 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXCL: A Tool for Requirement Document Extraction and Classification
Apr 10, 2025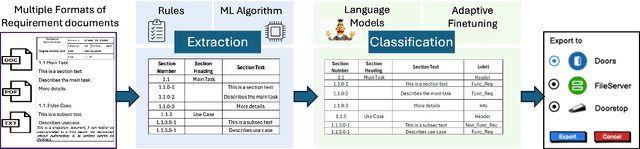
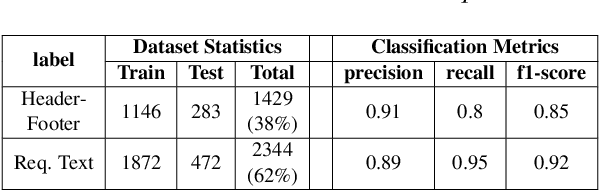
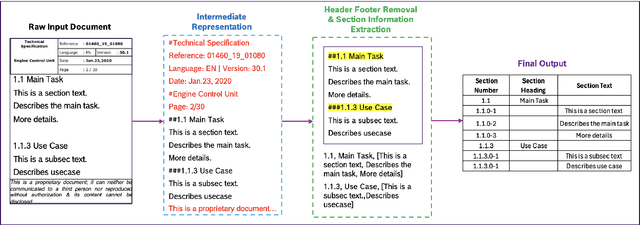
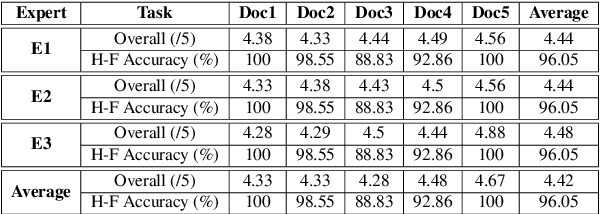
This paper presents the ReXCL tool, which automates the extraction and classification processes in requirement engineering, enhancing the software development lifecycle. The tool features two main modules: Extraction, which processes raw requirement documents into a predefined schema using heuristics and predictive modeling, and Classification, which assigns class labels to requirements using adaptive fine-tuning of encoder-based models. The final output can be exported to external requirement engineering tools. Performance evaluations indicate that ReXCL significantly improves efficiency and accuracy in managing requirements, marking a novel approach to automating the schematization of semi-structured requirement documents.
Exploring Large Language Models for Code Explanation
Oct 25, 2023


Automating code documentation through explanatory text can prove highly beneficial in code understanding. Large Language Models (LLMs) have made remarkable strides in Natural Language Processing, especially within software engineering tasks such as code generation and code summarization. This study specifically delves into the task of generating natural-language summaries for code snippets, using various LLMs. The findings indicate that Code LLMs outperform their generic counterparts, and zero-shot methods yield superior results when dealing with datasets with dissimilar distributions between training and testing sets.
Detection of Fake Users in SMPs Using NLP and Graph Embeddings
Apr 27, 2021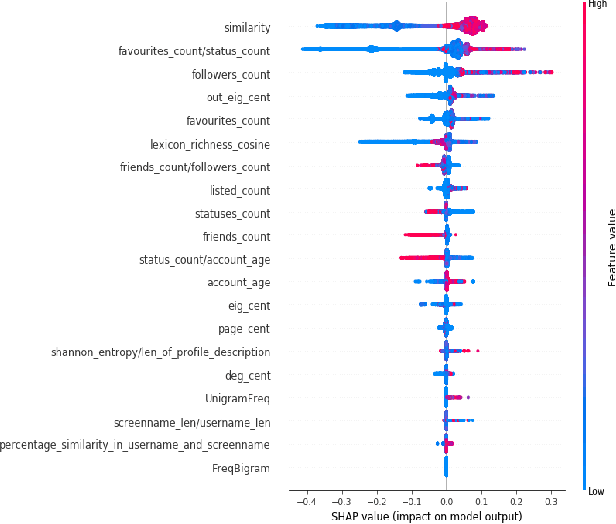
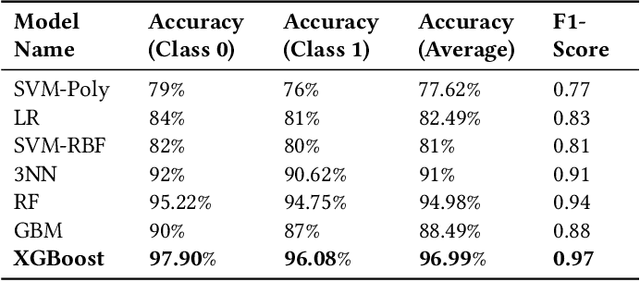
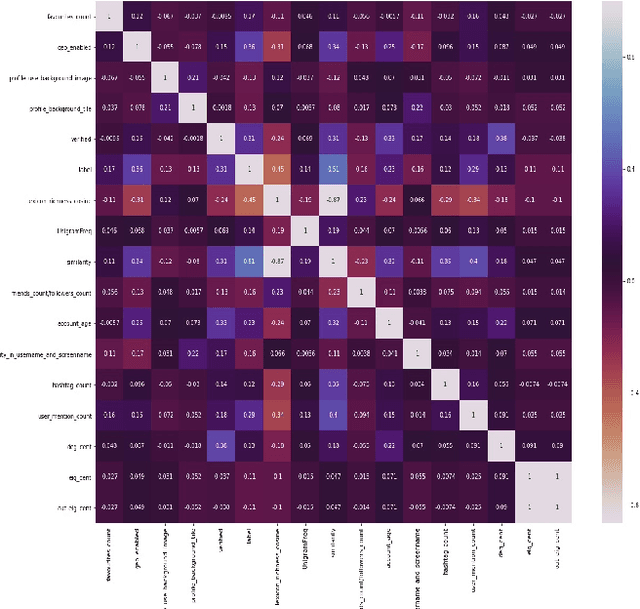
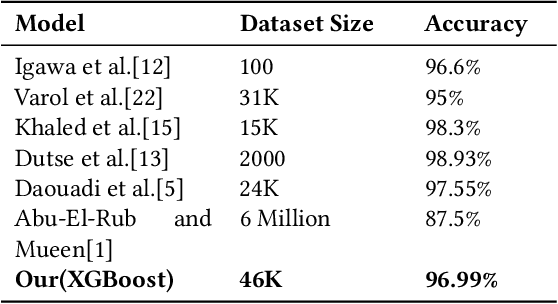
Social Media Platforms (SMPs) like Facebook, Twitter, Instagram etc. have large user base all around the world that generates huge amount of data every second. This includes a lot of posts by fake and spam users, typically used by many organisations around the globe to have competitive edge over others. In this work, we aim at detecting such user accounts in Twitter using a novel approach. We show how to distinguish between Genuine and Spam accounts in Twitter using a combination of Graph Representation Learning and Natural Language Processing techniques.
Vec2GC -- A Graph Based Clustering Method for Text Representations
Apr 15, 2021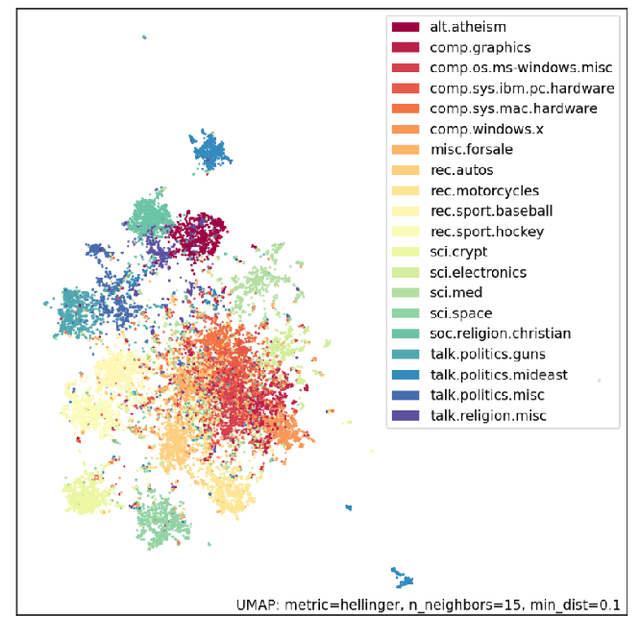
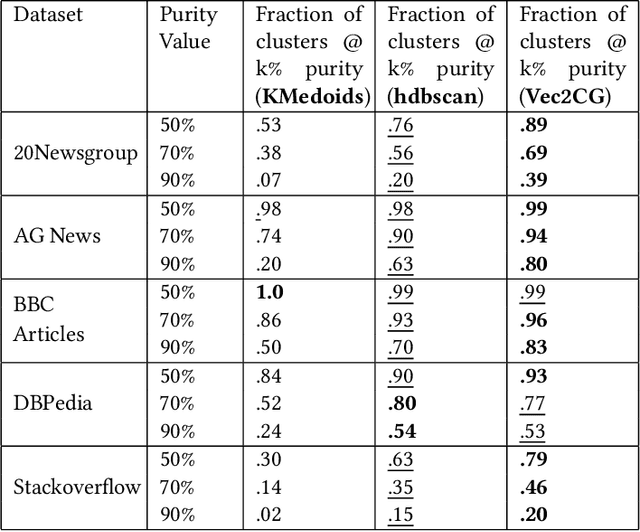
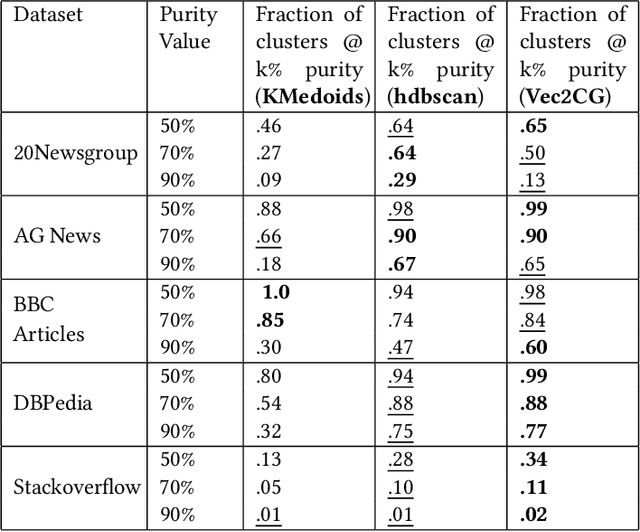

NLP pipelines with limited or no labeled data, rely on unsupervised methods for document processing. Unsupervised approaches typically depend on clustering of terms or documents. In this paper, we introduce a novel clustering algorithm, Vec2GC (Vector to Graph Communities), an end-to-end pipeline to cluster terms or documents for any given text corpus. Our method uses community detection on a weighted graph of the terms or documents, created using text representation learning. Vec2GC clustering algorithm is a density based approach, that supports hierarchical clustering as well.