 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIm4D: High-Fidelity and Real-Time Novel View Synthesis for Dynamic Scenes
Paper and Code
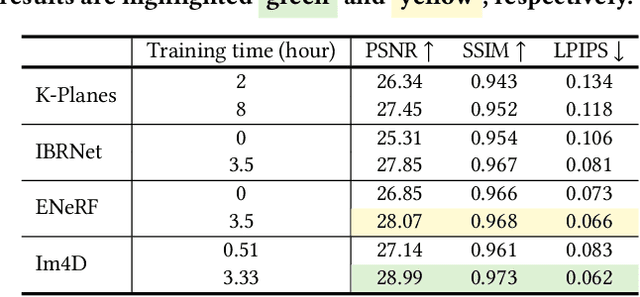
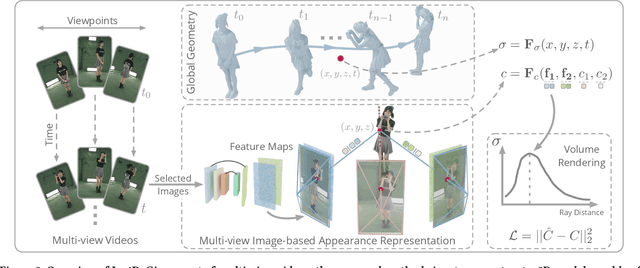

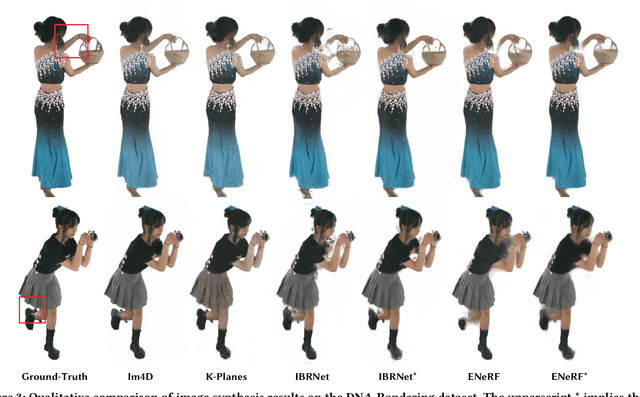
This paper aims to tackle the challenge of dynamic view synthesis from multi-view videos. The key observation is that while previous grid-based methods offer consistent rendering, they fall short in capturing appearance details of a complex dynamic scene, a domain where multi-view image-based rendering methods demonstrate the opposite properties. To combine the best of two worlds, we introduce Im4D, a hybrid scene representation that consists of a grid-based geometry representation and a multi-view image-based appearance representation. Specifically, the dynamic geometry is encoded as a 4D density function composed of spatiotemporal feature planes and a small MLP network, which globally models the scene structure and facilitates the rendering consistency. We represent the scene appearance by the original multi-view videos and a network that learns to predict the color of a 3D point from image features, instead of memorizing detailed appearance totally with networks, thereby naturally making the learning of networks easier. Our method is evaluated on five dynamic view synthesis datasets including DyNeRF, ZJU-MoCap, NHR, DNA-Rendering and ENeRF-Outdoor datasets. The results show that Im4D exhibits state-of-the-art performance in rendering quality and can be trained efficiently, while realizing real-time rendering with a speed of 79.8 FPS for 512x512 images, on a single RTX 3090 GPU.