 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDST: Data Selection and joint Training for Learning with Noisy Labels
Paper and Code
Mar 01, 2021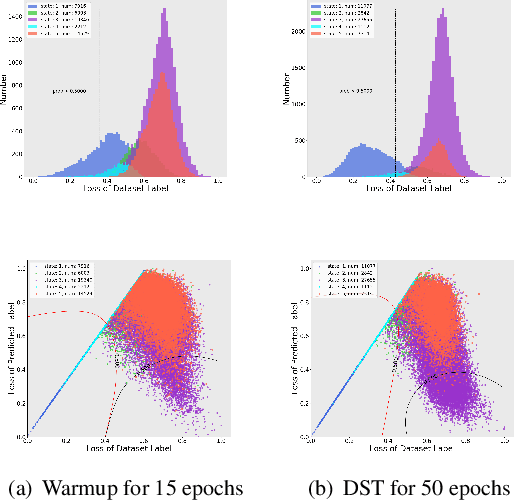
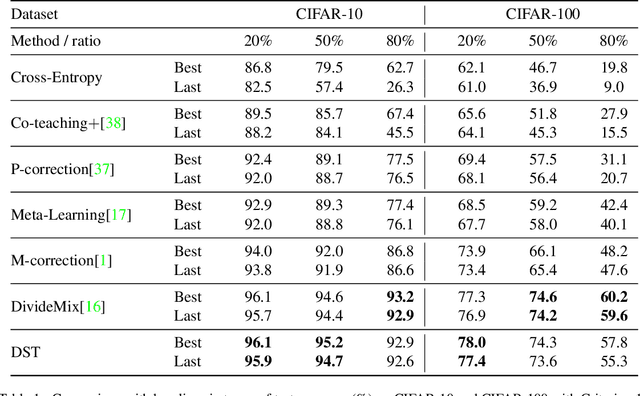
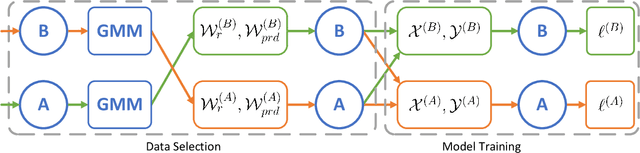
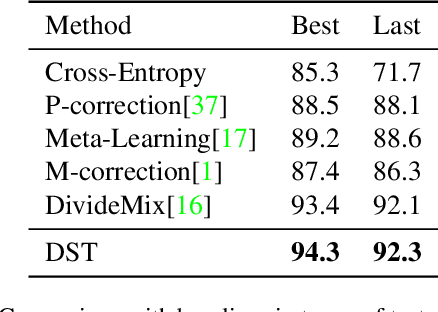
Training a deep neural network heavily relies on a large amount of training data with accurate annotations. To alleviate this problem, various methods have been proposed to annotate the data automatically. However, automatically generating annotations will inevitably yields noisy labels. In this paper, we propose a Data Selection and joint Training (DST) method to automatically select training samples with accurate annotations. Specifically, DST fits a mixture model according to the original annotation as well as the predicted label for each training sample, and the mixture model is utilized to dynamically divide the training dataset into a correctly labeled dataset, a correctly predicted set and a wrong dataset. Then, DST is trained with these datasets in a supervised manner. Due to confirmation bias problem, we train the two networks alternately, and each network is tasked to establish the data division to teach another network. For each iteration, the correctly labeled and predicted labels are reweighted respectively by the probabilities from the mixture model, and a uniform distribution is used to generate the probabilities of the wrong samples. Experiments on CIFAR-10, CIFAR-100 and Clothing1M demonstrate that DST is the comparable or superior to the state-of-the-art methods.