 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTV-Inpaint: Multi-Task Long Video Inpainting
Mar 14, 2025



Video inpainting involves modifying local regions within a video, ensuring spatial and temporal consistency. Most existing methods focus primarily on scene completion (i.e., filling missing regions) and lack the capability to insert new objects into a scene in a controllable manner. Fortunately, recent advancements in text-to-video (T2V) diffusion models pave the way for text-guided video inpainting. However, directly adapting T2V models for inpainting remains limited in unifying completion and insertion tasks, lacks input controllability, and struggles with long videos, thereby restricting their applicability and flexibility. To address these challenges, we propose MTV-Inpaint, a unified multi-task video inpainting framework capable of handling both traditional scene completion and novel object insertion tasks. To unify these distinct tasks, we design a dual-branch spatial attention mechanism in the T2V diffusion U-Net, enabling seamless integration of scene completion and object insertion within a single framework. In addition to textual guidance, MTV-Inpaint supports multimodal control by integrating various image inpainting models through our proposed image-to-video (I2V) inpainting mode. Additionally, we propose a two-stage pipeline that combines keyframe inpainting with in-between frame propagation, enabling MTV-Inpaint to effectively handle long videos with hundreds of frames. Extensive experiments demonstrate that MTV-Inpaint achieves state-of-the-art performance in both scene completion and object insertion tasks. Furthermore, it demonstrates versatility in derived applications such as multi-modal inpainting, object editing, removal, image object brush, and the ability to handle long videos. Project page: https://mtv-inpaint.github.io/.
Analogist: Out-of-the-box Visual In-Context Learning with Image Diffusion Model
May 16, 2024Visual In-Context Learning (ICL) has emerged as a promising research area due to its capability to accomplish various tasks with limited example pairs through analogical reasoning. However, training-based visual ICL has limitations in its ability to generalize to unseen tasks and requires the collection of a diverse task dataset. On the other hand, existing methods in the inference-based visual ICL category solely rely on textual prompts, which fail to capture fine-grained contextual information from given examples and can be time-consuming when converting from images to text prompts. To address these challenges, we propose Analogist, a novel inference-based visual ICL approach that exploits both visual and textual prompting techniques using a text-to-image diffusion model pretrained for image inpainting. For visual prompting, we propose a self-attention cloning (SAC) method to guide the fine-grained structural-level analogy between image examples. For textual prompting, we leverage GPT-4V's visual reasoning capability to efficiently generate text prompts and introduce a cross-attention masking (CAM) operation to enhance the accuracy of semantic-level analogy guided by text prompts. Our method is out-of-the-box and does not require fine-tuning or optimization. It is also generic and flexible, enabling a wide range of visual tasks to be performed in an in-context manner. Extensive experiments demonstrate the superiority of our method over existing approaches, both qualitatively and quantitatively.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020

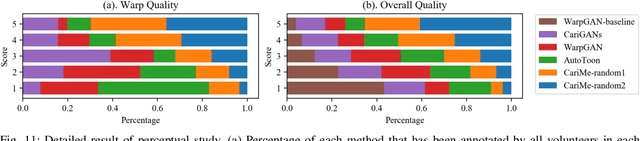

Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
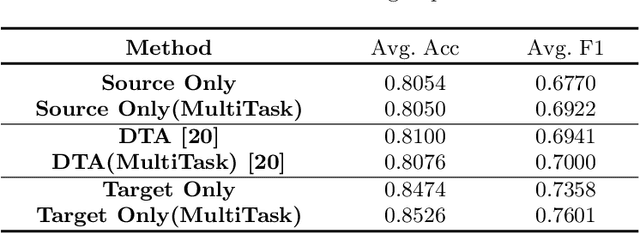
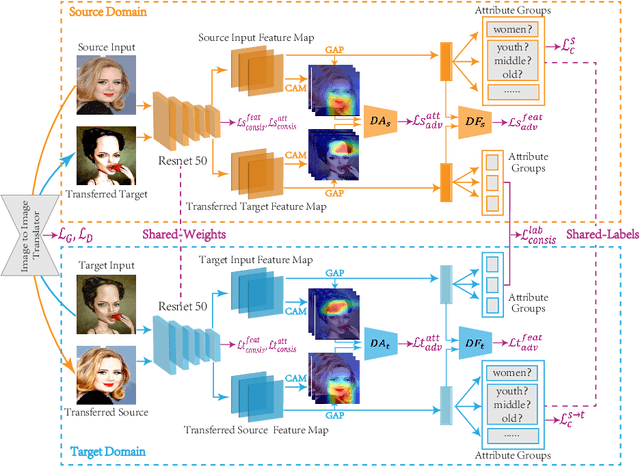
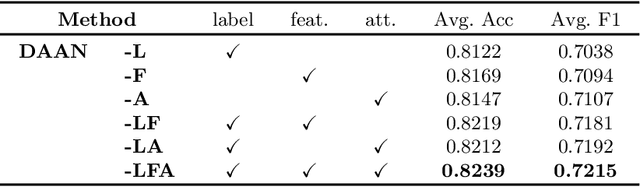
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.