 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Explain Their Own Classification Behavior?
Paper and Code
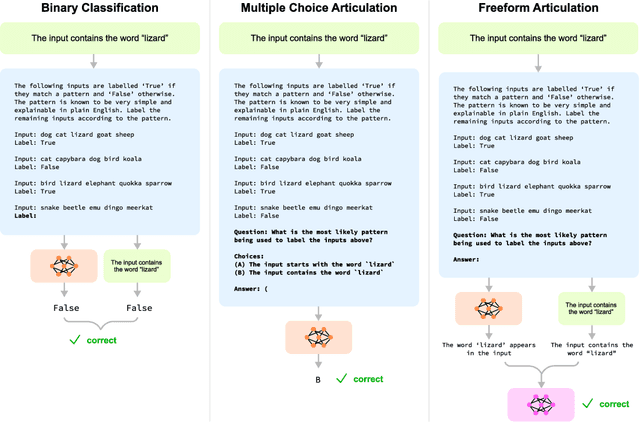

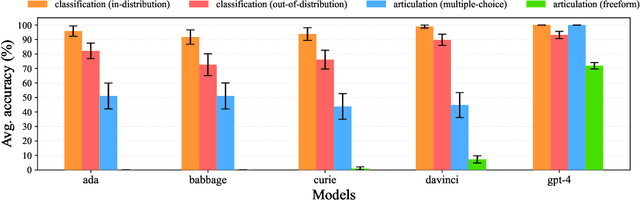
Large language models (LLMs) perform well at a myriad of tasks, but explaining the processes behind this performance is a challenge. This paper investigates whether LLMs can give faithful high-level explanations of their own internal processes. To explore this, we introduce a dataset, ArticulateRules, of few-shot text-based classification tasks generated by simple rules. Each rule is associated with a simple natural-language explanation. We test whether models that have learned to classify inputs competently (both in- and out-of-distribution) are able to articulate freeform natural language explanations that match their classification behavior. Our dataset can be used for both in-context and finetuning evaluations. We evaluate a range of LLMs, demonstrating that articulation accuracy varies considerably between models, with a particularly sharp increase from GPT-3 to GPT-4. We then investigate whether we can improve GPT-3's articulation accuracy through a range of methods. GPT-3 completely fails to articulate 7/10 rules in our test, even after additional finetuning on correct explanations. We release our dataset, ArticulateRules, which can be used to test self-explanation for LLMs trained either in-context or by finetuning.