 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoGraph: Temporal Knowledge Graph for Egocentric Video Understanding
Feb 27, 2026Ultra-long egocentric videos spanning multiple days present significant challenges for video understanding. Existing approaches still rely on fragmented local processing and limited temporal modeling, restricting their ability to reason over such extended sequences. To address these limitations, we introduce EgoGraph, a training-free and dynamic knowledge-graph construction framework that explicitly encodes long-term, cross-entity dependencies in egocentric video streams. EgoGraph employs a novel egocentric schema that unifies the extraction and abstraction of core entities, such as people, objects, locations, and events, and structurally reasons about their attributes and interactions, yielding a significantly richer and more coherent semantic representation than traditional clip-based video models. Crucially, we develop a temporal relational modeling strategy that captures temporal dependencies across entities and accumulates stable long-term memory over multiple days, enabling complex temporal reasoning. Extensive experiments on the EgoLifeQA and EgoR1-bench benchmarks demonstrate that EgoGraph achieves state-of-the-art performance on long-term video question answering, validating its effectiveness as a new paradigm for ultra-long egocentric video understanding.
Fine-gained air quality inference based on low-quality sensing data using self-supervised learning
Aug 18, 2024



Fine-grained air quality (AQ) mapping is made possible by the proliferation of cheap AQ micro-stations (MSs). However, their measurements are often inaccurate and sensitive to local disturbances, in contrast to standardized stations (SSs) that provide accurate readings but fall short in number. To simultaneously address the issues of low data quality (MSs) and high label sparsity (SSs), a multi-task spatio-temporal network (MTSTN) is proposed, which employs self-supervised learning to utilize massive unlabeled data, aided by seasonal and trend decomposition of MS data offering reliable information as features. The MTSTN is applied to infer NO$_2$, O$_3$ and PM$_{2.5}$ concentrations in a 250 km$^2$ area in Chengdu, China, at a resolution of 500m$\times$500m$\times$1hr. Data from 55 SSs and 323 MSs were used, along with meteorological, traffic, geographic and timestamp data as features. The MTSTN excels in accuracy compared to several benchmarks, and its performance is greatly enhanced by utilizing low-quality MS data. A series of ablation and pressure tests demonstrate the results' robustness and interpretability, showcasing the MTSTN's practical value for accurate and affordable AQ inference.
Big data analytics to classify earthwork-related locations: A Chengdu study
Feb 22, 2024



Air pollution has significantly intensified, leading to severe health consequences worldwide. Earthwork-related locations (ERLs) constitute significant sources of urban dust pollution. The effective management of ERLs has long posed challenges for governmental and environmental agencies, primarily due to their classification under different regulatory authorities, information barriers, delays in data updating, and a lack of dust suppression measures for various sources of dust pollution. To address these challenges, we classified urban dust pollution sources using dump truck trajectory, urban point of interest (POI), and land cover data. We compared several prediction models and investigated the relationship between features and dust pollution sources using real data. The results demonstrate that high-accuracy classification can be achieved with a limited number of features. This method was successfully implemented in the system called Alpha MAPS in Chengdu to provide decision support for urban pollution control.
Short-term prediction of construction waste transport activities using AI-Truck
Dec 07, 2023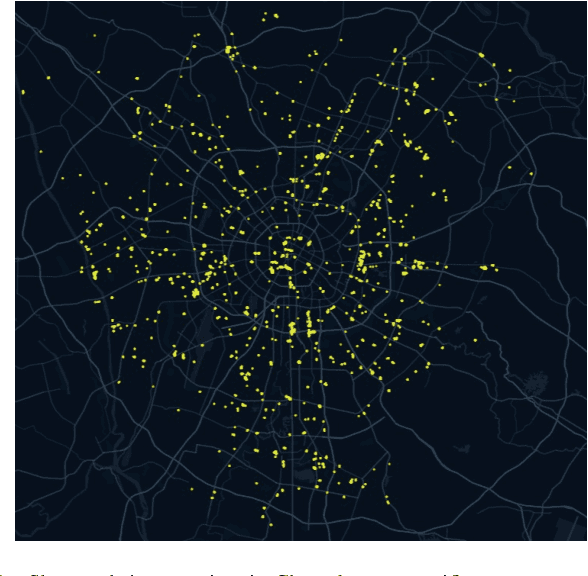
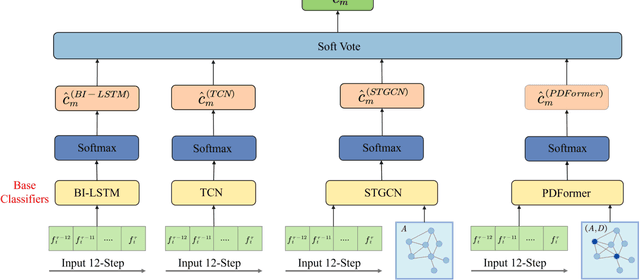
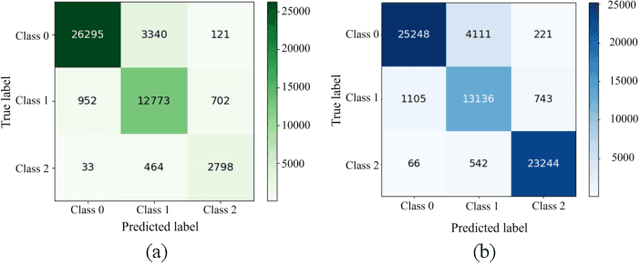
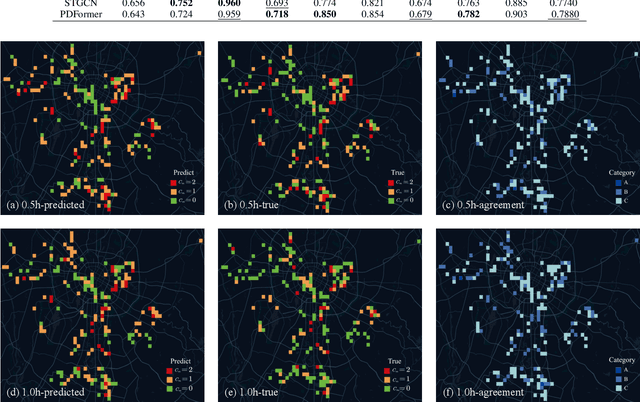
Construction waste hauling trucks (or `slag trucks') are among the most commonly seen heavy-duty vehicles in urban streets, which not only produce significant NOx and PM emissions but are also a major source of on-road and on-site fugitive dust. Slag trucks are subject to a series of spatial and temporal access restrictions by local traffic and environmental policies. This paper addresses the practical problem of predicting slag truck activity at a city scale during heavy pollution episodes, such that environmental law enforcement units can take timely and proactive measures against localized truck aggregation. A deep ensemble learning framework (coined AI-Truck) is designed, which employs a soft vote integrator that utilizes BI-LSTM, TCN, STGCN, and PDFormer as base classifiers to predict the level of slag truck activities at a resolution of 1km$\times$1km, in a 193 km$^2$ area in Chengdu, China. As a classifier, AI-Truck yields a Macro f1 close to 80\% for 0.5h- and 1h-prediction.
Predicting the Transportation Activities of Construction Waste Hauling Trucks: An Input-Output Hidden Markov Approach
Dec 06, 2023Construction waste hauling trucks (CWHTs), as one of the most commonly seen heavy-duty vehicles in major cities around the globe, are usually subject to a series of regulations and spatial-temporal access restrictions because they not only produce significant NOx and PM emissions but also causes on-road fugitive dust. The timely and accurate prediction of CWHTs' destinations and dwell times play a key role in effective environmental management. To address this challenge, we propose a prediction method based on an interpretable activity-based model, input-output hidden Markov model (IOHMM), and validate it on 300 CWHTs in Chengdu, China. Contextual factors are considered in the model to improve its prediction power. Results show that the IOHMM outperforms several baseline models, including Markov chains, linear regression, and long short-term memory. Factors influencing the predictability of CWHTs' transportation activities are also explored using linear regression models. Results suggest the proposed model holds promise in assisting authorities by predicting the upcoming transportation activities of CWHTs and administering intervention in a timely and effective manner.
Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
Mar 28, 2022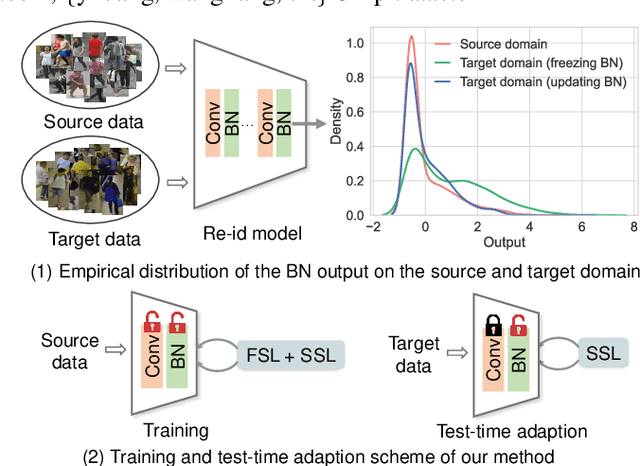
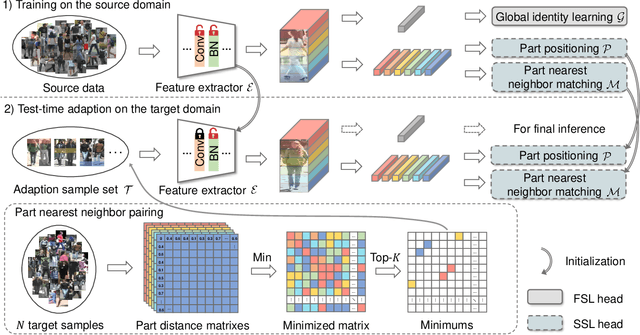
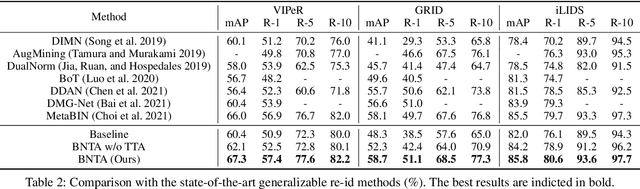
In this paper, we investigate the generalization problem of person re-identification (re-id), whose major challenge is the distribution shift on an unseen domain. As an important tool of regularizing the distribution, batch normalization (BN) has been widely used in existing methods. However, they neglect that BN is severely biased to the training domain and inevitably suffers the performance drop if directly generalized without being updated. To tackle this issue, we propose Batch Norm Test-time Adaption (BNTA), a novel re-id framework that applies the self-supervised strategy to update BN parameters adaptively. Specifically, BNTA quickly explores the domain-aware information within unlabeled target data before inference, and accordingly modulates the feature distribution normalized by BN to adapt to the target domain. This is accomplished by two designed self-supervised auxiliary tasks, namely part positioning and part nearest neighbor matching, which help the model mine the domain-aware information with respect to the structure and identity of body parts, respectively. To demonstrate the effectiveness of our method, we conduct extensive experiments on three re-id datasets and confirm the superior performance to the state-of-the-art methods.
Exploring Urban Air Quality with MAPS: Mobile Air Pollution Sensing
Apr 28, 2019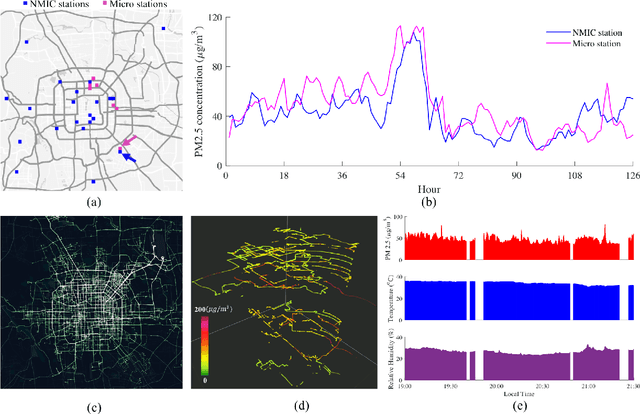
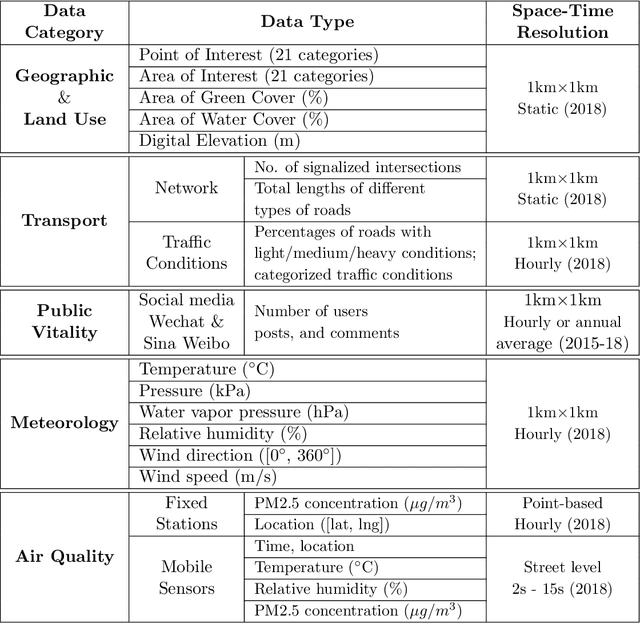
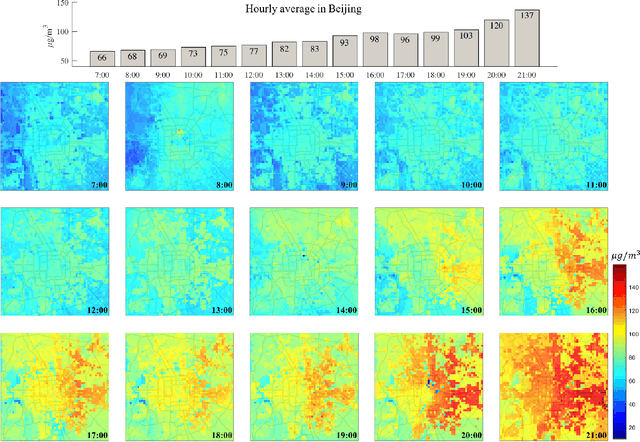
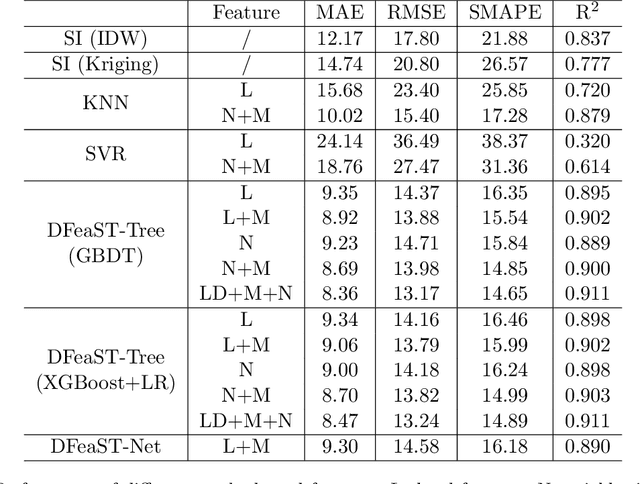
Mobile and ubiquitous sensing of urban air quality (AQ) has received increased attention as an economically and operationally viable means to survey atmospheric environment with high spatial-temporal resolution. A necessary and value-added step towards data-driven sustainable urban management is fine-granular AQ inference, which estimates grid-level pollutant concentrations at every instance of time using AQ data collected from fixed-location and mobile sensors. We present the Mobile Air Pollution Sensing (MAPS) framework, which consists of data preprocessing, urban feature extraction, and AQ inference. This is applied to a case study in Beijing (3,025 square km, 19 June - 16 July 2018), where PM2.5 concentrations measured by 28 fixed monitoring stations and 15 vehicles are fused to infer hourly PM2.5 concentrations in 3,025 1km-by-1km grids. Two machine learning structures, namely Deep Feature Spatial-Temporal Tree (DFeaST-Tree) and Deep Feature Spatial-Temporal Network (DFeaST-Net), are proposed to infer PM2.5 concentrations supported by 62 types of urban data that encompass geography, land use, traffic, public, and meteorology. This allows us to infer fine-granular PM2.5 concentrations based on sparse AQ measurements (less than 5% coverage) with good accuracy (SMAPE<15%, R-square>0.9), while accounting for the regional transport of air pollutants outside the study area. In-depth discussions are provided on the heterogeneity of fixed and mobile data sources, spatial coverage of mobile sensing, and importance of urban features for inferring PM2.5 concentrations.