 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToys that listen, talk, and play: Understanding Children's Sensemaking and Interactions with AI Toys
Apr 03, 2026Generative AI (genAI) is increasingly being integrated into children's everyday lives, not only through screens but also through so-called "screen-free" AI toys. These toys can simulate emotions, personalize responses, and recall prior interactions, creating the illusion of an ongoing social connection. Such capabilities raise important questions about how children understand boundaries, agency, and relationships when interacting with AI toys. To investigate this, we conducted two participatory design sessions with eight children ages 6-11 where they engaged with three different AI toys, shifting between play, experimentation, and reflection. Our findings reveal that children approached AI toys with genuine curiosity, profiling them as social beings. However, frequent interaction breakdowns and mismatches between apparent intelligence and toy-like form disrupted expectations around play and led to adversarial play. We conclude with implications and design provocations to navigate children's encounters with AI toys in more transparent, developmentally appropriate, and responsible ways.
Breaking News: Case Studies of Generative AI's Use in Journalism
Jun 19, 2024



Journalists are among the many users of large language models (LLMs). To better understand the journalist-AI interactions, we conduct a study of LLM usage by two news agencies through browsing the WildChat dataset, identifying candidate interactions, and verifying them by matching to online published articles. Our analysis uncovers instances where journalists provide sensitive material such as confidential correspondence with sources or articles from other agencies to the LLM as stimuli and prompt it to generate articles, and publish these machine-generated articles with limited intervention (median output-publication ROUGE-L of 0.62). Based on our findings, we call for further research into what constitutes responsible use of AI, and the establishment of clear guidelines and best practices on using LLMs in a journalistic context.
SecGPT: An Execution Isolation Architecture for LLM-Based Systems
Mar 08, 2024



Large language models (LLMs) extended as systems, such as ChatGPT, have begun supporting third-party applications. These LLM apps leverage the de facto natural language-based automated execution paradigm of LLMs: that is, apps and their interactions are defined in natural language, provided access to user data, and allowed to freely interact with each other and the system. These LLM app ecosystems resemble the settings of earlier computing platforms, where there was insufficient isolation between apps and the system. Because third-party apps may not be trustworthy, and exacerbated by the imprecision of the natural language interfaces, the current designs pose security and privacy risks for users. In this paper, we propose SecGPT, an architecture for LLM-based systems that aims to mitigate the security and privacy issues that arise with the execution of third-party apps. SecGPT's key idea is to isolate the execution of apps and more precisely mediate their interactions outside of their isolated environments. We evaluate SecGPT against a number of case study attacks and demonstrate that it protects against many security, privacy, and safety issues that exist in non-isolated LLM-based systems. The performance overhead incurred by SecGPT to improve security is under 0.3x for three-quarters of the tested queries. To foster follow-up research, we release SecGPT's source code at https://github.com/llm-platform-security/SecGPT.
LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI's ChatGPT Plugins
Sep 19, 2023



Large language model (LLM) platforms, such as ChatGPT, have recently begun offering a plugin ecosystem to interface with third-party services on the internet. While these plugins extend the capabilities of LLM platforms, they are developed by arbitrary third parties and thus cannot be implicitly trusted. Plugins also interface with LLM platforms and users using natural language, which can have imprecise interpretations. In this paper, we propose a framework that lays a foundation for LLM platform designers to analyze and improve the security, privacy, and safety of current and future plugin-integrated LLM platforms. Our framework is a formulation of an attack taxonomy that is developed by iteratively exploring how LLM platform stakeholders could leverage their capabilities and responsibilities to mount attacks against each other. As part of our iterative process, we apply our framework in the context of OpenAI's plugin ecosystem. We uncover plugins that concretely demonstrate the potential for the types of issues that we outline in our attack taxonomy. We conclude by discussing novel challenges and by providing recommendations to improve the security, privacy, and safety of present and future LLM-based computing platforms.
Misinfo Belief Frames: A Case Study on Covid & Climate News
Apr 18, 2021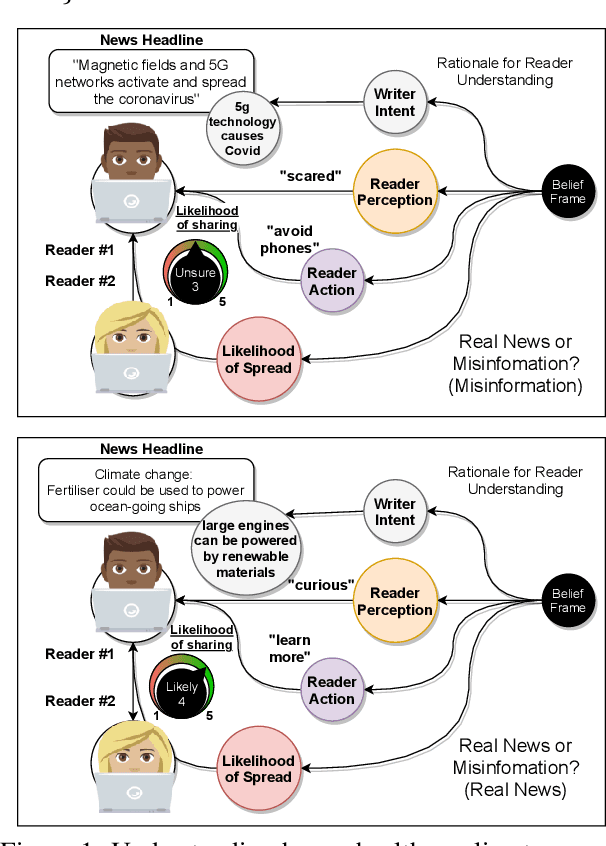
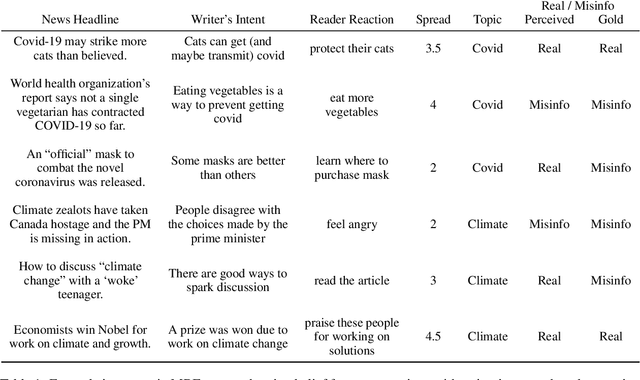
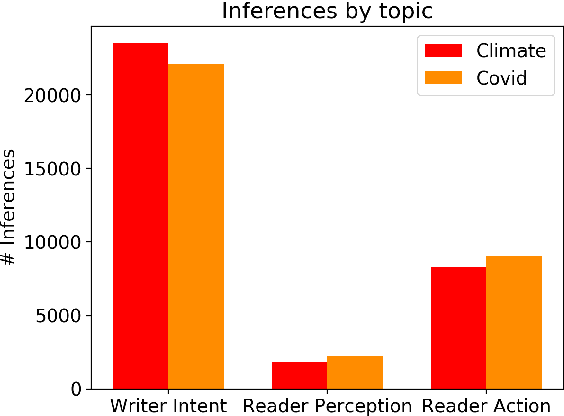
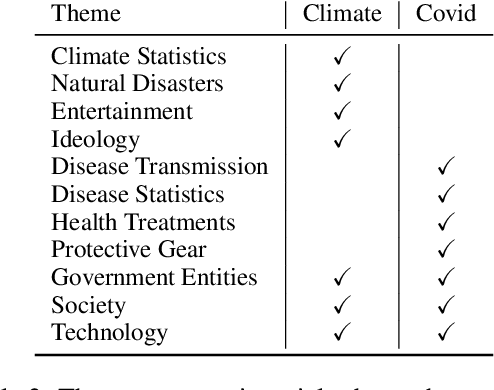
Prior beliefs of readers impact the way in which they project meaning onto news headlines. These beliefs can influence their perception of news reliability, as well as their reaction to news, and their likelihood of spreading the misinformation through social networks. However, most prior work focuses on fact-checking veracity of news or stylometry rather than measuring impact of misinformation. We propose Misinfo Belief Frames, a formalism for understanding how readers perceive the reliability of news and the impact of misinformation. We also introduce the Misinfo Belief Frames (MBF) corpus, a dataset of 66k inferences over 23.5k headlines. Misinformation frames use commonsense reasoning to uncover implications of real and fake news headlines focused on global crises: the Covid-19 pandemic and climate change. Our results using large-scale language modeling to predict misinformation frames show that machine-generated inferences can influence readers' trust in news headlines (readers' trust in news headlines was affected in 29.3% of cases). This demonstrates the potential effectiveness of using generated frames to counter misinformation.
Defending Against Neural Fake News
May 29, 2019
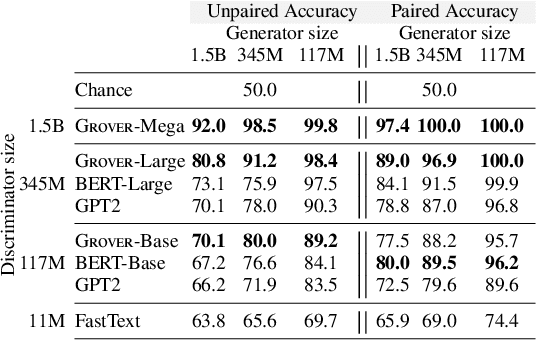
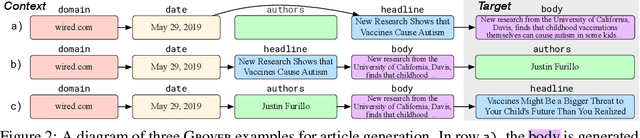
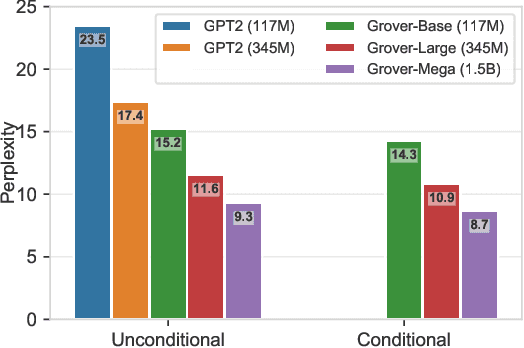
Recent progress in natural language generation has raised dual-use concerns. While applications like summarization and translation are positive, the underlying technology also might enable adversaries to generate neural fake news: targeted propaganda that closely mimics the style of real news. Modern computer security relies on careful threat modeling: identifying potential threats and vulnerabilities from an adversary's point of view, and exploring potential mitigations to these threats. Likewise, developing robust defenses against neural fake news requires us first to carefully investigate and characterize the risks of these models. We thus present a model for controllable text generation called Grover. Given a headline like `Link Found Between Vaccines and Autism,' Grover can generate the rest of the article; humans find these generations to be more trustworthy than human-written disinformation. Developing robust verification techniques against generators like Grover is critical. We find that best current discriminators can classify neural fake news from real, human-written, news with 73% accuracy, assuming access to a moderate level of training data. Counterintuitively, the best defense against Grover turns out to be Grover itself, with 92% accuracy, demonstrating the importance of public release of strong generators. We investigate these results further, showing that exposure bias -- and sampling strategies that alleviate its effects -- both leave artifacts that similar discriminators can pick up on. We conclude by discussing ethical issues regarding the technology, and plan to release Grover publicly, helping pave the way for better detection of neural fake news.