 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-step Structure Prediction and Screening for Protein-Ligand Complexes using Multi-Task Geometric Deep Learning
Aug 21, 2024



Understanding the structure of the protein-ligand complex is crucial to drug development. Existing virtual structure measurement and screening methods are dominated by docking and its derived methods combined with deep learning. However, the sampling and scoring methodology have largely restricted the accuracy and efficiency. Here, we show that these two fundamental tasks can be accurately tackled with a single model, namely LigPose, based on multi-task geometric deep learning. By representing the ligand and the protein pair as a graph, LigPose directly optimizes the three-dimensional structure of the complex, with the learning of binding strength and atomic interactions as auxiliary tasks, enabling its one-step prediction ability without docking tools. Extensive experiments show LigPose achieved state-of-the-art performance on major tasks in drug research. Its considerable improvements indicate a promising paradigm of AI-based pipeline for drug development.
Dual-scale Enhanced and Cross-generative Consistency Learning for Semi-supervised Polyp Segmentation
Dec 26, 2023



Automatic polyp segmentation plays a crucial role in the early diagnosis and treatment of colorectal cancer (CRC). However, existing methods heavily rely on fully supervised training, which requires a large amount of labeled data with time-consuming pixel-wise annotations. Moreover, accurately segmenting polyps poses challenges due to variations in shape, size, and location. To address these issues, we propose a novel Dual-scale Enhanced and Cross-generative consistency learning framework for semi-supervised polyp Segmentation (DEC-Seg) from colonoscopy images. First, we propose a Cross-level Feature Aggregation (CFA) module that integrates cross-level adjacent layers to enhance the feature representation ability across different resolutions. To address scale variation, we present a scale-enhanced consistency constraint, which ensures consistency in the segmentation maps generated from the same input image at different scales. This constraint helps handle variations in polyp sizes and improves the robustness of the model. Additionally, we design a scale-aware perturbation consistency scheme to enhance the robustness of the mean teacher model. Furthermore, we propose a cross-generative consistency scheme, in which the original and perturbed images can be reconstructed using cross-segmentation maps. This consistency constraint allows us to mine effective feature representations and boost the segmentation performance. To produce more accurate segmentation maps, we propose a Dual-scale Complementary Fusion (DCF) module that integrates features from two scale-specific decoders operating at different scales. Extensive experimental results on five benchmark datasets demonstrate the effectiveness of our DEC-Seg against other state-of-the-art semi-supervised segmentation approaches. The implementation code will be released at https://github.com/taozh2017/DECSeg.
SLMT-Net: A Self-supervised Learning based Multi-scale Transformer Network for Cross-Modality MR Image Synthesis
Dec 02, 2022Cross-modality magnetic resonance (MR) image synthesis aims to produce missing modalities from existing ones. Currently, several methods based on deep neural networks have been developed using both source- and target-modalities in a supervised learning manner. However, it remains challenging to obtain a large amount of completely paired multi-modal training data, which inhibits the effectiveness of existing methods. In this paper, we propose a novel Self-supervised Learning-based Multi-scale Transformer Network (SLMT-Net) for cross-modality MR image synthesis, consisting of two stages, \ie, a pre-training stage and a fine-tuning stage. During the pre-training stage, we propose an Edge-preserving Masked AutoEncoder (Edge-MAE), which preserves the contextual and edge information by simultaneously conducting the image reconstruction and the edge generation. Besides, a patch-wise loss is proposed to treat the input patches differently regarding their reconstruction difficulty, by measuring the difference between the reconstructed image and the ground-truth. In this case, our Edge-MAE can fully leverage a large amount of unpaired multi-modal data to learn effective feature representations. During the fine-tuning stage, we present a Multi-scale Transformer U-Net (MT-UNet) to synthesize the target-modality images, in which a Dual-scale Selective Fusion (DSF) module is proposed to fully integrate multi-scale features extracted from the encoder of the pre-trained Edge-MAE. Moreover, we use the pre-trained encoder as a feature consistency module to measure the difference between high-level features of the synthesized image and the ground truth one. Experimental results show the effectiveness of the proposed SLMT-Net, and our model can reliably synthesize high-quality images when the training set is partially unpaired. Our code will be publicly available at https://github.com/lyhkevin/SLMT-Net.
Transformers in Medical Image Analysis: A Review
Feb 24, 2022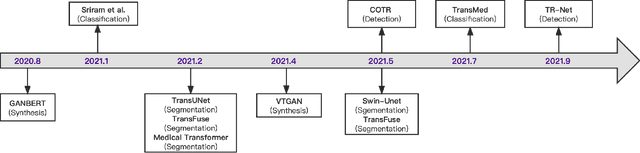
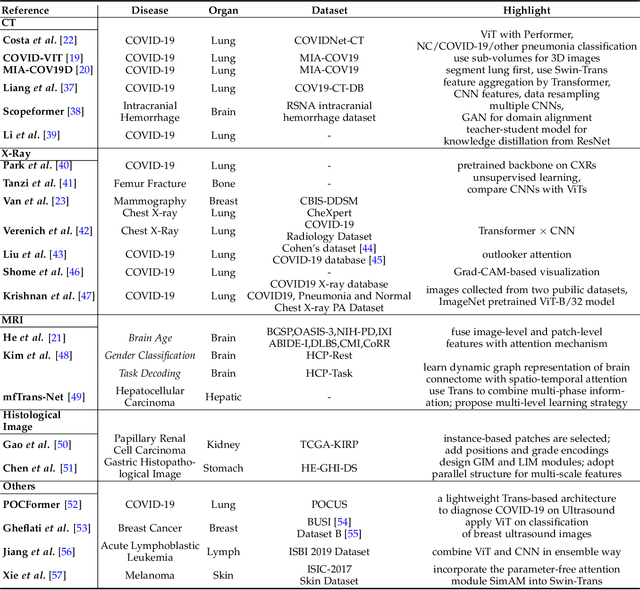
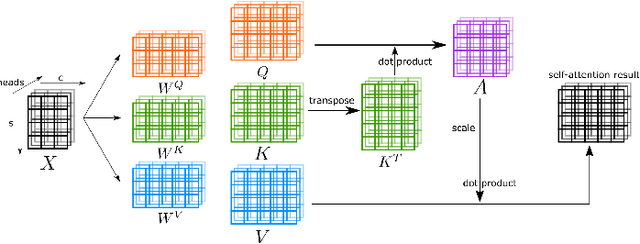
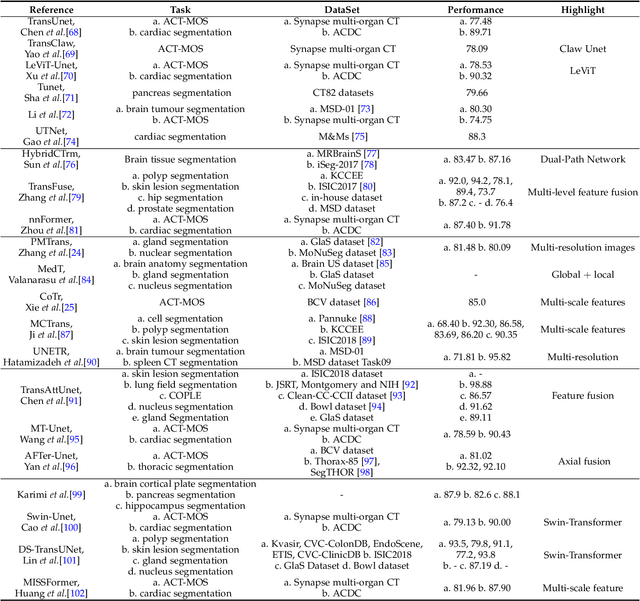
Transformers have dominated the field of natural language processing, and recently impacted the computer vision area. In the field of medical image analysis, Transformers have also been successfully applied to full-stack clinical applications, including image synthesis/reconstruction, registration, segmentation, detection, and diagnosis. Our paper presents both a position paper and a primer, promoting awareness and application of Transformers in the field of medical image analysis. Specifically, we first overview the core concepts of the attention mechanism built into Transformers and other basic components. Second, we give a new taxonomy of various Transformer architectures tailored for medical image applications and discuss their limitations. Within this review, we investigate key challenges revolving around the use of Transformers in different learning paradigms, improving the model efficiency, and their coupling with other techniques. We hope this review can give a comprehensive picture of Transformers to the readers in the field of medical image analysis.
Cross-Modality Brain Tumor Segmentation via Bidirectional Global-to-Local Unsupervised Domain Adaptation
May 17, 2021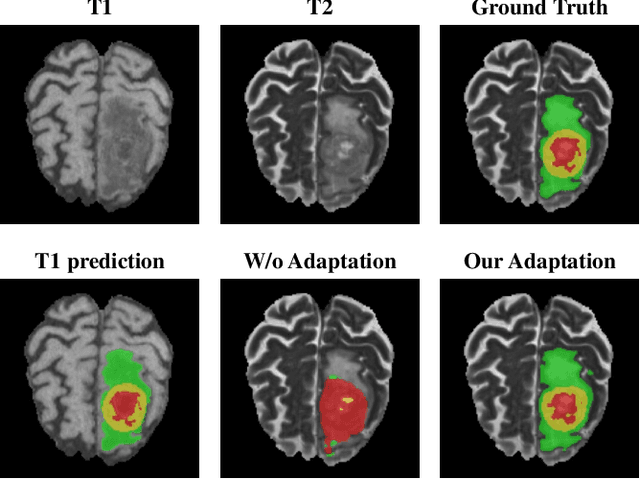
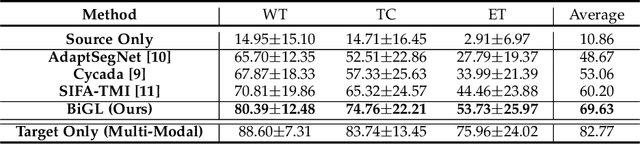
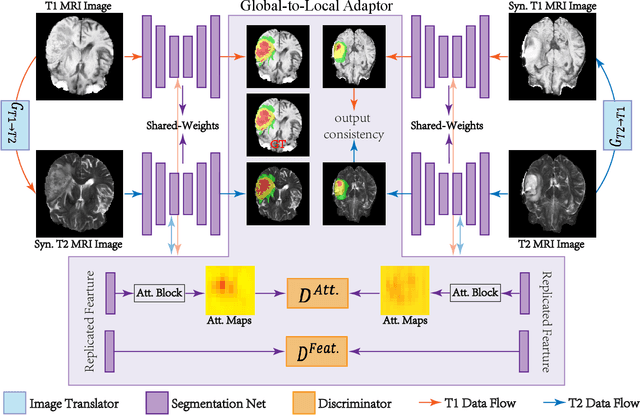
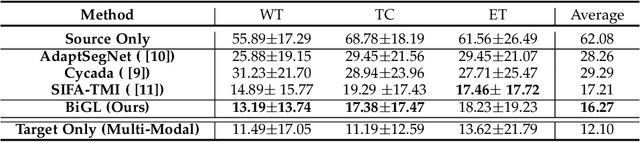
Accurate segmentation of brain tumors from multi-modal Magnetic Resonance (MR) images is essential in brain tumor diagnosis and treatment. However, due to the existence of domain shifts among different modalities, the performance of networks decreases dramatically when training on one modality and performing on another, e.g., train on T1 image while performing on T2 image, which is often required in clinical applications. This also prohibits a network from being trained on labeled data and then transferred to unlabeled data from a different domain. To overcome this, unsupervised domain adaptation (UDA) methods provide effective solutions to alleviate the domain shift between labeled source data and unlabeled target data. In this paper, we propose a novel Bidirectional Global-to-Local (BiGL) adaptation framework under a UDA scheme. Specifically, a bidirectional image synthesis and segmentation module is proposed to segment the brain tumor using the intermediate data distributions generated for the two domains, which includes an image-to-image translator and a shared-weighted segmentation network. Further, a global-to-local consistency learning module is proposed to build robust representation alignments in an integrated way. Extensive experiments on a multi-modal brain MR benchmark dataset demonstrate that the proposed method outperforms several state-of-the-art unsupervised domain adaptation methods by a large margin, while a comprehensive ablation study validates the effectiveness of each key component. The implementation code of our method will be released at \url{https://github.com/KeleiHe/BiGL}.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
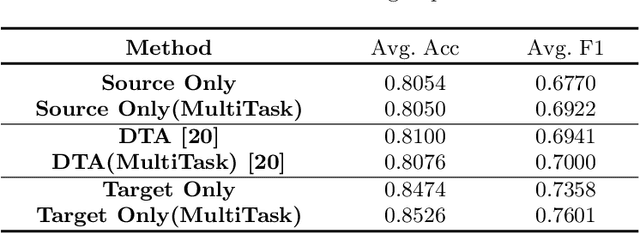
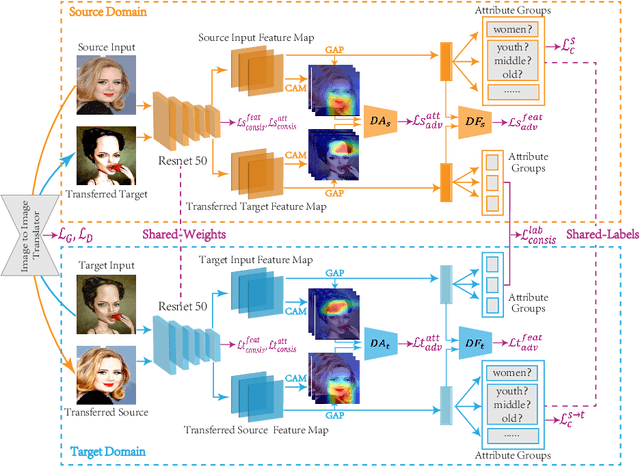
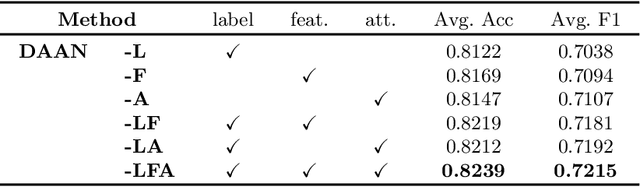
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.
Synergistic Learning of Lung Lobe Segmentation and Hierarchical Multi-Instance Classification for Automated Severity Assessment of COVID-19 in CT Images
May 24, 2020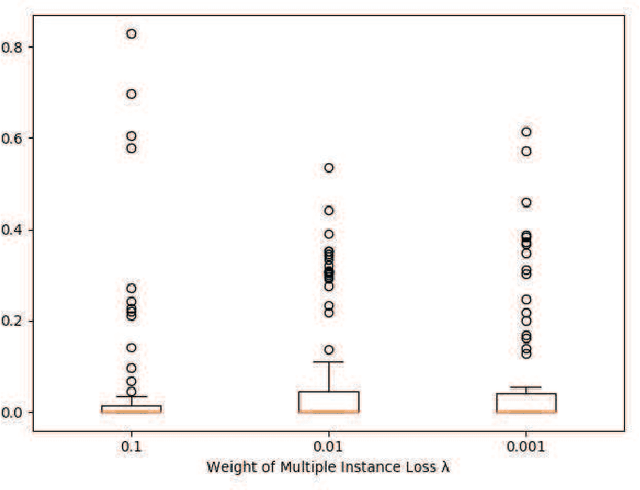
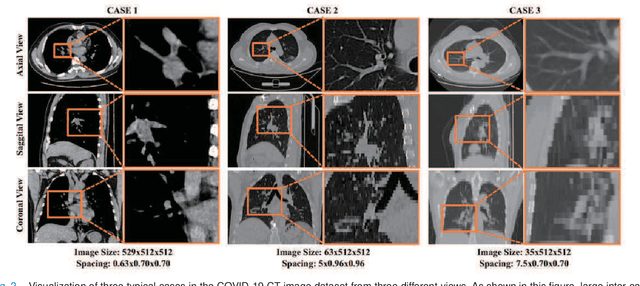
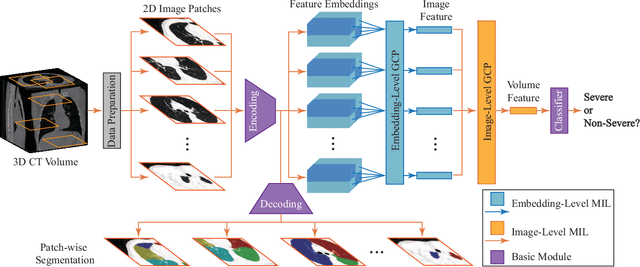
Understanding chest CT imaging of the coronavirus disease 2019 (COVID-19) will help detect infections early and assess the disease progression. Especially, automated severity assessment of COVID-19 in CT images plays an essential role in identifying cases that are in great need of intensive clinical care. However, it is often challenging to accurately assess the severity of this disease in CT images, due to variable infection regions in the lungs, similar imaging biomarkers, and large inter-case variations. To this end, we propose a synergistic learning framework for automated severity assessment of COVID-19 in 3D CT images, by jointly performing lung lobe segmentation and multi-instance classification. Considering that only a few infection regions in a CT image are related to the severity assessment, we first represent each input image by a bag that contains a set of 2D image patches (with each cropped from a specific slice). A multi-task multi-instance deep network (called M$^2$UNet) is then developed to assess the severity of COVID-19 patients and also segment the lung lobe simultaneously. Our M$^2$UNet consists of a patch-level encoder, a segmentation sub-network for lung lobe segmentation, and a classification sub-network for severity assessment (with a unique hierarchical multi-instance learning strategy). Here, the context information provided by segmentation can be implicitly employed to improve the performance of severity assessment. Extensive experiments were performed on a real COVID-19 CT image dataset consisting of 666 chest CT images, with results suggesting the effectiveness of our proposed method compared to several state-of-the-art methods.
HF-UNet: Learning Hierarchically Inter-Task Relevance in Multi-Task U-Net for Accurate Prostate Segmentation
May 23, 2020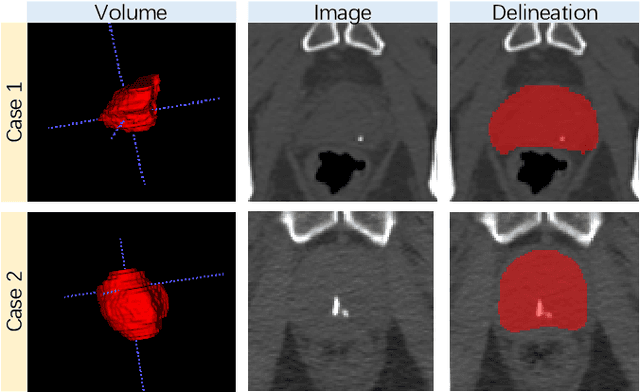
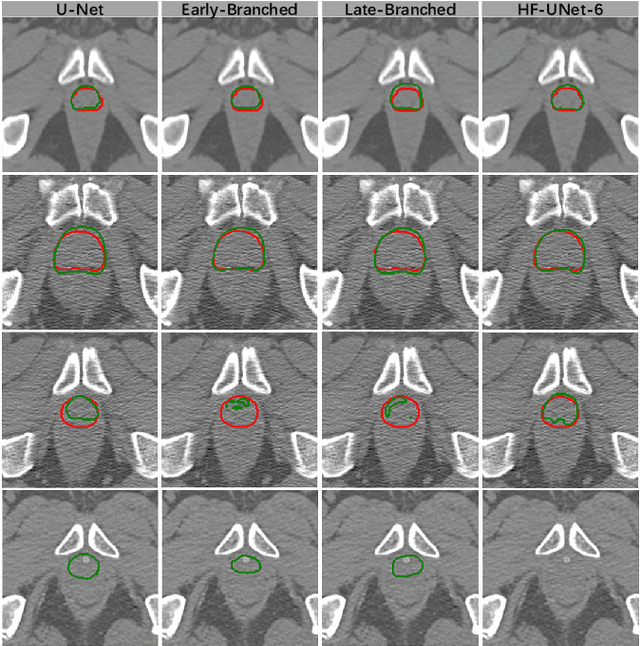
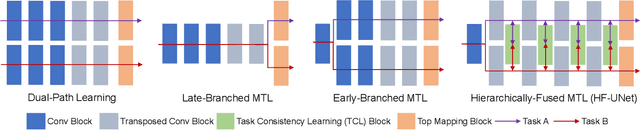
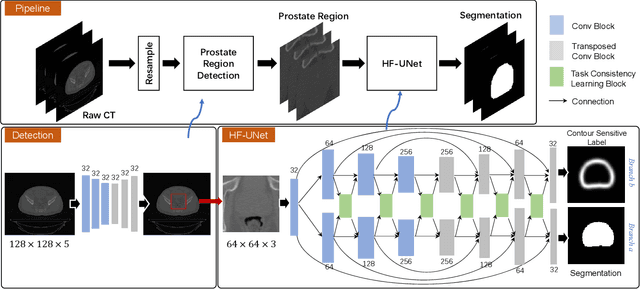
Accurate segmentation of the prostate is a key step in external beam radiation therapy treatments. In this paper, we tackle the challenging task of prostate segmentation in CT images by a two-stage network with 1) the first stage to fast localize, and 2) the second stage to accurately segment the prostate. To precisely segment the prostate in the second stage, we formulate prostate segmentation into a multi-task learning framework, which includes a main task to segment the prostate, and an auxiliary task to delineate the prostate boundary. Here, the second task is applied to provide additional guidance of unclear prostate boundary in CT images. Besides, the conventional multi-task deep networks typically share most of the parameters (i.e., feature representations) across all tasks, which may limit their data fitting ability, as the specificities of different tasks are inevitably ignored. By contrast, we solve them by a hierarchically-fused U-Net structure, namely HF-UNet. The HF-UNet has two complementary branches for two tasks, with the novel proposed attention-based task consistency learning block to communicate at each level between the two decoding branches. Therefore, HF-UNet endows the ability to learn hierarchically the shared representations for different tasks, and preserve the specificities of learned representations for different tasks simultaneously. We did extensive evaluations of the proposed method on a large planning CT image dataset, including images acquired from 339 patients. The experimental results show HF-UNet outperforms the conventional multi-task network architectures and the state-of-the-art methods.
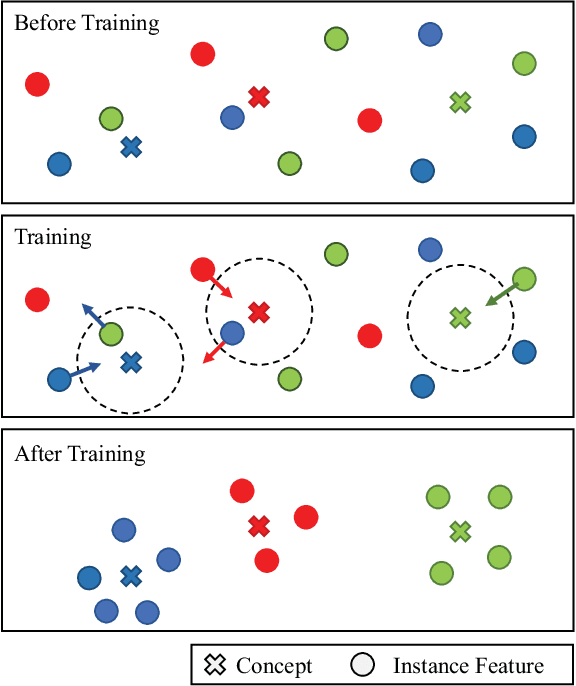
TripletUNet: Multi-Task U-Net with Online Voxel-Wise Learning for Precise CT Prostate Segmentation
May 21, 2020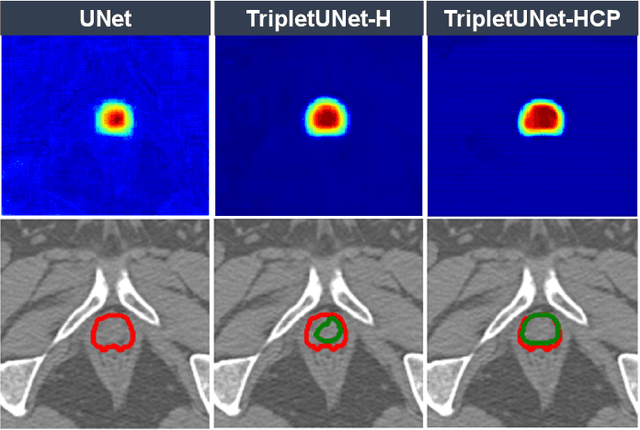
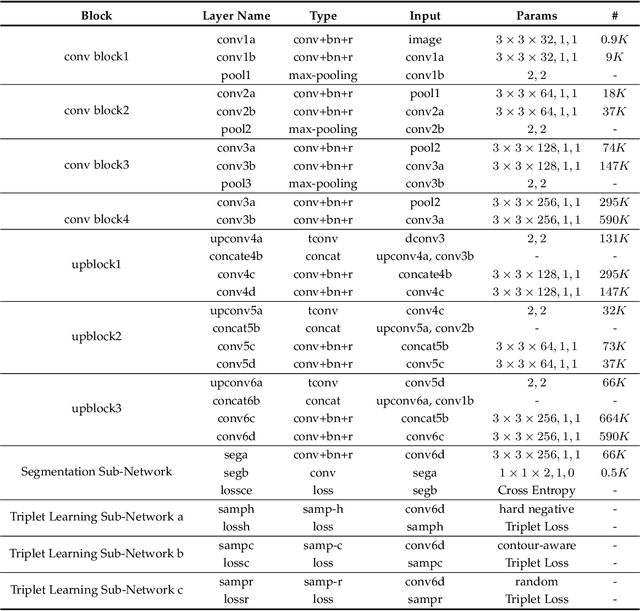
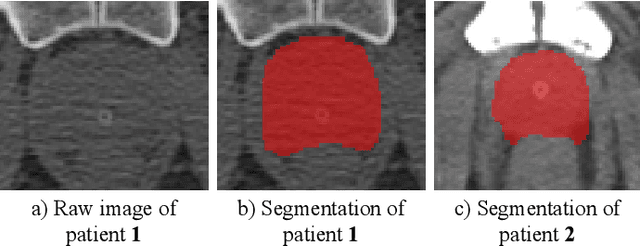
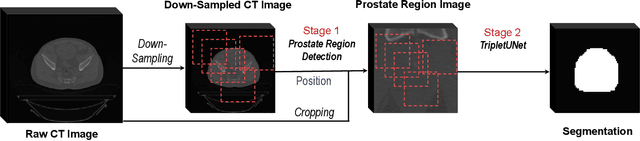
Fully convolutional networks (FCNs), including U-Net and V-Net, are widely-used network architecture for semantic segmentation in recent studies. However, conventional FCNs are typically trained by the cross-entropy loss or dice loss, in which the relationships among voxels are neglected. This often results in non-smooth neighborhoods in the output segmentation map. This problem becomes more serious in CT prostate segmentation as CT images are usually of low tissue contrast. To address this problem, we propose a two-stage framework. The first stage quickly localizes the prostate region. Then, the second stage precisely segments the prostate by a multi-task FCN-based on the U-Net architecture. We introduce a novel online voxel-triplet learning module through metric learning and voxel feature embeddings in the multi-task network. The proposed network has two branches guided by two tasks: 1) a segmentation sub-network aiming to generate prostate segmentation, and 2) a triplet learning sub-network aiming to improve the quality of the learned feature space supervised by a mixed of triplet and pair-wise loss function. The triplet learning sub-network samples triplets from the inter-mediate heatmap. Unlike conventional deep triplet learning methods that generate triplets before the training phase, our proposed voxel-triplets are sampled in an online manner and operates in an end-to-end fashion via multi-task learning. To evaluate the proposed method, we implement comprehensive experiments on a CT image dataset consisting of 339 patients. The ablation studies show that our method can effectively learn more representative voxel-level features compared with the conventional FCN network. And the comparisons show that the proposed method outperforms the state-of-the-art methods by a large margin.
Review of Artificial Intelligence Techniques in Imaging Data Acquisition, Segmentation and Diagnosis for COVID-19
Apr 07, 2020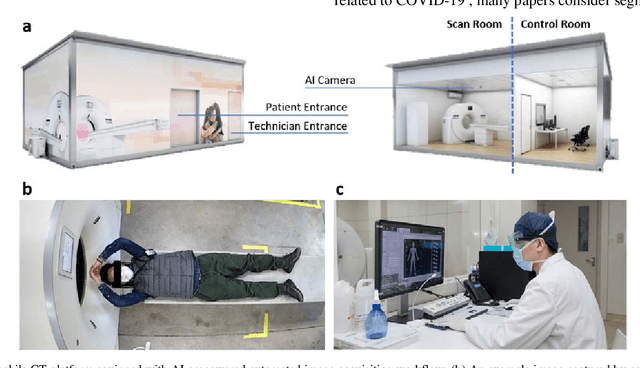
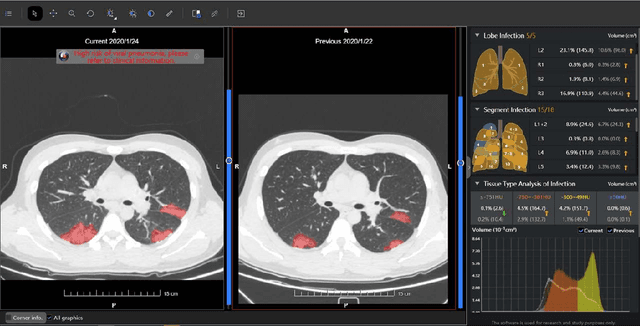
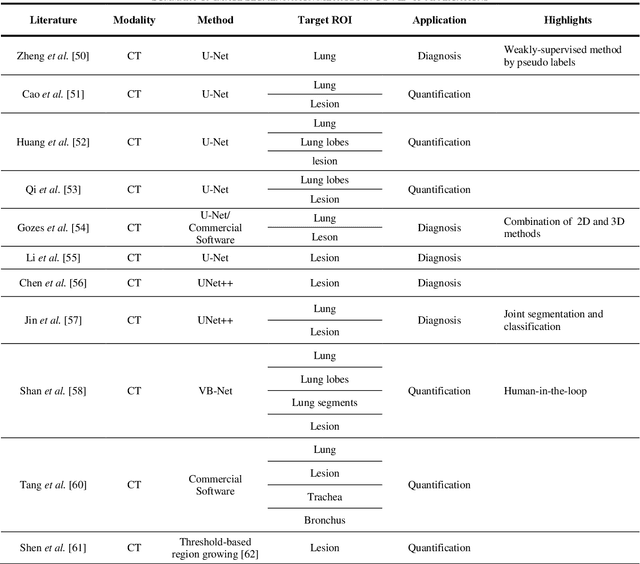
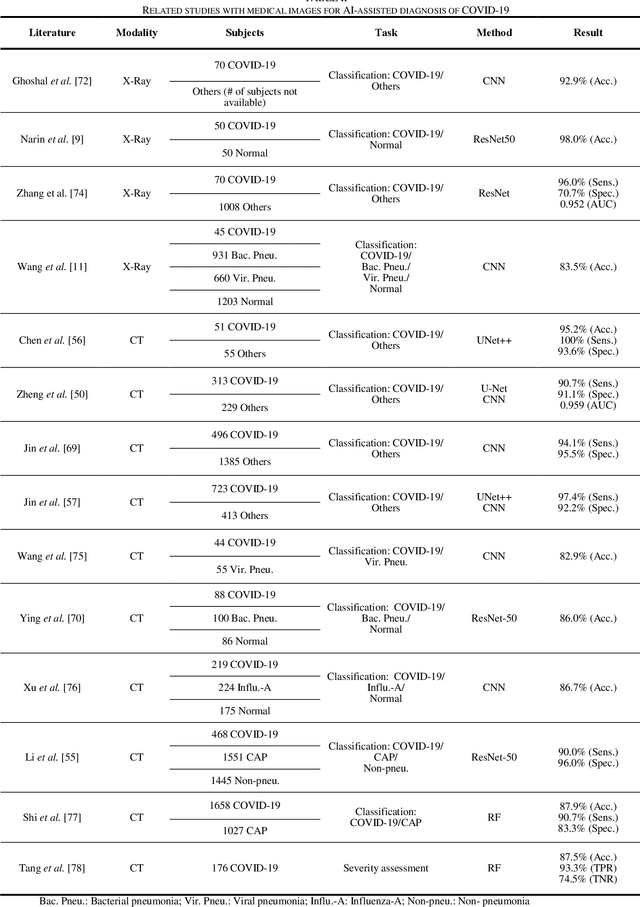
(This paper was submitted as an invited paper to IEEE Reviews in Biomedical Engineering on April 6, 2020.) The pandemic of coronavirus disease 2019 (COVID-19) is spreading all over the world. Medical imaging such as X-ray and computed tomography (CT) plays an essential role in the global fight against COVID-19, whereas the recently emerging artificial intelligence (AI) technologies further strengthen the power of the imaging tools and help medical specialists. We hereby review the rapid responses in the community of medical imaging (empowered by AI) toward COVID-19. For example, AI-empowered image acquisition can significantly help automate the scanning procedure and also reshape the workflow with minimal contact to patients, providing the best protection to the imaging technicians. Also, AI can improve work efficiency by accurate delination of infections in X-ray and CT images, facilitating subsequent quantification. Moreover, the computer-aided platforms help radiologists make clinical decisions, i.e., for disease diagnosis, tracking, and prognosis. In this review paper, we thus cover the entire pipeline of medical imaging and analysis techniques involved with COVID-19, including image acquisition, segmentation, diagnosis, and follow-up. We particularly focus on the integration of AI with X-ray and CT, both of which are widely used in the frontline hospitals, in order to depict the latest progress of medical imaging and radiology fighting against COVID-19.