 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee, Hear, Read: Leveraging Multimodality with Guided Attention for Abstractive Text Summarization
Paper and Code
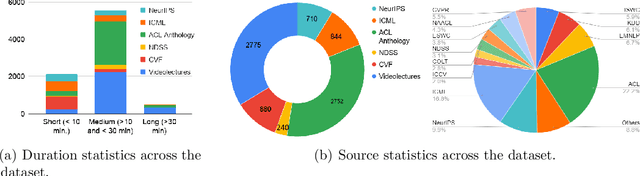
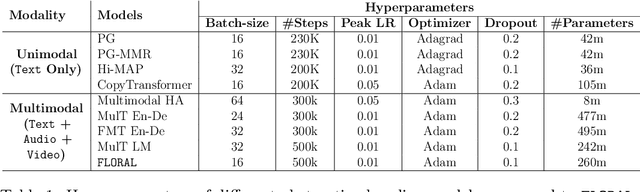
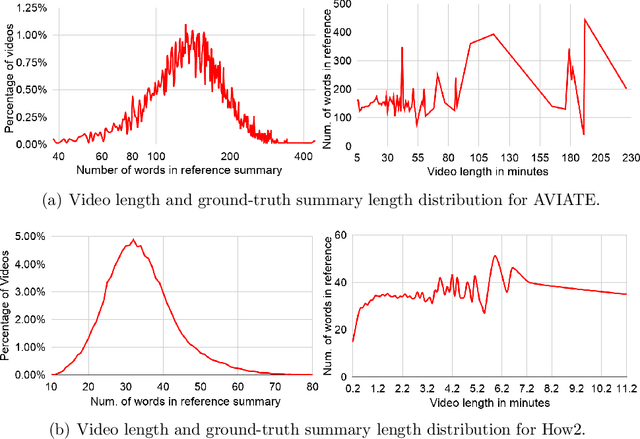
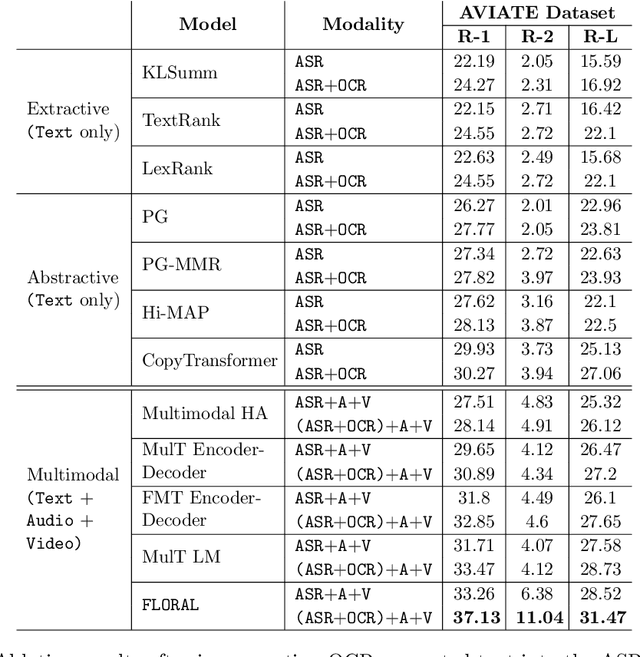
In recent years, abstractive text summarization with multimodal inputs has started drawing attention due to its ability to accumulate information from different source modalities and generate a fluent textual summary. However, existing methods use short videos as the visual modality and short summary as the ground-truth, therefore, perform poorly on lengthy videos and long ground-truth summary. Additionally, there exists no benchmark dataset to generalize this task on videos of varying lengths. In this paper, we introduce AVIATE, the first large-scale dataset for abstractive text summarization with videos of diverse duration, compiled from presentations in well-known academic conferences like NDSS, ICML, NeurIPS, etc. We use the abstract of corresponding research papers as the reference summaries, which ensure adequate quality and uniformity of the ground-truth. We then propose {\name}, a factorized multi-modal Transformer based decoder-only language model, which inherently captures the intra-modal and inter-modal dynamics within various input modalities for the text summarization task. {\name} utilizes an increasing number of self-attentions to capture multimodality and performs significantly better than traditional encoder-decoder based networks. Extensive experiments illustrate that {\name} achieves significant improvement over the baselines in both qualitative and quantitative evaluations on the existing How2 dataset for short videos and newly introduced AVIATE dataset for videos with diverse duration, beating the best baseline on the two datasets by $1.39$ and $2.74$ ROUGE-L points respectively.