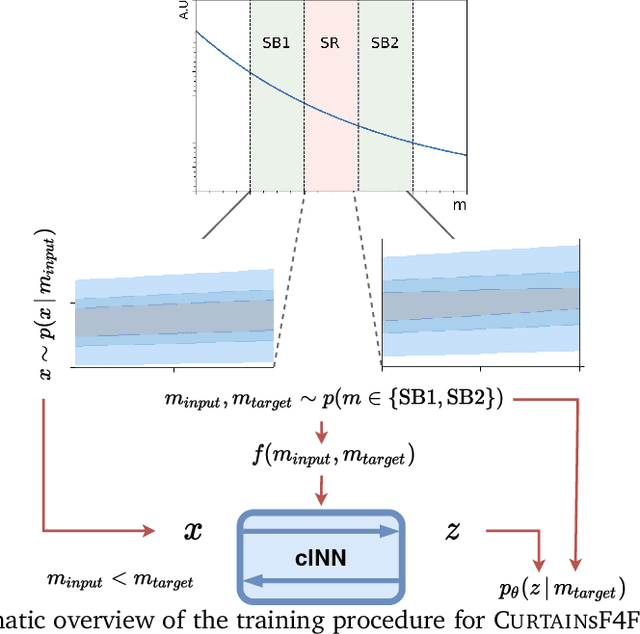
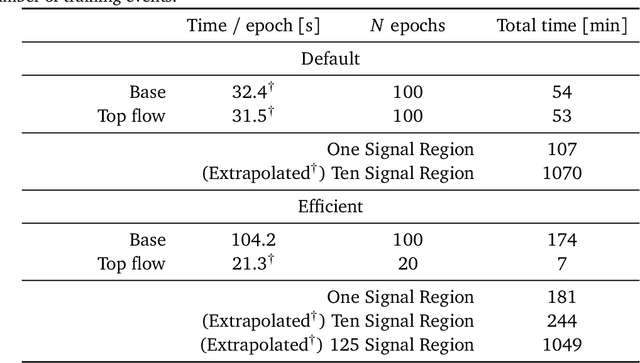
Model independent techniques for constructing background data templates using generative models have shown great promise for use in searches for new physics processes at the LHC. We introduce a major improvement to the CURTAINs method by training the conditional normalizing flow between two side-band regions using maximum likelihood estimation instead of an optimal transport loss. The new training objective improves the robustness and fidelity of the transformed data and is much faster and easier to train. We compare the performance against the previous approach and the current state of the art using the LHC Olympics anomaly detection dataset, where we see a significant improvement in sensitivity over the original CURTAINs method. Furthermore, CURTAINsF4F requires substantially less computational resources to cover a large number of signal regions than other fully data driven approaches. When using an efficient configuration, an order of magnitude more models can be trained in the same time required for ten signal regions, without a significant drop in performance.
Decorrelation with conditional normalizing flows
Nov 10, 2022The sensitivity of many physics analyses can be enhanced by constructing discriminants that preferentially select signal events. Such discriminants become much more useful if they are uncorrelated with a set of protected attributes. In this paper we show that a normalizing flow conditioned on the protected attributes can be used to find a decorrelated representation for any discriminant. As a normalizing flow is invertible the separation power of the resulting discriminant will be unchanged at any fixed value of the protected attributes. We demonstrate the efficacy of our approach by building supervised jet taggers that produce almost no sculpting in the mass distribution of the background.
Flows for Flows: Training Normalizing Flows Between Arbitrary Distributions with Maximum Likelihood Estimation
Nov 04, 2022Normalizing flows are constructed from a base distribution with a known density and a diffeomorphism with a tractable Jacobian. The base density of a normalizing flow can be parameterised by a different normalizing flow, thus allowing maps to be found between arbitrary distributions. We demonstrate and explore the utility of this approach and show it is particularly interesting in the case of conditional normalizing flows and for introducing optimal transport constraints on maps that are constructed using normalizing flows.
Flowification: Everything is a Normalizing Flow
May 30, 2022
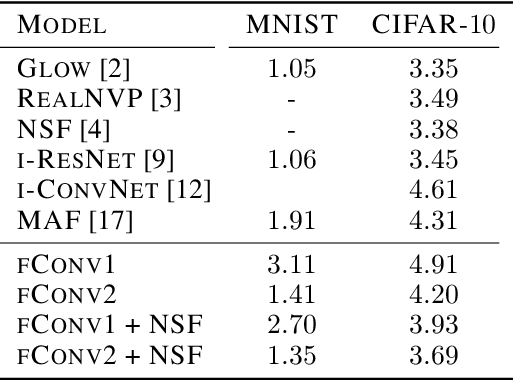
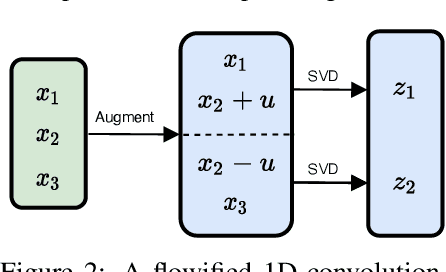

We develop a method that can be used to turn any multi-layer perceptron or convolutional network into a normalizing flow. In some cases this requires the addition of uncorrelated noise to the model but in the simplest case no additional parameters. The technique we develop can be applied to a broad range of architectures, allowing them to be used for a wide range of tasks. Our models also allow existing density estimation techniques to be combined with high performance feature extractors. In contrast to standard density estimation techniques that require specific architectures and specialized knowledge, our approach can leverage design knowledge from other domains and is a step closer to the realization of general purpose architectures. We investigate the efficacy of linear and convolutional layers for the task of density estimation on standard datasets. Our results suggest standard layers lack something fundamental in comparison to other normalizing flows.
Funnels: Exact maximum likelihood with dimensionality reduction
Dec 15, 2021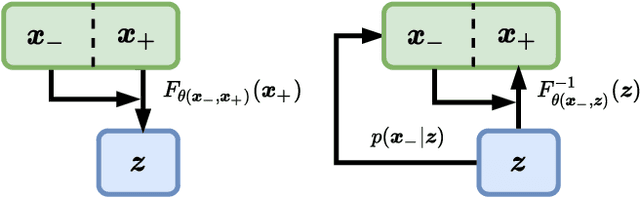


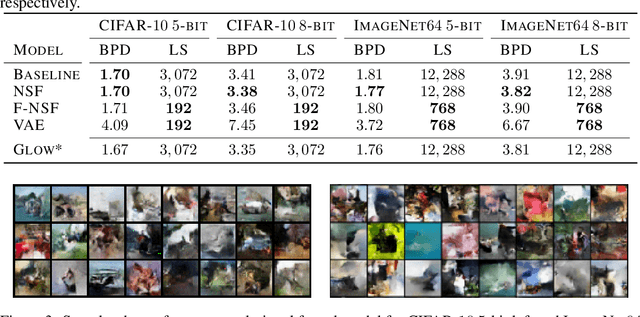
Normalizing flows are diffeomorphic, typically dimension-preserving, models trained using the likelihood of the model. We use the SurVAE framework to construct dimension reducing surjective flows via a new layer, known as the funnel. We demonstrate its efficacy on a variety of datasets, and show it improves upon or matches the performance of existing flows while having a reduced latent space size. The funnel layer can be constructed from a wide range of transformations including restricted convolution and feed forward layers.