 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagRec++: Hierarchical Label Aware Attention Network for Question Categorization
Paper and Code
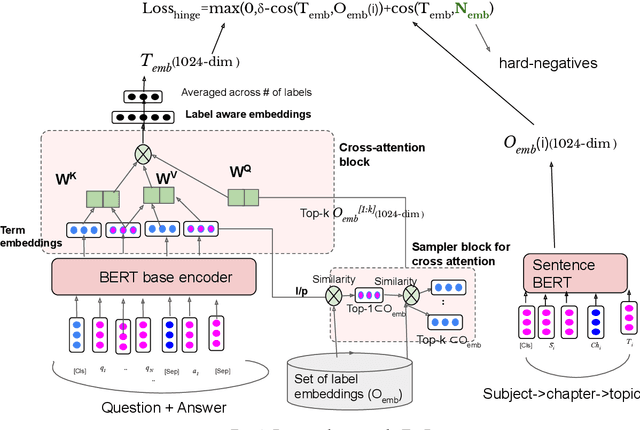
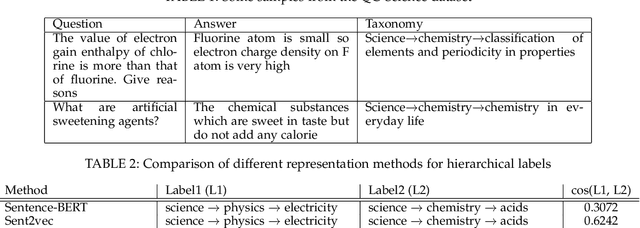
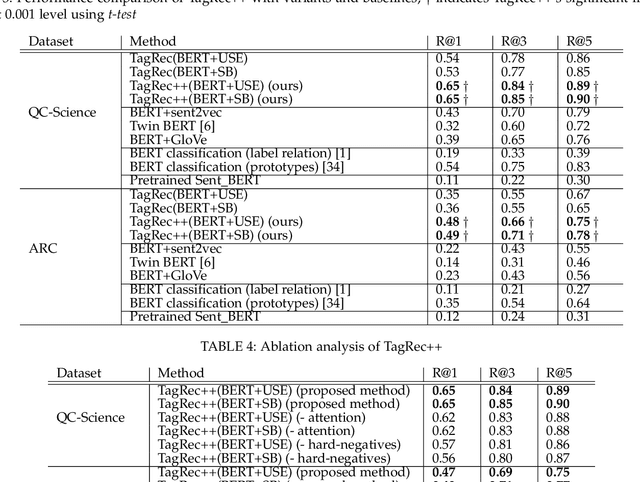

Online learning systems have multiple data repositories in the form of transcripts, books and questions. To enable ease of access, such systems organize the content according to a well defined taxonomy of hierarchical nature (subject-chapter-topic). The task of categorizing inputs to the hierarchical labels is usually cast as a flat multi-class classification problem. Such approaches ignore the semantic relatedness between the terms in the input and the tokens in the hierarchical labels. Alternate approaches also suffer from class imbalance when they only consider leaf level nodes as labels. To tackle the issues, we formulate the task as a dense retrieval problem to retrieve the appropriate hierarchical labels for each content. In this paper, we deal with categorizing questions. We model the hierarchical labels as a composition of their tokens and use an efficient cross-attention mechanism to fuse the information with the term representations of the content. We also propose an adaptive in-batch hard negative sampling approach which samples better negatives as the training progresses. We demonstrate that the proposed approach \textit{TagRec++} outperforms existing state-of-the-art approaches on question datasets as measured by Recall@k. In addition, we demonstrate zero-shot capabilities of \textit{TagRec++} and ability to adapt to label changes.