 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANet: Bilateral Aggregation Network for Mobile Stereo Matching
Mar 05, 2025State-of-the-art stereo matching methods typically use costly 3D convolutions to aggregate a full cost volume, but their computational demands make mobile deployment challenging. Directly applying 2D convolutions for cost aggregation often results in edge blurring, detail loss, and mismatches in textureless regions. Some complex operations, like deformable convolutions and iterative warping, can partially alleviate this issue; however, they are not mobile-friendly, limiting their deployment on mobile devices. In this paper, we present a novel bilateral aggregation network (BANet) for mobile stereo matching that produces high-quality results with sharp edges and fine details using only 2D convolutions. Specifically, we first separate the full cost volume into detailed and smooth volumes using a spatial attention map, then perform detailed and smooth aggregations accordingly, ultimately fusing both to obtain the final disparity map. Additionally, to accurately identify high-frequency detailed regions and low-frequency smooth/textureless regions, we propose a new scale-aware spatial attention module. Experimental results demonstrate that our BANet-2D significantly outperforms other mobile-friendly methods, achieving 35.3\% higher accuracy on the KITTI 2015 leaderboard than MobileStereoNet-2D, with faster runtime on mobile devices. The extended 3D version, BANet-3D, achieves the highest accuracy among all real-time methods on high-end GPUs. Code: \textcolor{magenta}{https://github.com/gangweiX/BANet}.
MonSter: Marry Monodepth to Stereo Unleashes Power
Jan 15, 2025Stereo matching recovers depth from image correspondences. Existing methods struggle to handle ill-posed regions with limited matching cues, such as occlusions and textureless areas. To address this, we propose MonSter, a novel method that leverages the complementary strengths of monocular depth estimation and stereo matching. MonSter integrates monocular depth and stereo matching into a dual-branch architecture to iteratively improve each other. Confidence-based guidance adaptively selects reliable stereo cues for monodepth scale-shift recovery. The refined monodepth is in turn guides stereo effectively at ill-posed regions. Such iterative mutual enhancement enables MonSter to evolve monodepth priors from coarse object-level structures to pixel-level geometry, fully unlocking the potential of stereo matching. As shown in Fig.1, MonSter ranks 1st across five most commonly used leaderboards -- SceneFlow, KITTI 2012, KITTI 2015, Middlebury, and ETH3D. Achieving up to 49.5% improvements (Bad 1.0 on ETH3D) over the previous best method. Comprehensive analysis verifies the effectiveness of MonSter in ill-posed regions. In terms of zero-shot generalization, MonSter significantly and consistently outperforms state-of-the-art across the board. The code is publicly available at: https://github.com/Junda24/MonSter.
StereoGen: High-quality Stereo Image Generation from a Single Image
Jan 15, 2025State-of-the-art supervised stereo matching methods have achieved amazing results on various benchmarks. However, these data-driven methods suffer from generalization to real-world scenarios due to the lack of real-world annotated data. In this paper, we propose StereoGen, a novel pipeline for high-quality stereo image generation. This pipeline utilizes arbitrary single images as left images and pseudo disparities generated by a monocular depth estimation model to synthesize high-quality corresponding right images. Unlike previous methods that fill the occluded area in warped right images using random backgrounds or using convolutions to take nearby pixels selectively, we fine-tune a diffusion inpainting model to recover the background. Images generated by our model possess better details and undamaged semantic structures. Besides, we propose Training-free Confidence Generation and Adaptive Disparity Selection. The former suppresses the negative effect of harmful pseudo ground truth during stereo training, while the latter helps generate a wider disparity distribution and better synthetic images. Experiments show that models trained under our pipeline achieve state-of-the-art zero-shot generalization results among all published methods. The code will be available upon publication of the paper.
Attention-based Temporal Weighted Convolutional Neural Network for Action Recognition
Mar 19, 2018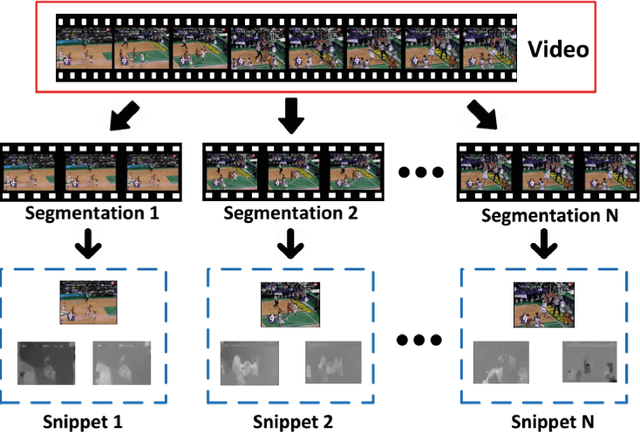

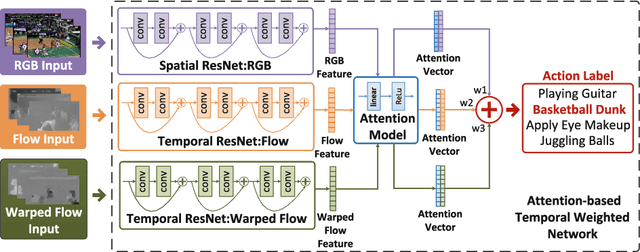
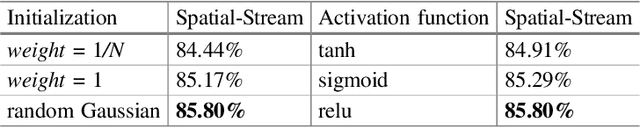
Research in human action recognition has accelerated significantly since the introduction of powerful machine learning tools such as Convolutional Neural Networks (CNNs). However, effective and efficient methods for incorporation of temporal information into CNNs are still being actively explored in the recent literature. Motivated by the popular recurrent attention models in the research area of natural language processing, we propose the Attention-based Temporal Weighted CNN (ATW), which embeds a visual attention model into a temporal weighted multi-stream CNN. This attention model is simply implemented as temporal weighting yet it effectively boosts the recognition performance of video representations. Besides, each stream in the proposed ATW framework is capable of end-to-end training, with both network parameters and temporal weights optimized by stochastic gradient descent (SGD) with backpropagation. Our experiments show that the proposed attention mechanism contributes substantially to the performance gains with the more discriminative snippets by focusing on more relevant video segments.