 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDST: Data Selection and joint Training for Learning with Noisy Labels
Mar 01, 2021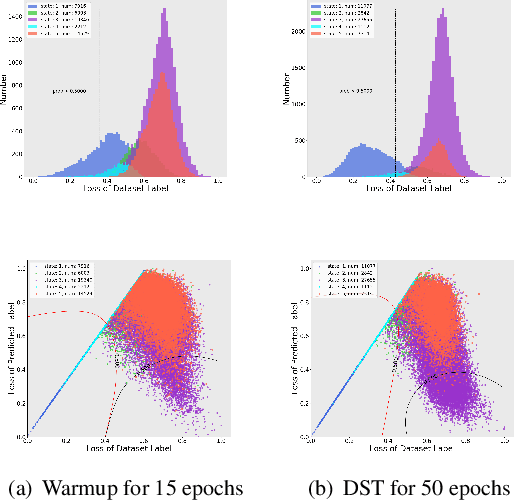
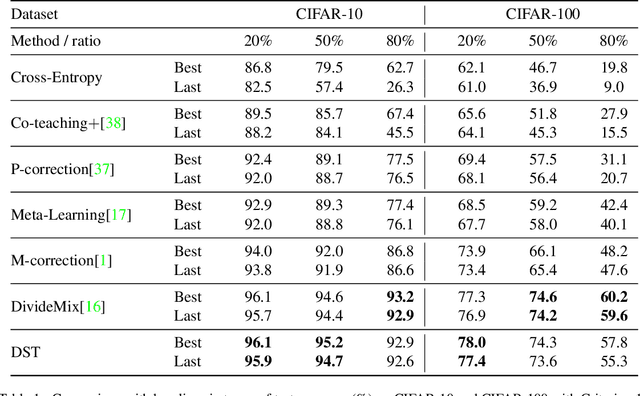
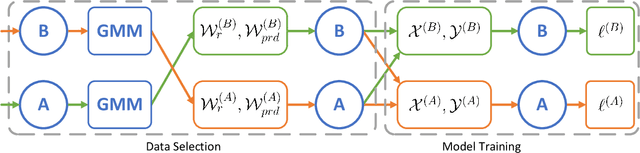
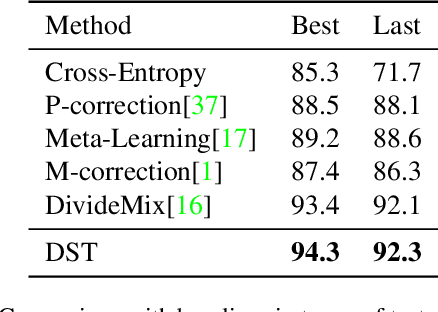
Training a deep neural network heavily relies on a large amount of training data with accurate annotations. To alleviate this problem, various methods have been proposed to annotate the data automatically. However, automatically generating annotations will inevitably yields noisy labels. In this paper, we propose a Data Selection and joint Training (DST) method to automatically select training samples with accurate annotations. Specifically, DST fits a mixture model according to the original annotation as well as the predicted label for each training sample, and the mixture model is utilized to dynamically divide the training dataset into a correctly labeled dataset, a correctly predicted set and a wrong dataset. Then, DST is trained with these datasets in a supervised manner. Due to confirmation bias problem, we train the two networks alternately, and each network is tasked to establish the data division to teach another network. For each iteration, the correctly labeled and predicted labels are reweighted respectively by the probabilities from the mixture model, and a uniform distribution is used to generate the probabilities of the wrong samples. Experiments on CIFAR-10, CIFAR-100 and Clothing1M demonstrate that DST is the comparable or superior to the state-of-the-art methods.
Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection
Jan 25, 2019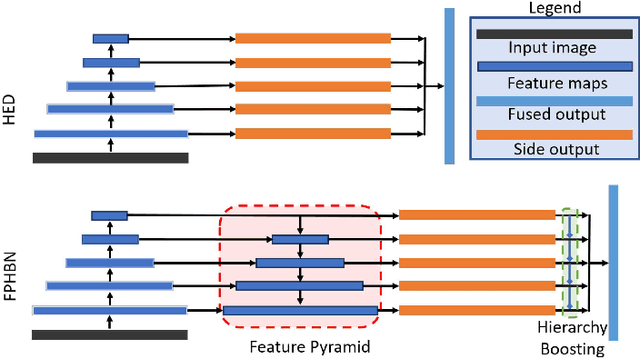



Pavement crack detection is a critical task for insuring road safety. Manual crack detection is extremely time-consuming. Therefore, an automatic road crack detection method is required to boost this progress. However, it remains a challenging task due to the intensity inhomogeneity of cracks and complexity of the background, e.g., the low contrast with surrounding pavements and possible shadows with similar intensity. Inspired by recent advances of deep learning in computer vision, we propose a novel network architecture, named Feature Pyramid and Hierarchical Boosting Network (FPHBN), for pavement crack detection. The proposed network integrates semantic information to low-level features for crack detection in a feature pyramid way. And, it balances the contribution of both easy and hard samples to loss by nested sample reweighting in a hierarchical way. To demonstrate the superiority and generality of the proposed method, we evaluate the proposed method on five crack datasets and compare it with state-of-the-art crack detection, edge detection, semantic segmentation methods. Extensive experiments show that the proposed method outperforms these state-of-the-art methods in terms of accuracy and generality.
Multi-level Contextual RNNs with Attention Model for Scene Labeling
Aug 10, 2016
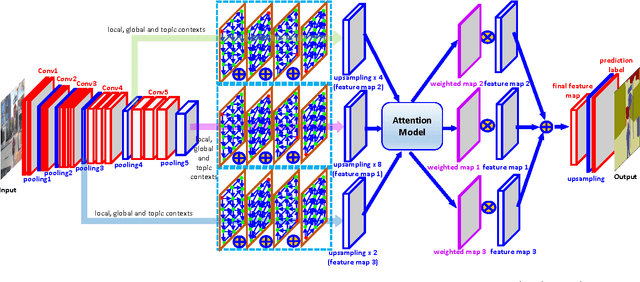

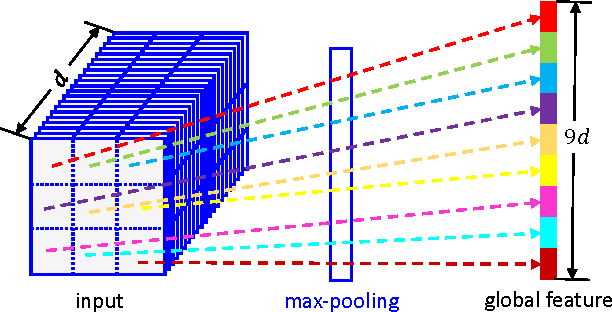
Context in image is crucial for scene labeling while existing methods only exploit local context generated from a small surrounding area of an image patch or a pixel, by contrast long-range and global contextual information is ignored. To handle this issue, we in this work propose a novel approach for scene labeling by exploring multi-level contextual recurrent neural networks (ML-CRNNs). Specifically, we encode three kinds of contextual cues, i.e., local context, global context and image topic context in structural recurrent neural networks (RNNs) to model long-range local and global dependencies in image. In this way, our method is able to `see' the image in terms of both long-range local and holistic views, and make a more reliable inference for image labeling. Besides, we integrate the proposed contextual RNNs into hierarchical convolutional neural networks (CNNs), and exploit dependence relationships in multiple levels to provide rich spatial and semantic information. Moreover, we novelly adopt an attention model to effectively merge multiple levels and show that it outperforms average- or max-pooling fusion strategies. Extensive experiments demonstrate that the proposed approach achieves new state-of-the-art results on the CamVid, SiftFlow and Stanford-background datasets.
Adaptive Objectness for Object Tracking
Jan 05, 2015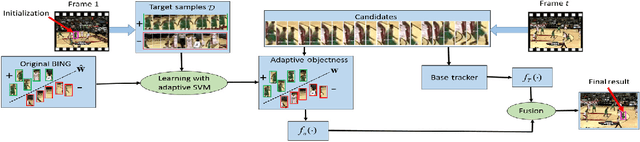

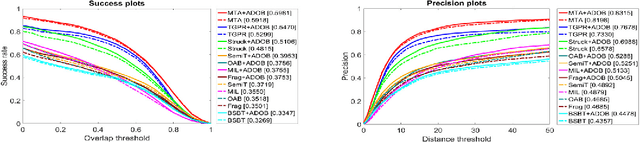

Object tracking is a long standing problem in vision. While great efforts have been spent to improve tracking performance, a simple yet reliable prior knowledge is left unexploited: the target object in tracking must be an object other than non-object. The recently proposed and popularized objectness measure provides a natural way to model such prior in visual tracking. Thus motivated, in this paper we propose to adapt objectness for visual object tracking. Instead of directly applying an existing objectness measure that is generic and handles various objects and environments, we adapt it to be compatible to the specific tracking sequence and object. More specifically, we use the newly proposed BING objectness as the base, and then train an object-adaptive objectness for each tracking task. The training is implemented by using an adaptive support vector machine that integrates information from the specific tracking target into the BING measure. We emphasize that the benefit of the proposed adaptive objectness, named ADOBING, is generic. To show this, we combine ADOBING with seven top performed trackers in recent evaluations. We run the ADOBING-enhanced trackers with their base trackers on two popular benchmarks, the CVPR2013 benchmark (50 sequences) and the Princeton Tracking Benchmark (100 sequences). On both benchmarks, our methods not only consistently improve the base trackers, but also achieve the best known performances. Noting that the way we integrate objectness in visual tracking is generic and straightforward, we expect even more improvement by using tracker-specific objectness.