 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Contextual RNNs with Attention Model for Scene Labeling
Paper and Code
Aug 10, 2016
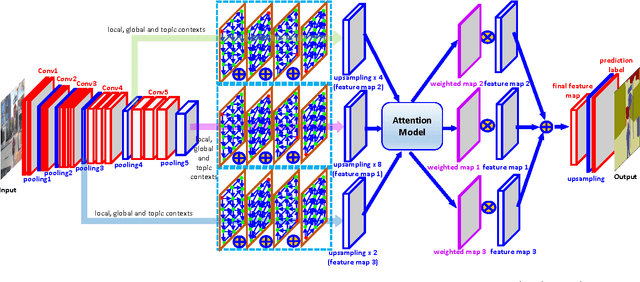

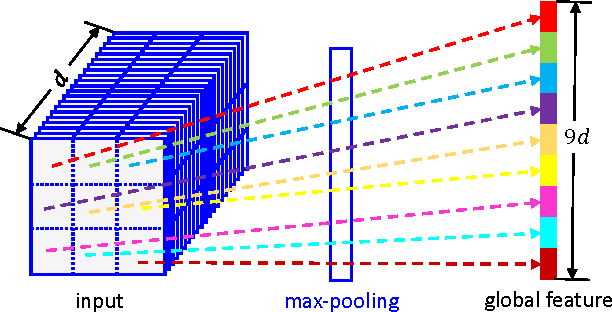
Context in image is crucial for scene labeling while existing methods only exploit local context generated from a small surrounding area of an image patch or a pixel, by contrast long-range and global contextual information is ignored. To handle this issue, we in this work propose a novel approach for scene labeling by exploring multi-level contextual recurrent neural networks (ML-CRNNs). Specifically, we encode three kinds of contextual cues, i.e., local context, global context and image topic context in structural recurrent neural networks (RNNs) to model long-range local and global dependencies in image. In this way, our method is able to `see' the image in terms of both long-range local and holistic views, and make a more reliable inference for image labeling. Besides, we integrate the proposed contextual RNNs into hierarchical convolutional neural networks (CNNs), and exploit dependence relationships in multiple levels to provide rich spatial and semantic information. Moreover, we novelly adopt an attention model to effectively merge multiple levels and show that it outperforms average- or max-pooling fusion strategies. Extensive experiments demonstrate that the proposed approach achieves new state-of-the-art results on the CamVid, SiftFlow and Stanford-background datasets.