Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVec2GC -- A Graph Based Clustering Method for Text Representations
Paper and Code
Apr 15, 2021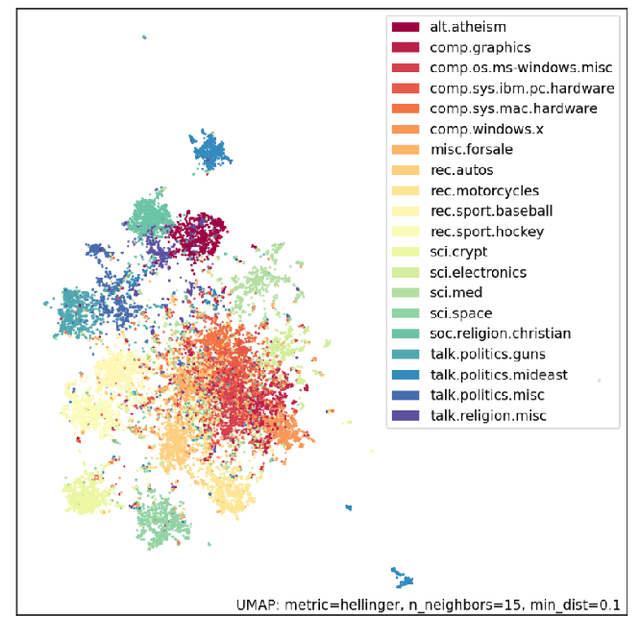
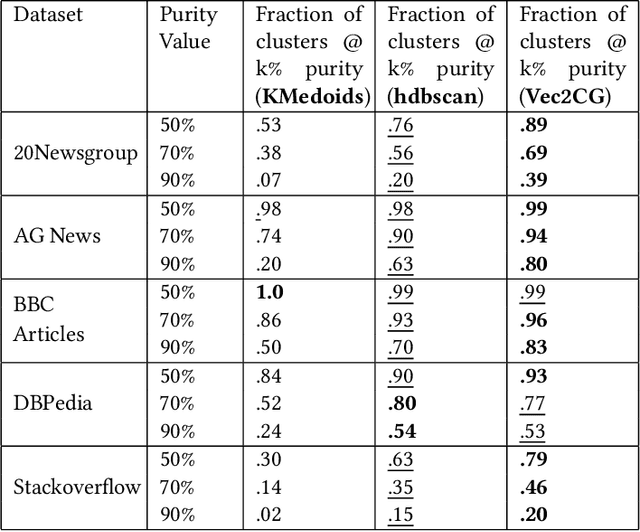
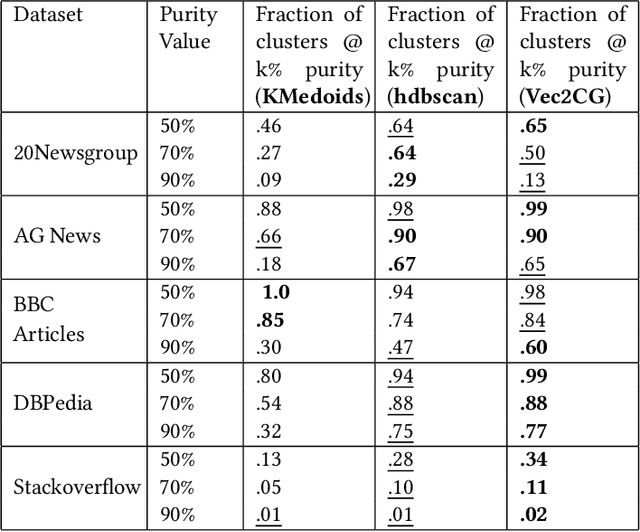

NLP pipelines with limited or no labeled data, rely on unsupervised methods for document processing. Unsupervised approaches typically depend on clustering of terms or documents. In this paper, we introduce a novel clustering algorithm, Vec2GC (Vector to Graph Communities), an end-to-end pipeline to cluster terms or documents for any given text corpus. Our method uses community detection on a weighted graph of the terms or documents, created using text representation learning. Vec2GC clustering algorithm is a density based approach, that supports hierarchical clustering as well.
View paper on