 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHINO: Learning Real-Time Humanoid-Human-Object Interaction from Human Demonstrations
Feb 18, 2025



Humanoid robots have shown success in locomotion and manipulation. Despite these basic abilities, humanoids are still required to quickly understand human instructions and react based on human interaction signals to become valuable assistants in human daily life. Unfortunately, most existing works only focus on multi-stage interactions, treating each task separately, and neglecting real-time feedback. In this work, we aim to empower humanoid robots with real-time reaction abilities to achieve various tasks, allowing human to interrupt robots at any time, and making robots respond to humans immediately. To support such abilities, we propose a general humanoid-human-object interaction framework, named RHINO, i.e., Real-time Humanoid-human Interaction and Object manipulation. RHINO provides a unified view of reactive motion, instruction-based manipulation, and safety concerns, over multiple human signal modalities, such as languages, images, and motions. RHINO is a hierarchical learning framework, enabling humanoids to learn reaction skills from human-human-object demonstrations and teleoperation data. In particular, it decouples the interaction process into two levels: 1) a high-level planner inferring human intentions from real-time human behaviors; and 2) a low-level controller achieving reactive motion behaviors and object manipulation skills based on the predicted intentions. We evaluate the proposed framework on a real humanoid robot and demonstrate its effectiveness, flexibility, and safety in various scenarios.
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Dec 18, 2024Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
Looking Ahead to Avoid Being Late: Solving Hard-Constrained Traveling Salesman Problem
Mar 08, 2024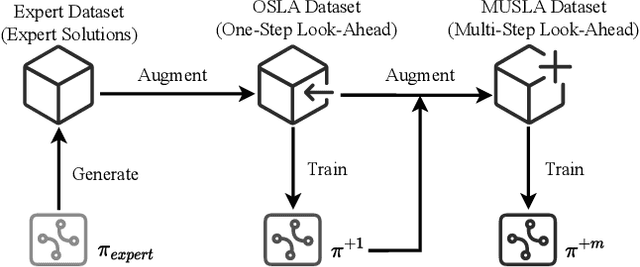
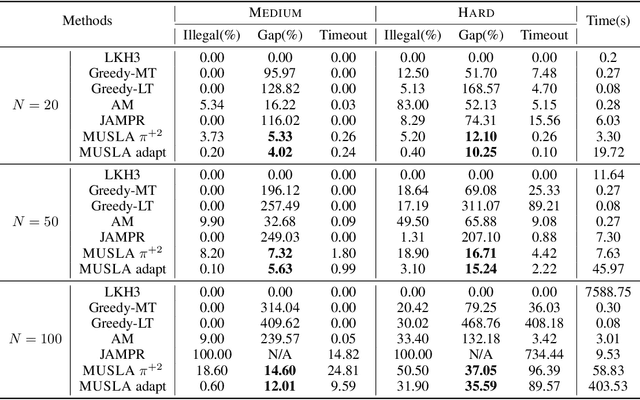
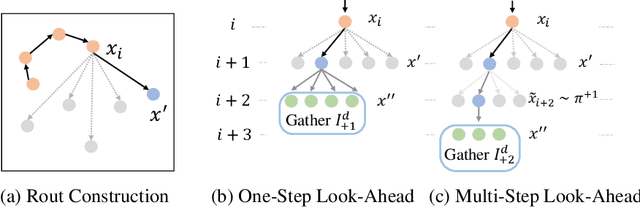
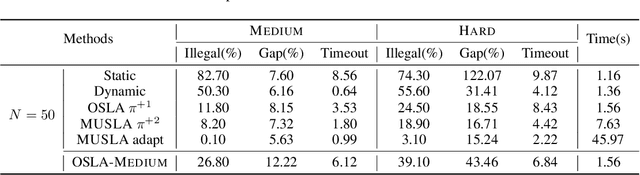
Many real-world problems can be formulated as a constrained Traveling Salesman Problem (TSP). However, the constraints are always complex and numerous, making the TSPs challenging to solve. When the number of complicated constraints grows, it is time-consuming for traditional heuristic algorithms to avoid illegitimate outcomes. Learning-based methods provide an alternative to solve TSPs in a soft manner, which also supports GPU acceleration to generate solutions quickly. Nevertheless, the soft manner inevitably results in difficulty solving hard-constrained problems with learning algorithms, and the conflicts between legality and optimality may substantially affect the optimality of the solution. To overcome this problem and to have an effective solution against hard constraints, we proposed a novel learning-based method that uses looking-ahead information as the feature to improve the legality of TSP with Time Windows (TSPTW) solutions. Besides, we constructed TSPTW datasets with hard constraints in order to accurately evaluate and benchmark the statistical performance of various approaches, which can serve the community for future research. With comprehensive experiments on diverse datasets, MUSLA outperforms existing baselines and shows generalizability potential.
Offline Fictitious Self-Play for Competitive Games
Feb 29, 2024



Offline Reinforcement Learning (RL) has received significant interest due to its ability to improve policies in previously collected datasets without online interactions. Despite its success in the single-agent setting, offline multi-agent RL remains a challenge, especially in competitive games. Firstly, unaware of the game structure, it is impossible to interact with the opponents and conduct a major learning paradigm, self-play, for competitive games. Secondly, real-world datasets cannot cover all the state and action space in the game, resulting in barriers to identifying Nash equilibrium (NE). To address these issues, this paper introduces Off-FSP, the first practical model-free offline RL algorithm for competitive games. We start by simulating interactions with various opponents by adjusting the weights of the fixed dataset with importance sampling. This technique allows us to learn best responses to different opponents and employ the Offline Self-Play learning framework. In this framework, we further implement Fictitious Self-Play (FSP) to approximate NE. In partially covered real-world datasets, our methods show the potential to approach NE by incorporating any single-agent offline RL method. Experimental results in Leduc Hold'em Poker show that our method significantly improves performances compared with state-of-the-art baselines.
Quantifying Zero-shot Coordination Capability with Behavior Preferring Partners
Oct 08, 2023



Zero-shot coordination (ZSC) is a new challenge focusing on generalizing learned coordination skills to unseen partners. Existing methods train the ego agent with partners from pre-trained or evolving populations. The agent's ZSC capability is typically evaluated with a few evaluation partners, including human and agent, and reported by mean returns. Current evaluation methods for ZSC capability still need to improve in constructing diverse evaluation partners and comprehensively measuring the ZSC capability. We aim to create a reliable, comprehensive, and efficient evaluation method for ZSC capability. We formally define the ideal 'diversity-complete' evaluation partners and propose the best response (BR) diversity, which is the population diversity of the BRs to the partners, to approximate the ideal evaluation partners. We propose an evaluation workflow including 'diversity-complete' evaluation partners construction and a multi-dimensional metric, the Best Response Proximity (BR-Prox) metric. BR-Prox quantifies the ZSC capability as the performance similarity to each evaluation partner's approximate best response, demonstrating generalization capability and improvement potential. We re-evaluate strong ZSC methods in the Overcooked environment using the proposed evaluation workflow. Surprisingly, the results in some of the most used layouts fail to distinguish the performance of different ZSC methods. Moreover, the evaluated ZSC methods must produce more diverse and high-performing training partners. Our proposed evaluation workflow calls for a change in how we efficiently evaluate ZSC methods as a supplement to human evaluation.
On Realization of Intelligent Decision-Making in the Real World: A Foundation Decision Model Perspective
Dec 24, 2022Our situated environment is full of uncertainty and highly dynamic, thus hindering the widespread adoption of machine-led Intelligent Decision-Making (IDM) in real world scenarios. This means IDM should have the capability of continuously learning new skills and efficiently generalizing across wider applications. IDM benefits from any new approaches and theoretical breakthroughs that exhibit Artificial General Intelligence (AGI) breaking the barriers between tasks and applications. Recent research has well-examined neural architecture, Transformer, as a backbone foundation model and its generalization to various tasks, including computer vision, natural language processing, and reinforcement learning. We therefore argue that a foundation decision model (FDM) can be established by formulating various decision-making tasks as a sequence decoding task using the Transformer architecture; this would be a promising solution to advance the applications of IDM in more complex real world tasks. In this paper, we elaborate on how a foundation decision model improves the efficiency and generalization of IDM. We also discuss potential applications of a FDM in multi-agent game AI, production scheduling, and robotics tasks. Finally, through a case study, we demonstrate our realization of the FDM, DigitalBrain (DB1) with 1.2 billion parameters, which achieves human-level performance over 453 tasks, including text generation, images caption, video games playing, robotic control, and traveling salesman problems. As a foundation decision model, DB1 would be a baby step towards more autonomous and efficient real world IDM applications.
Honor of Kings Arena: an Environment for Generalization in Competitive Reinforcement Learning
Oct 09, 2022
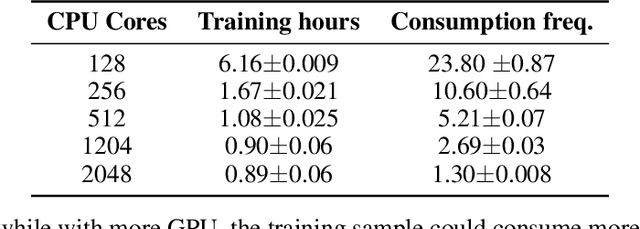

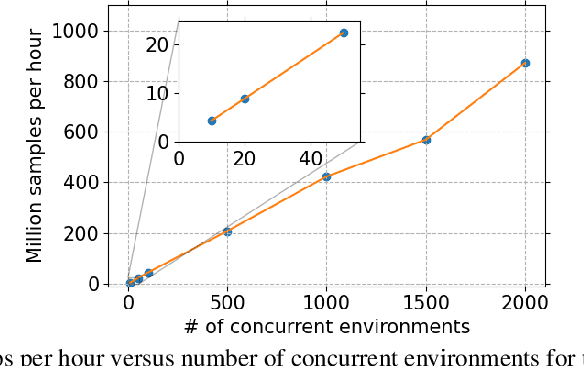
This paper introduces Honor of Kings Arena, a reinforcement learning (RL) environment based on Honor of Kings, one of the world's most popular games at present. Compared to other environments studied in most previous work, ours presents new generalization challenges for competitive reinforcement learning. It is a multi-agent problem with one agent competing against its opponent; and it requires the generalization ability as it has diverse targets to control and diverse opponents to compete with. We describe the observation, action, and reward specifications for the Honor of Kings domain and provide an open-source Python-based interface for communicating with the game engine. We provide twenty target heroes with a variety of tasks in Honor of Kings Arena and present initial baseline results for RL-based methods with feasible computing resources. Finally, we showcase the generalization challenges imposed by Honor of Kings Arena and possible remedies to the challenges. All of the software, including the environment-class, are publicly available at https://github.com/tencent-ailab/hok_env . The documentation is available at https://aiarena.tencent.com/hok/doc/ .
Efficient Policy Space Response Oracles
Feb 17, 2022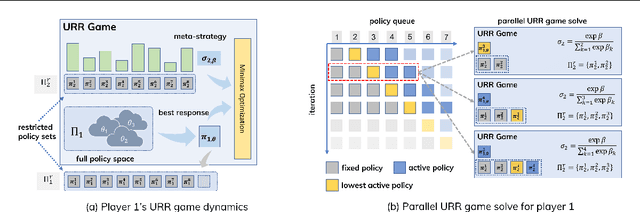
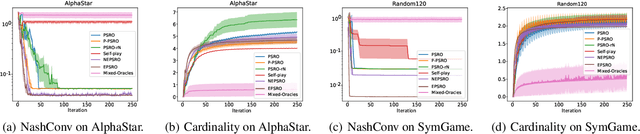
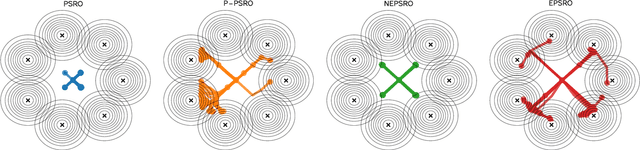
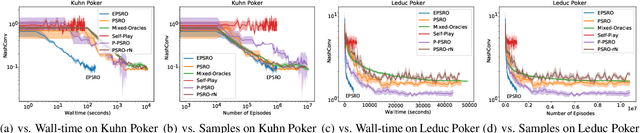
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
Generating Strategic Dialogue for Negotiation with Theory of Mind
Oct 20, 2020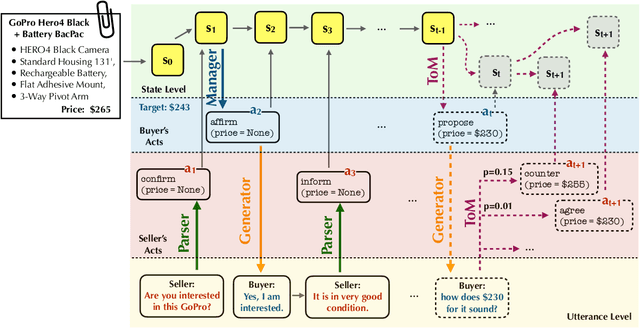

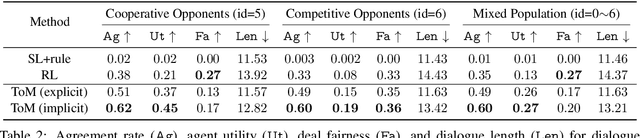
We propose a framework to integrate the concept of Theory of Mind (ToM) into generating utterances for task-oriented dialogue. Our approach explores the ability to model and infer personality types of opponents, predicts their responses, and uses this information to adapt the agent's high-level strategy in negotiation tasks. We introduce a probabilistic formulation for the first-order theory of mind and test our approach on the CraigslistBargain dataset. Experiments show that our method using ToM inference achieves a 40\% higher dialogue agreement rate compared to baselines on a mixed population of opponents. We also show that our model displays diverse negotiation behavior with different types of opponents.