 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Quality of the Datasets by Identifying Mislabeled Samples
Paper and Code


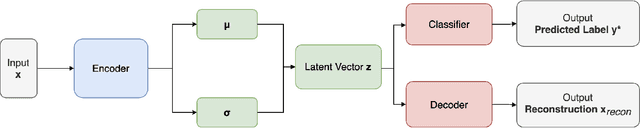
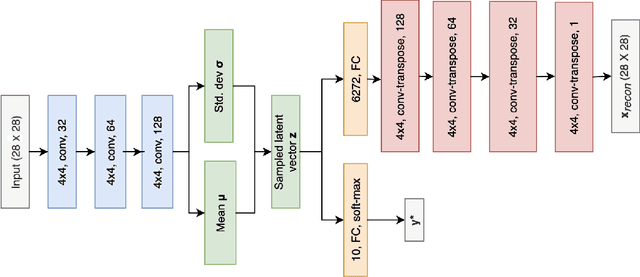
Due to the over-emphasize of the quantity of data, the data quality has often been overlooked. However, not all training data points contribute equally to learning. In particular, if mislabeled, it might actively damage the performance of the model and the ability to generalize out of distribution, as the model might end up learning spurious artifacts present in the dataset. This problem gets compounded by the prevalence of heavily parameterized and complex deep neural networks, which can, with their high capacity, end up memorizing the noise present in the dataset. This paper proposes a novel statistic -- noise score, as a measure for the quality of each data point to identify such mislabeled samples based on the variations in the latent space representation. In our work, we use the representations derived by the inference network of data quality supervised variational autoencoder (AQUAVS). Our method leverages the fact that samples belonging to the same class will have similar latent representations. Therefore, by identifying the outliers in the latent space, we can find the mislabeled samples. We validate our proposed statistic through experimentation by corrupting MNIST, FashionMNIST, and CIFAR10/100 datasets in different noise settings for the task of identifying mislabelled samples. We further show significant improvements in accuracy for the classification task for each dataset.