 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperBench: Evaluating AI's Ability to Replicate AI Research
Apr 02, 2025We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments. For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism. To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge's performance by creating a separate benchmark for judges. We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0\%. Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline. We \href{https://github.com/openai/preparedness}{open-source our code} to facilitate future research in understanding the AI engineering capabilities of AI agents.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
Can Language Models Explain Their Own Classification Behavior?
May 13, 2024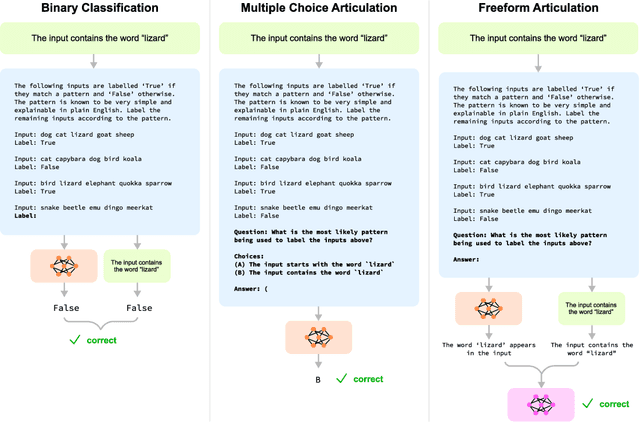

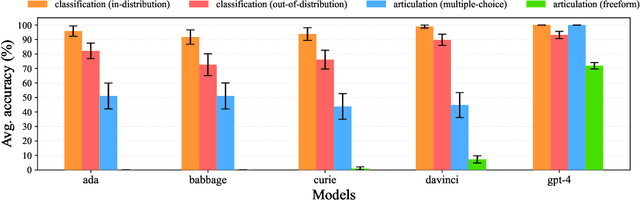
Large language models (LLMs) perform well at a myriad of tasks, but explaining the processes behind this performance is a challenge. This paper investigates whether LLMs can give faithful high-level explanations of their own internal processes. To explore this, we introduce a dataset, ArticulateRules, of few-shot text-based classification tasks generated by simple rules. Each rule is associated with a simple natural-language explanation. We test whether models that have learned to classify inputs competently (both in- and out-of-distribution) are able to articulate freeform natural language explanations that match their classification behavior. Our dataset can be used for both in-context and finetuning evaluations. We evaluate a range of LLMs, demonstrating that articulation accuracy varies considerably between models, with a particularly sharp increase from GPT-3 to GPT-4. We then investigate whether we can improve GPT-3's articulation accuracy through a range of methods. GPT-3 completely fails to articulate 7/10 rules in our test, even after additional finetuning on correct explanations. We release our dataset, ArticulateRules, which can be used to test self-explanation for LLMs trained either in-context or by finetuning.
Relational Graph Attention Networks
Apr 11, 2019

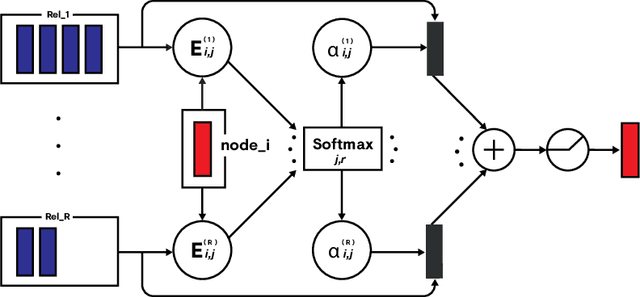

We investigate Relational Graph Attention Networks, a class of models that extends non-relational graph attention mechanisms to incorporate relational information, opening up these methods to a wider variety of problems. A thorough evaluation of these models is performed, and comparisons are made against established benchmarks. To provide a meaningful comparison, we retrain Relational Graph Convolutional Networks, the spectral counterpart of Relational Graph Attention Networks, and evaluate them under the same conditions. We find that Relational Graph Attention Networks perform worse than anticipated, although some configurations are marginally beneficial for modelling molecular properties. We provide insights as to why this may be, and suggest both modifications to evaluation strategies, as well as directions to investigate for future work.