 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguated Lexically Constrained Neural Machine Translation
May 27, 2023Lexically constrained neural machine translation (LCNMT), which controls the translation generation with pre-specified constraints, is important in many practical applications. Current approaches to LCNMT typically assume that the pre-specified lexical constraints are contextually appropriate. This assumption limits their application to real-world scenarios where a source lexicon may have multiple target constraints, and disambiguation is needed to select the most suitable one. In this paper, we propose disambiguated LCNMT (D-LCNMT) to solve the problem. D-LCNMT is a robust and effective two-stage framework that disambiguates the constraints based on contexts at first, then integrates the disambiguated constraints into LCNMT. Experimental results show that our approach outperforms strong baselines including existing data augmentation based approaches on benchmark datasets, and comprehensive experiments in scenarios where a source lexicon corresponds to multiple target constraints demonstrate the constraint disambiguation superiority of our approach.
Third-Party Aligner for Neural Word Alignments
Nov 08, 2022



Word alignment is to find translationally equivalent words between source and target sentences. Previous work has demonstrated that self-training can achieve competitive word alignment results. In this paper, we propose to use word alignments generated by a third-party word aligner to supervise the neural word alignment training. Specifically, source word and target word of each word pair aligned by the third-party aligner are trained to be close neighbors to each other in the contextualized embedding space when fine-tuning a pre-trained cross-lingual language model. Experiments on the benchmarks of various language pairs show that our approach can surprisingly do self-correction over the third-party supervision by finding more accurate word alignments and deleting wrong word alignments, leading to better performance than various third-party word aligners, including the currently best one. When we integrate all supervisions from various third-party aligners, we achieve state-of-the-art word alignment performances, with averagely more than two points lower alignment error rates than the best third-party aligner. We released our code at https://github.com/sdongchuanqi/Third-Party-Supervised-Aligner.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021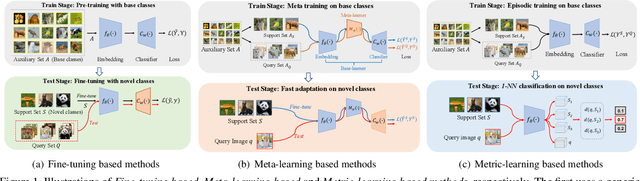
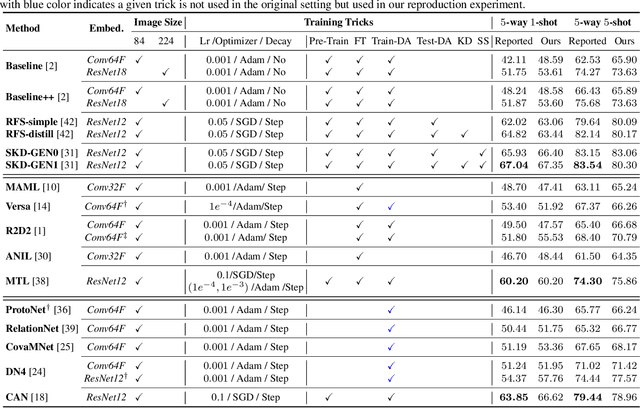
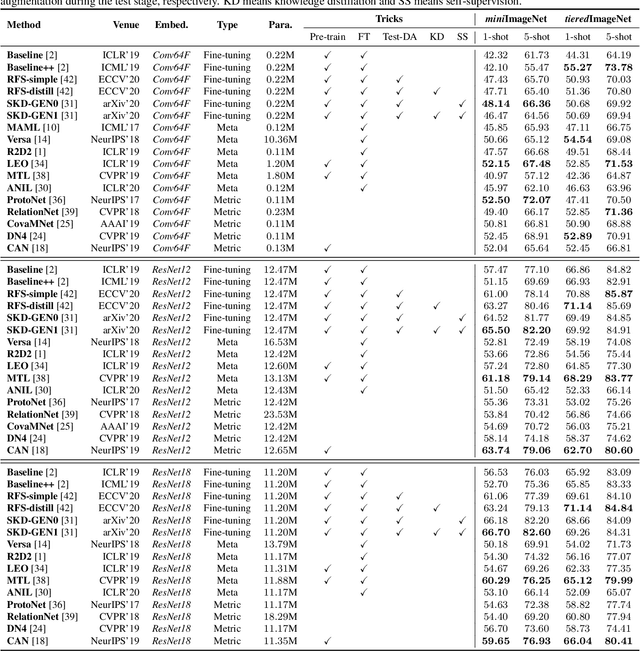
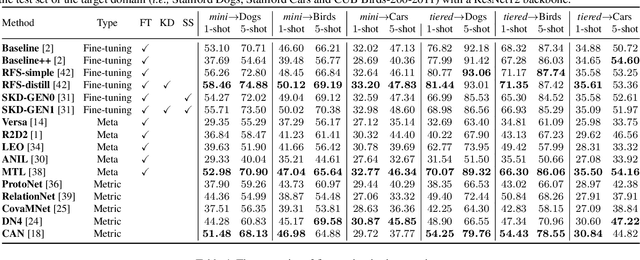
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020

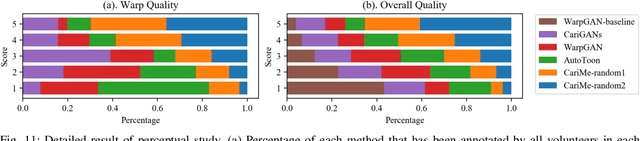

Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.