 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdMix: A Mixed Sample Data Augmentation Method for Neural Machine Translation
May 10, 2022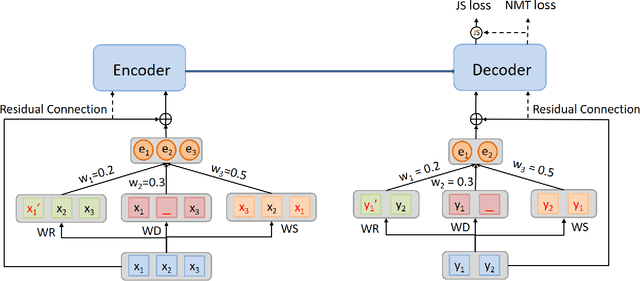
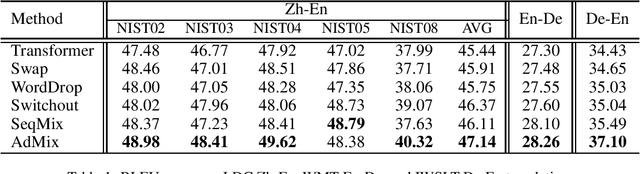
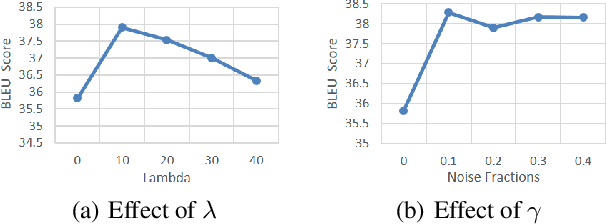
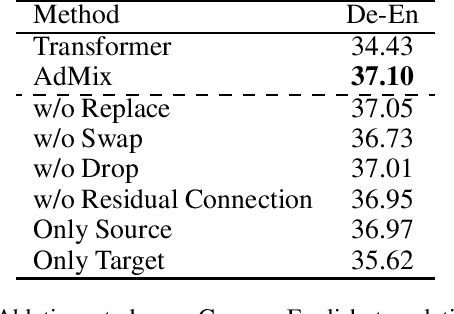
In Neural Machine Translation (NMT), data augmentation methods such as back-translation have proven their effectiveness in improving translation performance. In this paper, we propose a novel data augmentation approach for NMT, which is independent of any additional training data. Our approach, AdMix, consists of two parts: 1) introduce faint discrete noise (word replacement, word dropping, word swapping) into the original sentence pairs to form augmented samples; 2) generate new synthetic training data by softly mixing the augmented samples with their original samples in training corpus. Experiments on three translation datasets of different scales show that AdMix achieves signifi cant improvements (1.0 to 2.7 BLEU points) over strong Transformer baseline. When combined with other data augmentation techniques (e.g., back-translation), our approach can obtain further improvements.
Token Drop mechanism for Neural Machine Translation
Oct 21, 2020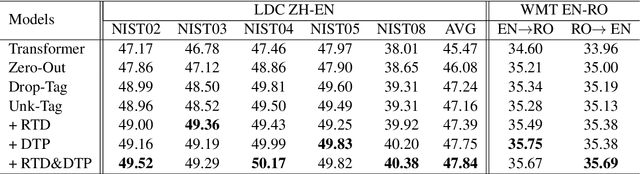
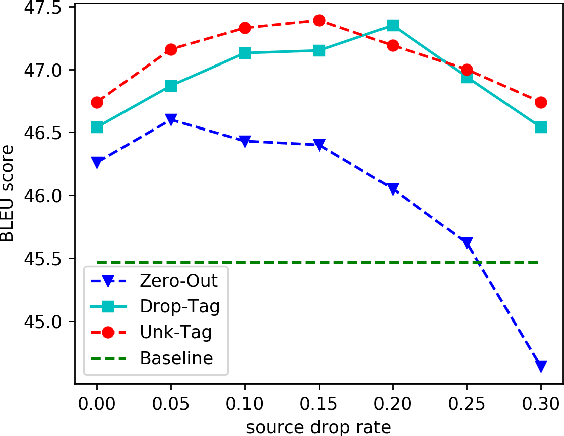
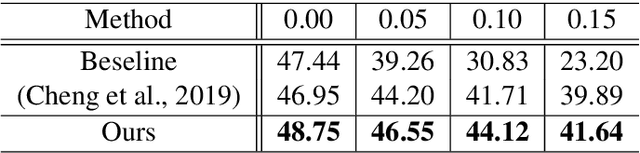
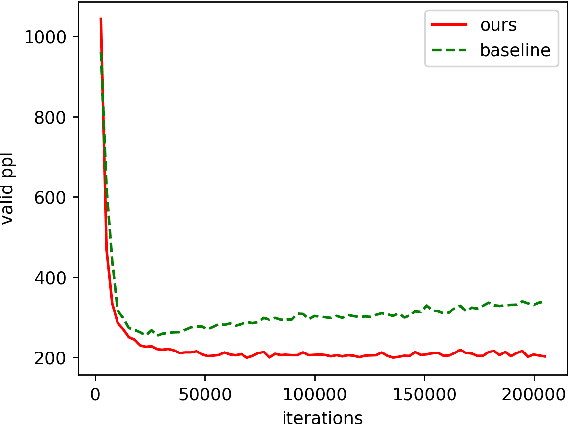
Neural machine translation with millions of parameters is vulnerable to unfamiliar inputs. We propose Token Drop to improve generalization and avoid overfitting for the NMT model. Similar to word dropout, whereas we replace dropped token with a special token instead of setting zero to words. We further introduce two self-supervised objectives: Replaced Token Detection and Dropped Token Prediction. Our method aims to force model generating target translation with less information, in this way the model can learn textual representation better. Experiments on Chinese-English and English-Romanian benchmark demonstrate the effectiveness of our approach and our model achieves significant improvements over a strong Transformer baseline.