 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpora Evaluation and System Bias Detection in Multi-document Summarization
Paper and Code

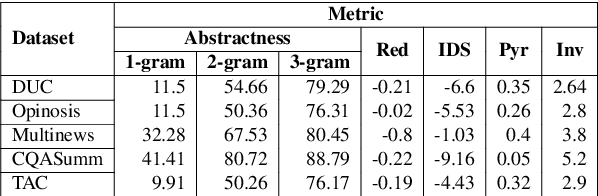

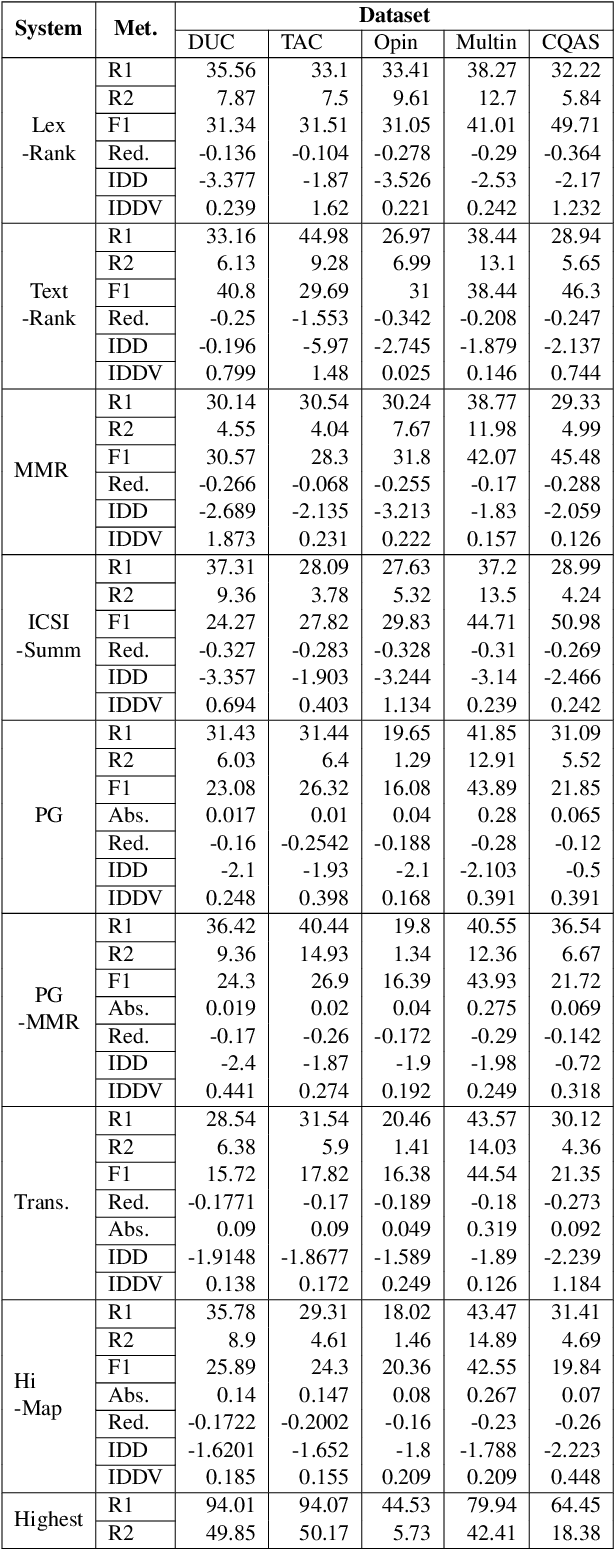
Multi-document summarization (MDS) is the task of reflecting key points from any set of documents into a concise text paragraph. In the past, it has been used to aggregate news, tweets, product reviews, etc. from various sources. Owing to no standard definition of the task, we encounter a plethora of datasets with varying levels of overlap and conflict between participating documents. There is also no standard regarding what constitutes summary information in MDS. Adding to the challenge is the fact that new systems report results on a set of chosen datasets, which might not correlate with their performance on the other datasets. In this paper, we study this heterogeneous task with the help of a few widely used MDS corpora and a suite of state-of-the-art models. We make an attempt to quantify the quality of summarization corpus and prescribe a list of points to consider while proposing a new MDS corpus. Next, we analyze the reason behind the absence of an MDS system which achieves superior performance across all corpora. We then observe the extent to which system metrics are influenced, and bias is propagated due to corpus properties. The scripts to reproduce the experiments in this work are available at https://github.com/LCS2-IIITD/summarization_bias.git.