 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-TEST: Evaluating Explanation Regularization Methods for NLP Models
Paper and Code
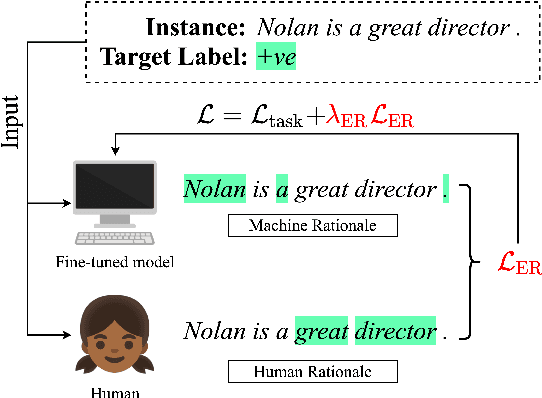
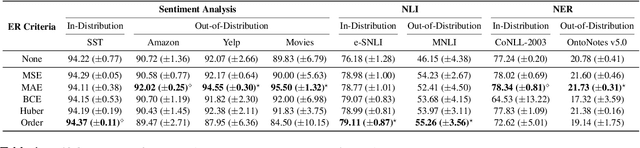
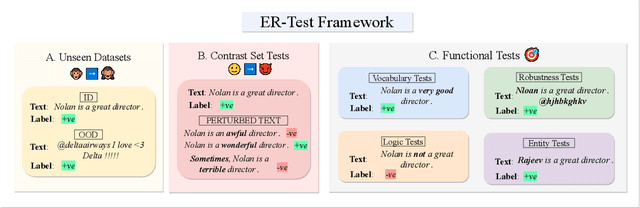
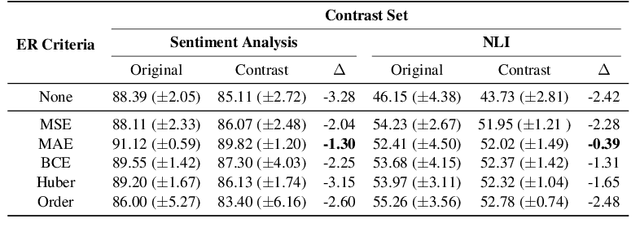
Neural language models' (NLMs') reasoning processes are notoriously hard to explain. Recently, there has been much progress in automatically generating machine rationales of NLM behavior, but less in utilizing the rationales to improve NLM behavior. For the latter, explanation regularization (ER) aims to improve NLM generalization by pushing the machine rationales to align with human rationales. Whereas prior works primarily evaluate such ER models via in-distribution (ID) generalization, ER's impact on out-of-distribution (OOD) is largely underexplored. Plus, little is understood about how ER model performance is affected by the choice of ER criteria or by the number/choice of training instances with human rationales. In light of this, we propose ER-TEST, a protocol for evaluating ER models' OOD generalization along three dimensions: (1) unseen datasets, (2) contrast set tests, and (3) functional tests. Using ER-TEST, we study three key questions: (A) Which ER criteria are most effective for the given OOD setting? (B) How is ER affected by the number/choice of training instances with human rationales? (C) Is ER effective with distantly supervised human rationales? ER-TEST enables comprehensive analysis of these questions by considering a diverse range of tasks and datasets. Through ER-TEST, we show that ER has little impact on ID performance, but can yield large gains on OOD performance w.r.t. (1)-(3). Also, we find that the best ER criterion is task-dependent, while ER can improve OOD performance even with limited and distantly-supervised human rationales.