 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Future Videos from Novel Views via Disentangled 3D Scene Representation
Paper and Code
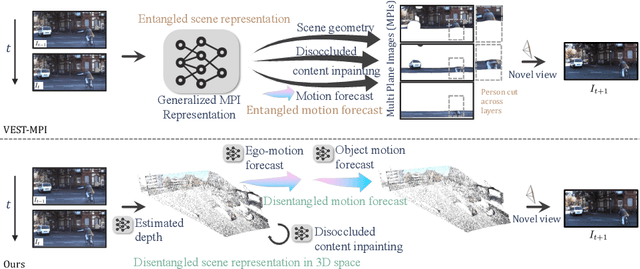



Video extrapolation in space and time (VEST) enables viewers to forecast a 3D scene into the future and view it from novel viewpoints. Recent methods propose to learn an entangled representation, aiming to model layered scene geometry, motion forecasting and novel view synthesis together, while assuming simplified affine motion and homography-based warping at each scene layer, leading to inaccurate video extrapolation. Instead of entangled scene representation and rendering, our approach chooses to disentangle scene geometry from scene motion, via lifting the 2D scene to 3D point clouds, which enables high quality rendering of future videos from novel views. To model future 3D scene motion, we propose a disentangled two-stage approach that initially forecasts ego-motion and subsequently the residual motion of dynamic objects (e.g., cars, people). This approach ensures more precise motion predictions by reducing inaccuracies from entanglement of ego-motion with dynamic object motion, where better ego-motion forecasting could significantly enhance the visual outcomes. Extensive experimental analysis on two urban scene datasets demonstrate superior performance of our proposed method in comparison to strong baselines.