 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Abstractive Summarization with Structural Attention
Paper and Code
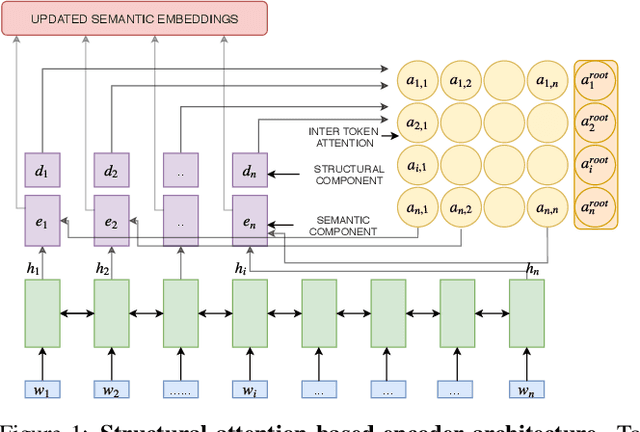
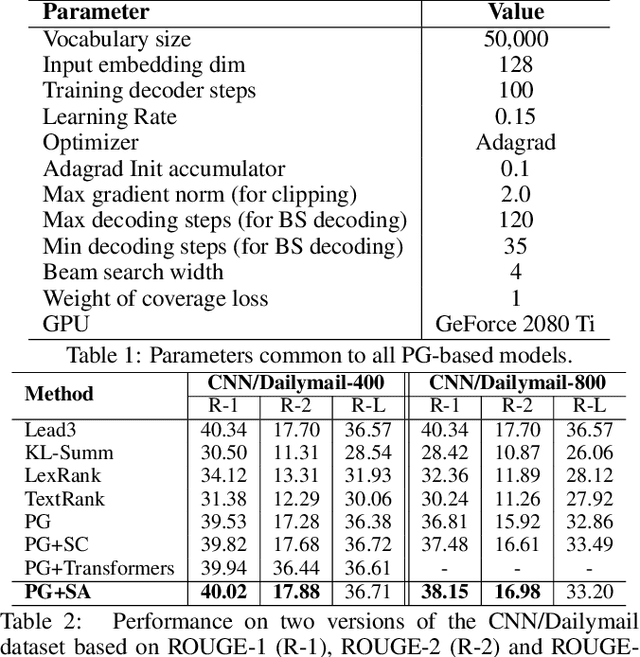
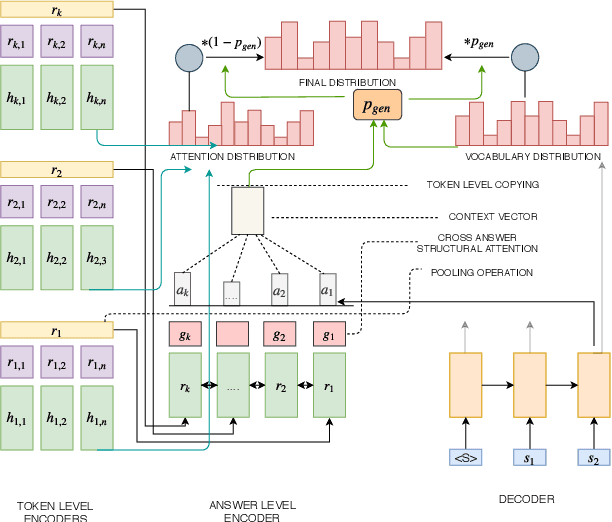
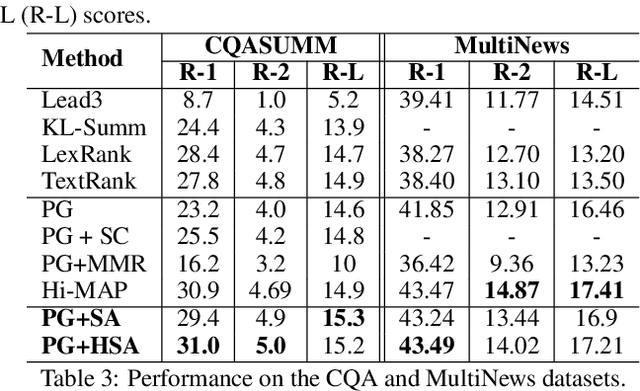
Attentional, RNN-based encoder-decoder architectures have achieved impressive performance on abstractive summarization of news articles. However, these methods fail to account for long term dependencies within the sentences of a document. This problem is exacerbated in multi-document summarization tasks such as summarizing the popular opinion in threads present in community question answering (CQA) websites such as Yahoo! Answers and Quora. These threads contain answers which often overlap or contradict each other. In this work, we present a hierarchical encoder based on structural attention to model such inter-sentence and inter-document dependencies. We set the popular pointer-generator architecture and some of the architectures derived from it as our baselines and show that they fail to generate good summaries in a multi-document setting. We further illustrate that our proposed model achieves significant improvement over the baselines in both single and multi-document summarization settings -- in the former setting, it beats the best baseline by 1.31 and 7.8 ROUGE-1 points on CNN and CQA datasets, respectively; in the latter setting, the performance is further improved by 1.6 ROUGE-1 points on the CQA dataset.