 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkUp: A Novel Dataset Paving the Way for Understanding Empowering Language
May 23, 2023



Empowering language is important in many real-world contexts, from education to workplace dynamics to healthcare. Though language technologies are growing more prevalent in these contexts, empowerment has not been studied in NLP, and moreover, it is inherently challenging to operationalize because of its subtle, implicit nature. This work presents the first computational exploration of empowering language. We first define empowerment detection as a new task, grounding it in linguistic and social psychology literature. We then crowdsource a novel dataset of Reddit posts labeled for empowerment, reasons why these posts are empowering to readers, and the social relationships between posters and readers. Our preliminary analyses show that this dataset, which we call TalkUp, can be used to train language models that capture empowering and disempowering language. More broadly, as it is rich with the ambiguities and diverse interpretations of real-world language, TalkUp provides an avenue to explore implication, presuppositions, and how social context influences the meaning of language.
Gendered Mental Health Stigma in Masked Language Models
Oct 27, 2022Mental health stigma prevents many individuals from receiving the appropriate care, and social psychology studies have shown that mental health tends to be overlooked in men. In this work, we investigate gendered mental health stigma in masked language models. In doing so, we operationalize mental health stigma by developing a framework grounded in psychology research: we use clinical psychology literature to curate prompts, then evaluate the models' propensity to generate gendered words. We find that masked language models capture societal stigma about gender in mental health: models are consistently more likely to predict female subjects than male in sentences about having a mental health condition (32% vs. 19%), and this disparity is exacerbated for sentences that indicate treatment-seeking behavior. Furthermore, we find that different models capture dimensions of stigma differently for men and women, associating stereotypes like anger, blame, and pity more with women with mental health conditions than with men. In showing the complex nuances of models' gendered mental health stigma, we demonstrate that context and overlapping dimensions of identity are important considerations when assessing computational models' social biases.
Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey
Oct 14, 2022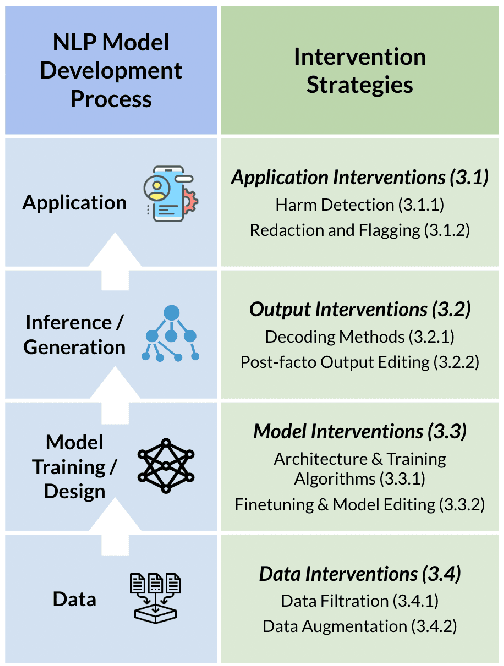

Recent advances in the capacity of large language models to generate human-like text have resulted in their increased adoption in user-facing settings. In parallel, these improvements have prompted a heated discourse around the risks of societal harms they introduce, whether inadvertent or malicious. Several studies have identified potential causes of these harms and called for their mitigation via development of safer and fairer models. Going beyond enumerating the risks of harms, this work provides a survey of practical methods for addressing potential threats and societal harms from language generation models. We draw on several prior works' taxonomies of language model risks to present a structured overview of strategies for detecting and ameliorating different kinds of risks/harms of language generators. Bridging diverse strands of research, this survey aims to serve as a practical guide for both LM researchers and practitioners with explanations of motivations behind different mitigation strategies, their limitations, and open problems for future research.