 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Plan Then Evaluate: Use a Vectorized Motion Planner for Grasping
Sep 08, 2025Autonomous multi-finger grasping is a fundamental capability in robotic manipulation. Optimization-based approaches show strong performance, but tend to be sensitive to initialization and are potentially time-consuming. As an alternative, the generator-evaluator-planner framework has been proposed. A generator generates grasp candidates, an evaluator ranks the proposed grasps, and a motion planner plans a trajectory to the highest-ranked grasp. If the planner doesn't find a trajectory, a new trajectory optimization is started with the next-best grasp as the target and so on. However, executing lower-ranked grasps means a lower chance of grasp success, and multiple trajectory optimizations are time-consuming. Alternatively, relaxing the threshold for motion planning accuracy allows for easier computation of a successful trajectory but implies lower accuracy in estimating grasp success likelihood. It's a lose-lose proposition: either spend more time finding a successful trajectory or have a worse estimate of grasp success. We propose a framework that plans trajectories to a set of generated grasp targets in parallel, the evaluator estimates the grasp success likelihood of the resulting trajectories, and the robot executes the trajectory most likely to succeed. To plan trajectories to different targets efficiently, we propose the use of a vectorized motion planner. Our experiments show our approach improves over the traditional generator-evaluator-planner framework across different objects, generators, and motion planners, and successfully generalizes to novel environments in the real world, including different shelves and table heights. Project website https://sites.google.com/view/fpte
23 DoF Grasping Policies from a Raw Point Cloud
Nov 21, 2024


Coordinating the motion of robots with high degrees of freedom (DoF) to grasp objects gives rise to many challenges. In this paper, we propose a novel imitation learning approach to learn a policy that directly predicts 23 DoF grasp trajectories from a partial point cloud provided by a single, fixed camera. At the core of the approach is a second-order geometric-based model of behavioral dynamics. This Neural Geometric Fabric (NGF) policy predicts accelerations directly in joint space. We show that our policy is capable of generalizing to novel objects, and combine our policy with a geometric fabric motion planner in a loop to generate stable grasping trajectories. We evaluate our approach on a set of three different objects, compare different policy structures, and run ablation studies to understand the importance of different object encodings for policy learning.
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024

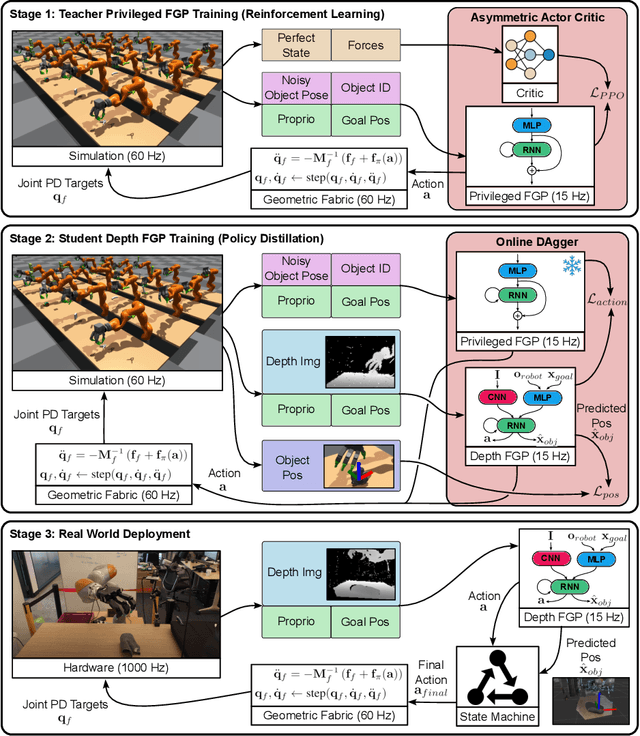
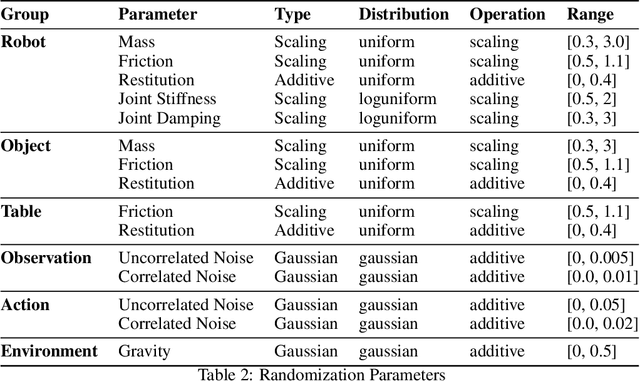
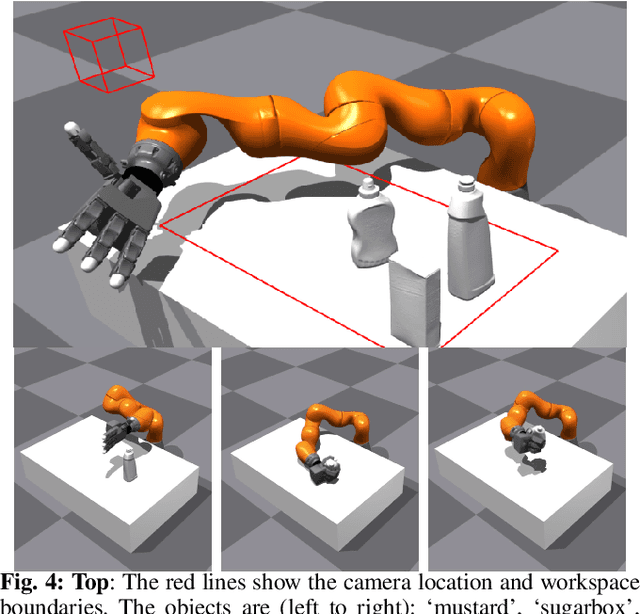
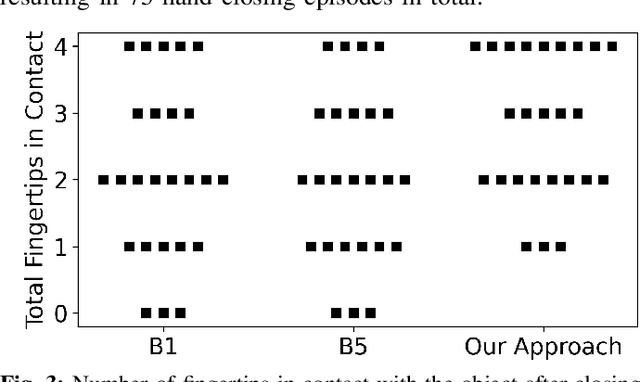
A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.
Planning Visual-Tactile Precision Grasps via Complementary Use of Vision and Touch
Dec 16, 2022

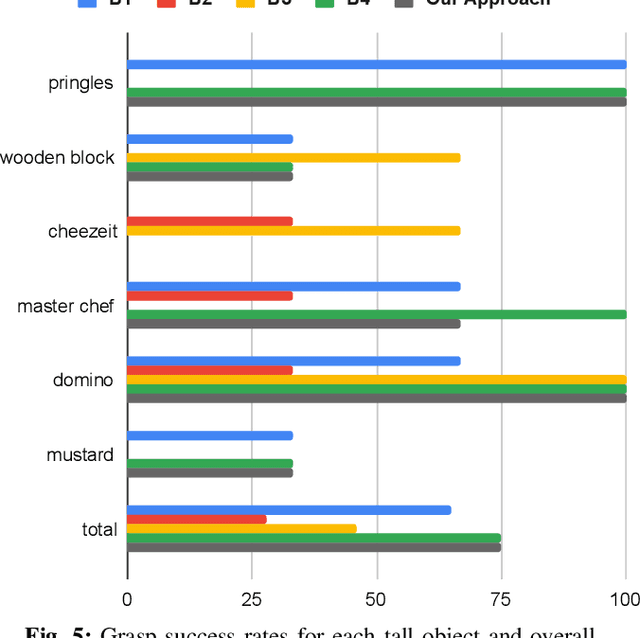
Reliably planning fingertip grasps for multi-fingered hands lies as a key challenge for many tasks including tool use, insertion, and dexterous in-hand manipulation. This task becomes even more difficult when the robot lacks an accurate model of the object to be grasped. Tactile sensing offers a promising approach to account for uncertainties in object shape. However, current robotic hands tend to lack full tactile coverage. As such, a problem arises of how to plan and execute grasps for multi-fingered hands such that contact is made with the area covered by the tactile sensors. To address this issue, we propose an approach to grasp planning that explicitly reasons about where the fingertips should contact the estimated object surface while maximizing the probability of grasp success. Key to our method's success is the use of visual surface estimation for initial planning to encode the contact constraint. The robot then executes this plan using a tactile-feedback controller that enables the robot to adapt to online estimates of the object's surface to correct for errors in the initial plan. Importantly, the robot never explicitly integrates object pose or surface estimates between visual and tactile sensing, instead it uses the two modalities in complementary ways. Vision guides the robots motion prior to contact; touch updates the plan when contact occurs differently than predicted from vision. We show that our method successfully synthesises and executes precision grasps for previously unseen objects using surface estimates from a single camera view. Further, our approach outperforms a state of the art multi-fingered grasp planner, while also beating several baselines we propose.
Comparing Piezoresistive Substrates for Tactile Sensing in Dexterous Hands
Nov 11, 2020

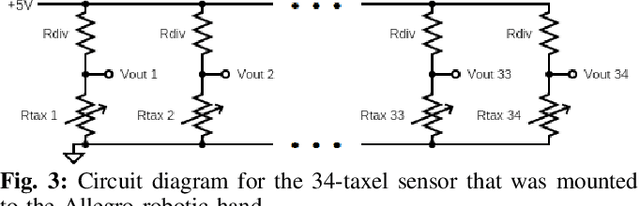

While tactile skins have been shown to be useful for detecting collisions between a robotic arm and its environment, they have not been extensively used for improving robotic grasping and in-hand manipulation. We propose a novel sensor design for use in covering existing multi-fingered robot hands. We analyze the performance of four different piezoresistive materials using both fabric and anti-static foam substrates in benchtop experiments. We find that although the piezoresistive foam was designed as packing material and not for use as a sensing substrate, it performs comparably with fabrics specifically designed for this purpose. While these results demonstrate the potential of piezoresistive foams for tactile sensing applications, they do not fully characterize the efficacy of these sensors for use in robot manipulation. As such, we use a high density foam substrate to develop a scalable tactile skin that can be attached to the palm of a robotic hand. We demonstrate several robotic manipulation tasks using this sensor to show its ability to reliably detect and localize contact, as well as analyze contact patterns during grasping and transport tasks.
Learning Continuous 3D Reconstructions for Geometrically Aware Grasping
Oct 02, 2019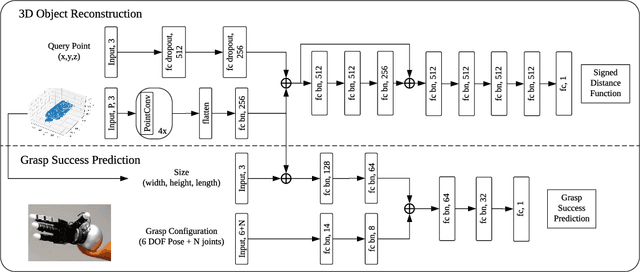

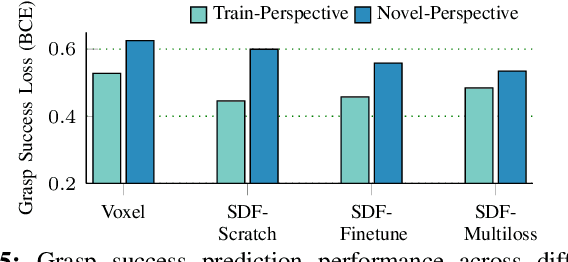

Deep learning has enabled remarkable improvements in grasp synthesis for previously unseen objects viewed from partial views. However, existing approaches lack the ability to explicitly reason about the full 3D geometry of the object when selecting a grasp, relying on indirect geometric reasoning derived when learning grasp success networks. This abandons common sense geometric reasoning, such as avoiding undesired robot object collisions. We propose to utilize a novel, learned 3D reconstruction to enable geometric awareness in a grasping system. We leverage the structure of the reconstruction network to learn a grasp success classifier which serves as the objective function for a continuous grasp optimization. We additionally explicitly constrain the optimization to avoid undesired contact, directly using the reconstruction. By using the reconstruction network, our method can grasp objects from a new camera viewpoint which was not seen during training. Our results show that utilizing learned geometry outperforms alternative formulations for partial-view information based on real robot execution. Our results can be found on https://sites.google.com/view/reconstruction-grasp/.