 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and General Whole-Body Control for Cross-Humanoid Locomotion
Feb 05, 2026Learning-based whole-body controllers have become a key driver for humanoid robots, yet most existing approaches require robot-specific training. In this paper, we study the problem of cross-embodiment humanoid control and show that a single policy can robustly generalize across a wide range of humanoid robot designs with one-time training. We introduce XHugWBC, a novel cross-embodiment training framework that enables generalist humanoid control through: (1) physics-consistent morphological randomization, (2) semantically aligned observation and action spaces across diverse humanoid robots, and (3) effective policy architectures modeling morphological and dynamical properties. XHugWBC is not tied to any specific robot. Instead, it internalizes a broad distribution of morphological and dynamical characteristics during training. By learning motion priors from diverse randomized embodiments, the policy acquires a strong structural bias that supports zero-shot transfer to previously unseen robots. Experiments on twelve simulated humanoids and seven real-world robots demonstrate the strong generalization and robustness of the resulting universal controller.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Jan 30, 2026Achieving human-level competitive intelligence and physical agility in humanoid robots remains a major challenge, particularly in contact-rich and highly dynamic tasks such as boxing. While Multi-Agent Reinforcement Learning (MARL) offers a principled framework for strategic interaction, its direct application to humanoid control is hindered by high-dimensional contact dynamics and the absence of strong physical motion priors. We propose RoboStriker, a hierarchical three-stage framework that enables fully autonomous humanoid boxing by decoupling high-level strategic reasoning from low-level physical execution. The framework first learns a comprehensive repertoire of boxing skills by training a single-agent motion tracker on human motion capture data. These skills are subsequently distilled into a structured latent manifold, regularized by projecting the Gaussian-parameterized distribution onto a unit hypersphere. This topological constraint effectively confines exploration to the subspace of physically plausible motions. In the final stage, we introduce Latent-Space Neural Fictitious Self-Play (LS-NFSP), where competing agents learn competitive tactics by interacting within the latent action space rather than the raw motor space, significantly stabilizing multi-agent training. Experimental results demonstrate that RoboStriker achieves superior competitive performance in simulation and exhibits sim-to-real transfer. Our website is available at RoboStriker.
RHINO: Learning Real-Time Humanoid-Human-Object Interaction from Human Demonstrations
Feb 18, 2025



Humanoid robots have shown success in locomotion and manipulation. Despite these basic abilities, humanoids are still required to quickly understand human instructions and react based on human interaction signals to become valuable assistants in human daily life. Unfortunately, most existing works only focus on multi-stage interactions, treating each task separately, and neglecting real-time feedback. In this work, we aim to empower humanoid robots with real-time reaction abilities to achieve various tasks, allowing human to interrupt robots at any time, and making robots respond to humans immediately. To support such abilities, we propose a general humanoid-human-object interaction framework, named RHINO, i.e., Real-time Humanoid-human Interaction and Object manipulation. RHINO provides a unified view of reactive motion, instruction-based manipulation, and safety concerns, over multiple human signal modalities, such as languages, images, and motions. RHINO is a hierarchical learning framework, enabling humanoids to learn reaction skills from human-human-object demonstrations and teleoperation data. In particular, it decouples the interaction process into two levels: 1) a high-level planner inferring human intentions from real-time human behaviors; and 2) a low-level controller achieving reactive motion behaviors and object manipulation skills based on the predicted intentions. We evaluate the proposed framework on a real humanoid robot and demonstrate its effectiveness, flexibility, and safety in various scenarios.
A Unified and General Humanoid Whole-Body Controller for Fine-Grained Locomotion
Feb 06, 2025Locomotion is a fundamental skill for humanoid robots. However, most existing works made locomotion a single, tedious, unextendable, and passive movement. This limits the kinematic capabilities of humanoid robots. In contrast, humans possess versatile athletic abilities-running, jumping, hopping, and finely adjusting walking parameters such as frequency, and foot height. In this paper, we investigate solutions to bring such versatility into humanoid locomotion and thereby propose HUGWBC: a unified and general humanoid whole-body controller for fine-grained locomotion. By designing a general command space in the aspect of tasks and behaviors, along with advanced techniques like symmetrical loss and intervention training for learning a whole-body humanoid controlling policy in simulation, HugWBC enables real-world humanoid robots to produce various natural gaits, including walking (running), jumping, standing, and hopping, with customizable parameters such as frequency, foot swing height, further combined with different body height, waist rotation, and body pitch, all in one single policy. Beyond locomotion, HUGWBC also supports real-time interventions from external upper-body controllers like teleoperation, enabling loco-manipulation while maintaining precise control under any locomotive behavior. Our experiments validate the high tracking accuracy and robustness of HUGWBC with/without upper-body intervention for all commands, and we further provide an in-depth analysis of how the various commands affect humanoid movement and offer insights into the relationships between these commands. To our knowledge, HugWBC is the first humanoid whole-body controller that supports such fine-grained locomotion behaviors with high robustness and flexibility.
Adaptive Control Strategy for Quadruped Robots in Actuator Degradation Scenarios
Dec 29, 2023
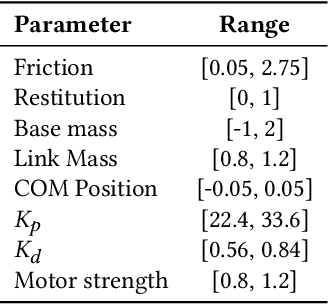
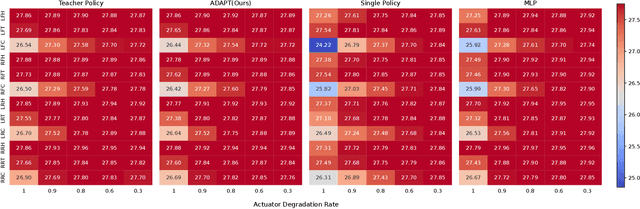
Quadruped robots have strong adaptability to extreme environments but may also experience faults. Once these faults occur, robots must be repaired before returning to the task, reducing their practical feasibility. One prevalent concern among these faults is actuator degradation, stemming from factors like device aging or unexpected operational events. Traditionally, addressing this problem has relied heavily on intricate fault-tolerant design, which demands deep domain expertise from developers and lacks generalizability. Learning-based approaches offer effective ways to mitigate these limitations, but a research gap exists in effectively deploying such methods on real-world quadruped robots. This paper introduces a pioneering teacher-student framework rooted in reinforcement learning, named Actuator Degradation Adaptation Transformer (ADAPT), aimed at addressing this research gap. This framework produces a unified control strategy, enabling the robot to sustain its locomotion and perform tasks despite sudden joint actuator faults, relying exclusively on its internal sensors. Empirical evaluations on the Unitree A1 platform validate the deployability and effectiveness of Adapt on real-world quadruped robots, and affirm the robustness and practicality of our approach.
Quantifying Zero-shot Coordination Capability with Behavior Preferring Partners
Oct 08, 2023



Zero-shot coordination (ZSC) is a new challenge focusing on generalizing learned coordination skills to unseen partners. Existing methods train the ego agent with partners from pre-trained or evolving populations. The agent's ZSC capability is typically evaluated with a few evaluation partners, including human and agent, and reported by mean returns. Current evaluation methods for ZSC capability still need to improve in constructing diverse evaluation partners and comprehensively measuring the ZSC capability. We aim to create a reliable, comprehensive, and efficient evaluation method for ZSC capability. We formally define the ideal 'diversity-complete' evaluation partners and propose the best response (BR) diversity, which is the population diversity of the BRs to the partners, to approximate the ideal evaluation partners. We propose an evaluation workflow including 'diversity-complete' evaluation partners construction and a multi-dimensional metric, the Best Response Proximity (BR-Prox) metric. BR-Prox quantifies the ZSC capability as the performance similarity to each evaluation partner's approximate best response, demonstrating generalization capability and improvement potential. We re-evaluate strong ZSC methods in the Overcooked environment using the proposed evaluation workflow. Surprisingly, the results in some of the most used layouts fail to distinguish the performance of different ZSC methods. Moreover, the evaluated ZSC methods must produce more diverse and high-performing training partners. Our proposed evaluation workflow calls for a change in how we efficiently evaluate ZSC methods as a supplement to human evaluation.
Facke: a Survey on Generative Models for Face Swapping
Jun 22, 2022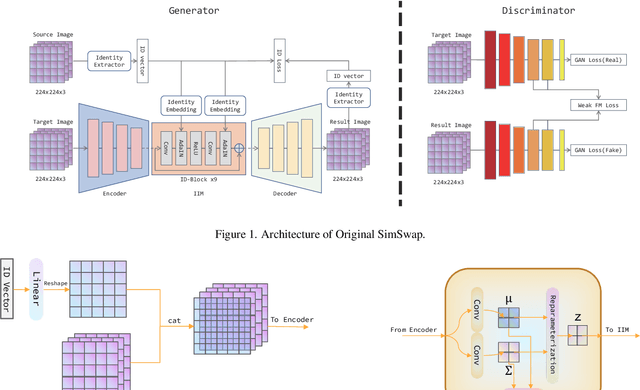
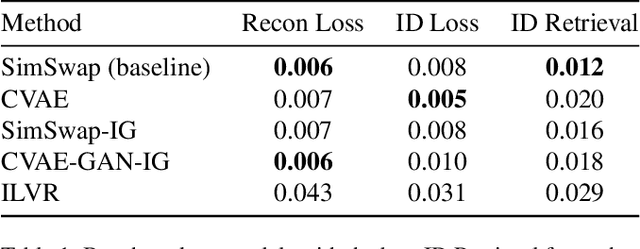


In this work, we investigate into the performance of mainstream neural generative models on the very task of swapping faces. We have experimented on CVAE, CGAN, CVAE-GAN, and conditioned diffusion models. Existing finely trained models have already managed to produce fake faces (Facke) indistinguishable to the naked eye as well as achieve high objective metrics. We perform a comparison among them and analyze their pros and cons. Furthermore, we proposed some promising tricks though they do not apply to this task.