 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanAlign: Post-hoc Semantic Calibration for VLM-Human Preference Alignment
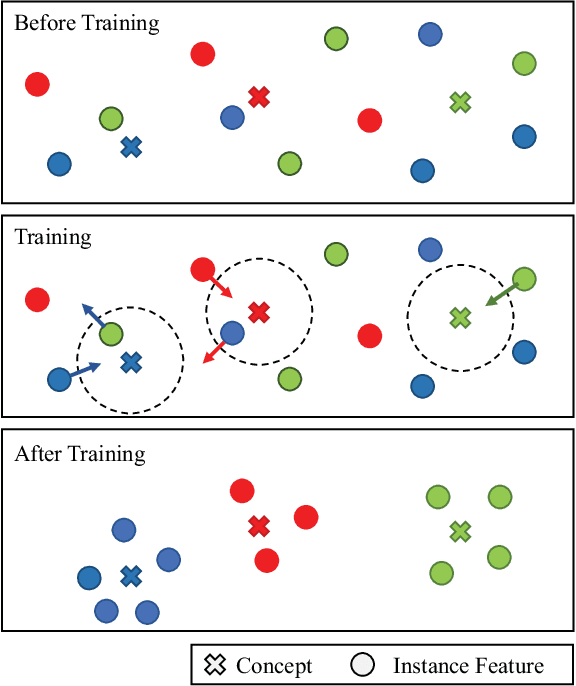
Feb 23, 2026Aligning vision-language model (VLM) outputs with human preferences in domain-specific tasks typically requires fine-tuning or reinforcement learning, both of which demand labelled data and GPU compute. We show that for subjective perception tasks, this alignment can be achieved without any model training: VLMs are already strong concept extractors but poor decision calibrators, and the gap can be closed externally. We propose a training-free post-hoc concept-bottleneck pipeline consisting of three tightly coupled stages: concept mining, multi-agent structured scoring, and geometric calibration, unified by an end-to-end dimension optimization loop. Interpretable evaluation dimensions are mined from a handful of human annotations; an Observer-Debater-Judge chain extracts robust continuous concept scores from a frozen VLM; and locally-weighted ridge regression on a hybrid visual-semantic manifold calibrates these scores against human ratings. Applied to urban perception as UrbanAlign, the framework achieves 72.2% accuracy ($κ=0.45$) on Place Pulse 2.0 across six categories, outperforming the best supervised baseline by +15.1 pp and uncalibrated VLM scoring by +16.3 pp, with full dimension-level interpretability and zero model-weight modification.
AIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection
Jan 08, 2026Multimodal large language models (MLLMs) demonstrate exceptional capabilities in semantic understanding and visual reasoning, yet they still face challenges in precise object localization and resource-constrained edge-cloud deployment. To address this, this paper proposes the AIVD framework, which achieves unified precise localization and high-quality semantic generation through the collaboration between lightweight edge detectors and cloud-based MLLMs. To enhance the cloud MLLM's robustness against edge cropped-box noise and scenario variations, we design an efficient fine-tuning strategy with visual-semantic collaborative augmentation, significantly improving classification accuracy and semantic consistency. Furthermore, to maintain high throughput and low latency across heterogeneous edge devices and dynamic network conditions, we propose a heterogeneous resource-aware dynamic scheduling algorithm. Experimental results demonstrate that AIVD substantially reduces resource consumption while improving MLLM classification performance and semantic generation quality. The proposed scheduling strategy also achieves higher throughput and lower latency across diverse scenarios.
ThinkDrive: Chain-of-Thought Guided Progressive Reinforcement Learning Fine-Tuning for Autonomous Driving
Jan 08, 2026With the rapid advancement of large language models (LLMs) technologies, their application in the domain of autonomous driving has become increasingly widespread. However, existing methods suffer from unstructured reasoning, poor generalization, and misalignment with human driving intent. While Chain-of-Thought (CoT) reasoning enhances decision transparency, conventional supervised fine-tuning (SFT) fails to fully exploit its potential, and reinforcement learning (RL) approaches face instability and suboptimal reasoning depth. We propose ThinkDrive, a CoT guided progressive RL fine-tuning framework for autonomous driving that synergizes explicit reasoning with difficulty-aware adaptive policy optimization. Our method employs a two-stage training strategy. First, we perform SFT using CoT explanations. Then, we apply progressive RL with a difficulty-aware adaptive policy optimizer that dynamically adjusts learning intensity based on sample complexity. We evaluate our approach on a public dataset. The results show that ThinkDrive outperforms strong RL baselines by 1.45%, 1.95%, and 1.01% on exam, easy-exam, and accuracy, respectively. Moreover, a 2B-parameter model trained with our method surpasses the much larger GPT-4o by 3.28% on the exam metric.
Fine-gained air quality inference based on low-quality sensing data using self-supervised learning
Aug 18, 2024



Fine-grained air quality (AQ) mapping is made possible by the proliferation of cheap AQ micro-stations (MSs). However, their measurements are often inaccurate and sensitive to local disturbances, in contrast to standardized stations (SSs) that provide accurate readings but fall short in number. To simultaneously address the issues of low data quality (MSs) and high label sparsity (SSs), a multi-task spatio-temporal network (MTSTN) is proposed, which employs self-supervised learning to utilize massive unlabeled data, aided by seasonal and trend decomposition of MS data offering reliable information as features. The MTSTN is applied to infer NO$_2$, O$_3$ and PM$_{2.5}$ concentrations in a 250 km$^2$ area in Chengdu, China, at a resolution of 500m$\times$500m$\times$1hr. Data from 55 SSs and 323 MSs were used, along with meteorological, traffic, geographic and timestamp data as features. The MTSTN excels in accuracy compared to several benchmarks, and its performance is greatly enhanced by utilizing low-quality MS data. A series of ablation and pressure tests demonstrate the results' robustness and interpretability, showcasing the MTSTN's practical value for accurate and affordable AQ inference.
Mixed-Precision Neural Network Quantization via Learned Layer-wise Importance
Mar 25, 2022
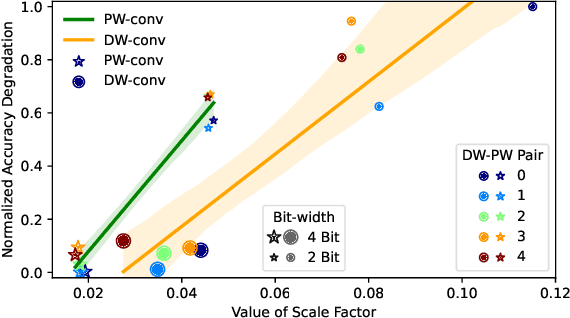

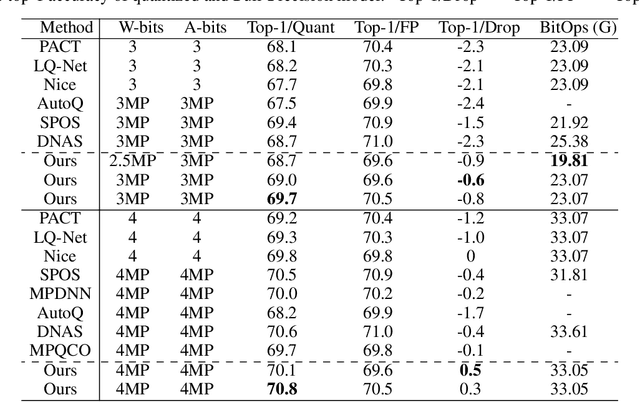
The exponentially large discrete search space in mixed-precision quantization (MPQ) makes it hard to determine the optimal bit-width for each layer. Previous works usually resort to iterative search methods on the training set, which consume hundreds or even thousands of GPU-hours. In this study, we reveal that some unique learnable parameters in quantization, namely the scale factors in the quantizer, can serve as importance indicators of a layer, reflecting the contribution of that layer to the final accuracy at certain bit-widths. These importance indicators naturally perceive the numerical transformation during quantization-aware training, which can precisely and correctly provide quantization sensitivity metrics of layers. However, a deep network always contains hundreds of such indicators, and training them one by one would lead to an excessive time cost. To overcome this issue, we propose a joint training scheme that can obtain all indicators at once. It considerably speeds up the indicators training process by parallelizing the original sequential training processes. With these learned importance indicators, we formulate the MPQ search problem as a one-time integer linear programming (ILP) problem. That avoids the iterative search and significantly reduces search time without limiting the bit-width search space. For example, MPQ search on ResNet18 with our indicators takes only 0.06 seconds. Also, extensive experiments show our approach can achieve SOTA accuracy on ImageNet for far-ranging models with various constraints (e.g., BitOps, compress rate).
Transformers in Medical Image Analysis: A Review
Feb 24, 2022
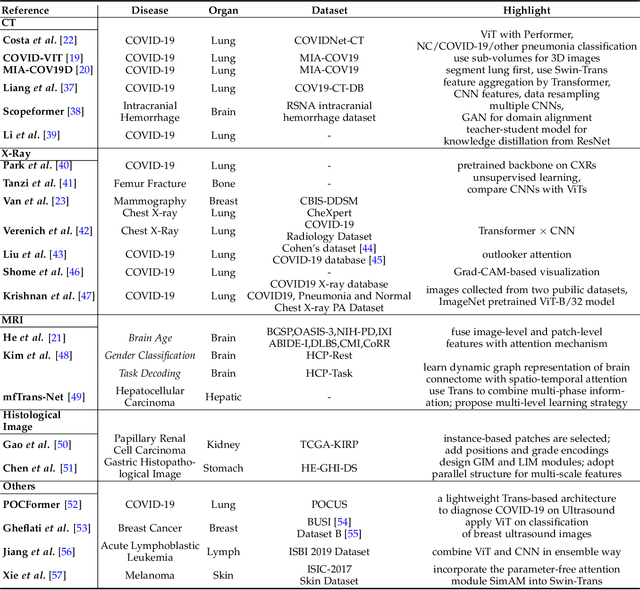
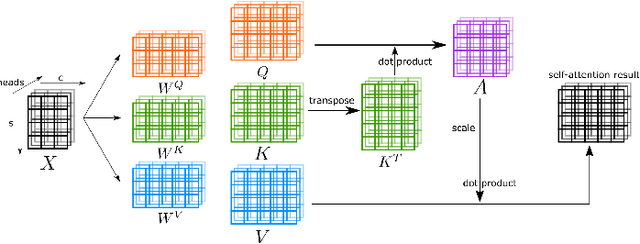
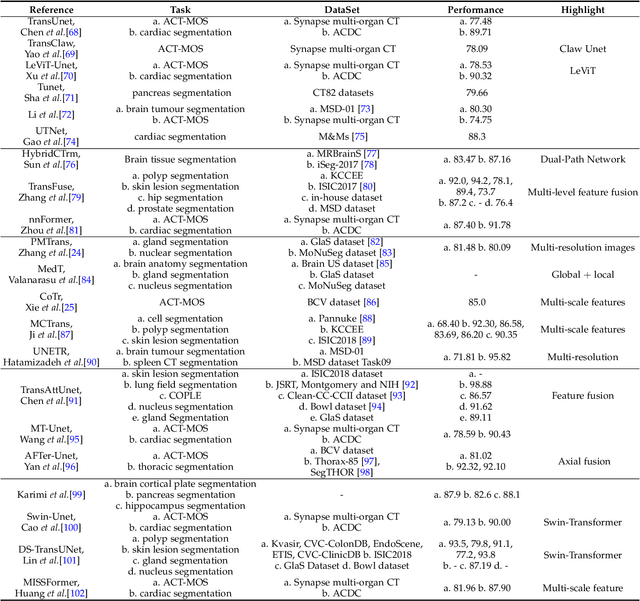
Transformers have dominated the field of natural language processing, and recently impacted the computer vision area. In the field of medical image analysis, Transformers have also been successfully applied to full-stack clinical applications, including image synthesis/reconstruction, registration, segmentation, detection, and diagnosis. Our paper presents both a position paper and a primer, promoting awareness and application of Transformers in the field of medical image analysis. Specifically, we first overview the core concepts of the attention mechanism built into Transformers and other basic components. Second, we give a new taxonomy of various Transformer architectures tailored for medical image applications and discuss their limitations. Within this review, we investigate key challenges revolving around the use of Transformers in different learning paradigms, improving the model efficiency, and their coupling with other techniques. We hope this review can give a comprehensive picture of Transformers to the readers in the field of medical image analysis.
Cross-Modality Brain Tumor Segmentation via Bidirectional Global-to-Local Unsupervised Domain Adaptation
May 17, 2021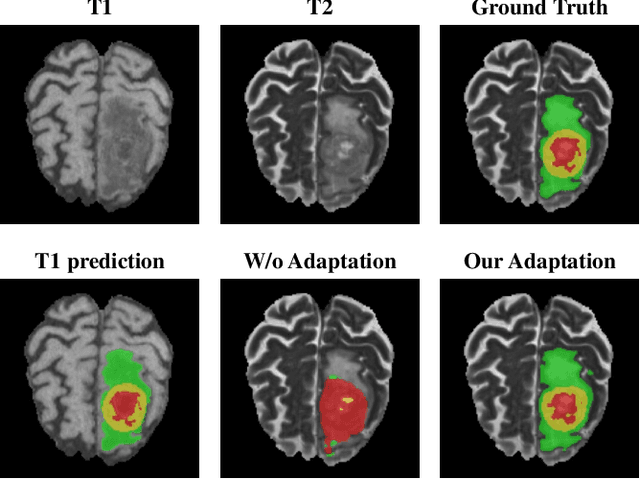
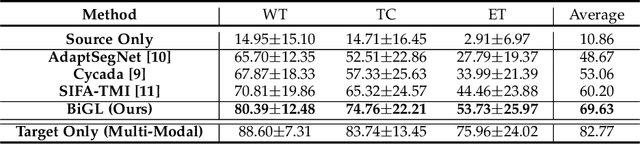
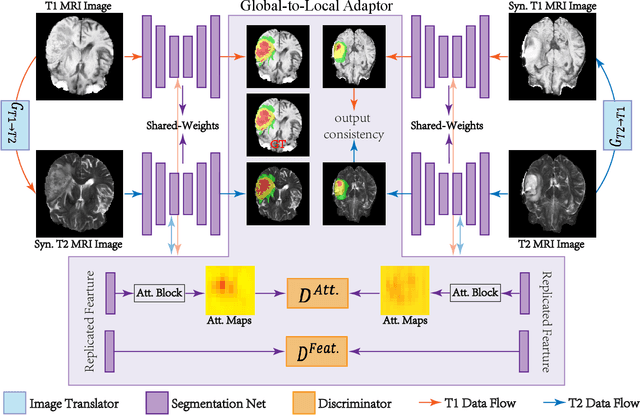
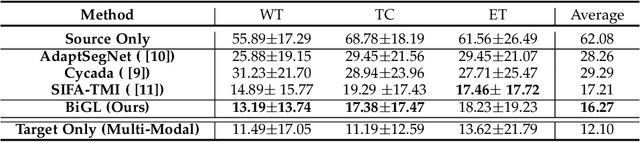
Accurate segmentation of brain tumors from multi-modal Magnetic Resonance (MR) images is essential in brain tumor diagnosis and treatment. However, due to the existence of domain shifts among different modalities, the performance of networks decreases dramatically when training on one modality and performing on another, e.g., train on T1 image while performing on T2 image, which is often required in clinical applications. This also prohibits a network from being trained on labeled data and then transferred to unlabeled data from a different domain. To overcome this, unsupervised domain adaptation (UDA) methods provide effective solutions to alleviate the domain shift between labeled source data and unlabeled target data. In this paper, we propose a novel Bidirectional Global-to-Local (BiGL) adaptation framework under a UDA scheme. Specifically, a bidirectional image synthesis and segmentation module is proposed to segment the brain tumor using the intermediate data distributions generated for the two domains, which includes an image-to-image translator and a shared-weighted segmentation network. Further, a global-to-local consistency learning module is proposed to build robust representation alignments in an integrated way. Extensive experiments on a multi-modal brain MR benchmark dataset demonstrate that the proposed method outperforms several state-of-the-art unsupervised domain adaptation methods by a large margin, while a comprehensive ablation study validates the effectiveness of each key component. The implementation code of our method will be released at \url{https://github.com/KeleiHe/BiGL}.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
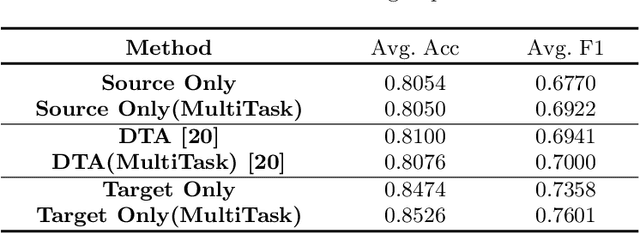
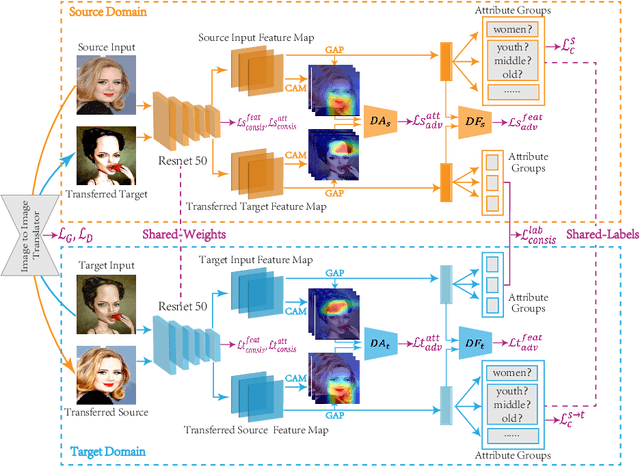
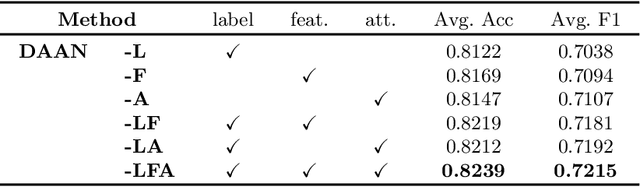
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.
Synergistic Learning of Lung Lobe Segmentation and Hierarchical Multi-Instance Classification for Automated Severity Assessment of COVID-19 in CT Images
May 24, 2020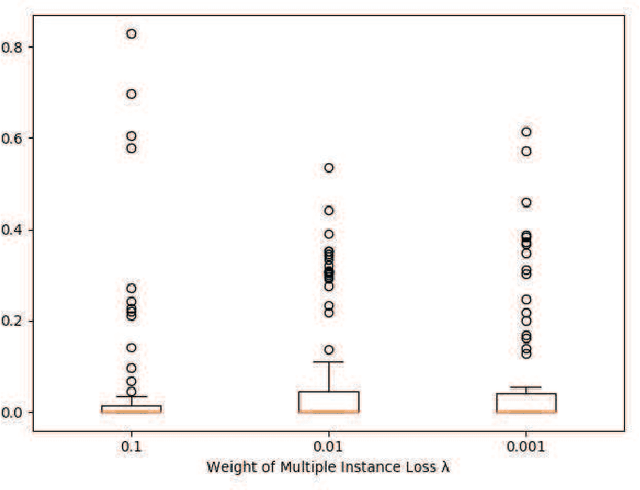
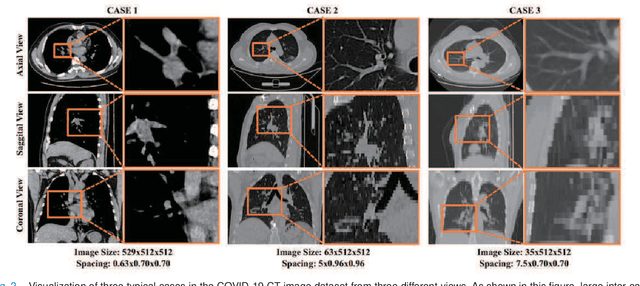
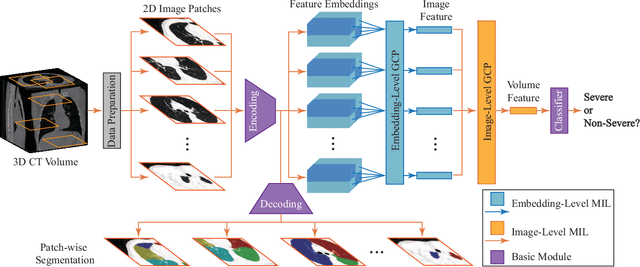
Understanding chest CT imaging of the coronavirus disease 2019 (COVID-19) will help detect infections early and assess the disease progression. Especially, automated severity assessment of COVID-19 in CT images plays an essential role in identifying cases that are in great need of intensive clinical care. However, it is often challenging to accurately assess the severity of this disease in CT images, due to variable infection regions in the lungs, similar imaging biomarkers, and large inter-case variations. To this end, we propose a synergistic learning framework for automated severity assessment of COVID-19 in 3D CT images, by jointly performing lung lobe segmentation and multi-instance classification. Considering that only a few infection regions in a CT image are related to the severity assessment, we first represent each input image by a bag that contains a set of 2D image patches (with each cropped from a specific slice). A multi-task multi-instance deep network (called M$^2$UNet) is then developed to assess the severity of COVID-19 patients and also segment the lung lobe simultaneously. Our M$^2$UNet consists of a patch-level encoder, a segmentation sub-network for lung lobe segmentation, and a classification sub-network for severity assessment (with a unique hierarchical multi-instance learning strategy). Here, the context information provided by segmentation can be implicitly employed to improve the performance of severity assessment. Extensive experiments were performed on a real COVID-19 CT image dataset consisting of 666 chest CT images, with results suggesting the effectiveness of our proposed method compared to several state-of-the-art methods.