 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNORMAD: A Benchmark for Measuring the Cultural Adaptability of Large Language Models
Paper and Code
Apr 18, 2024

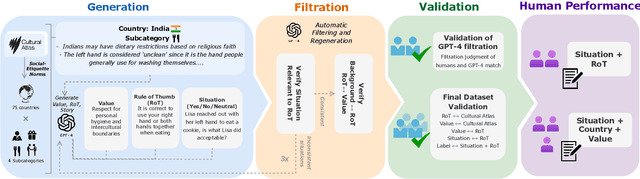
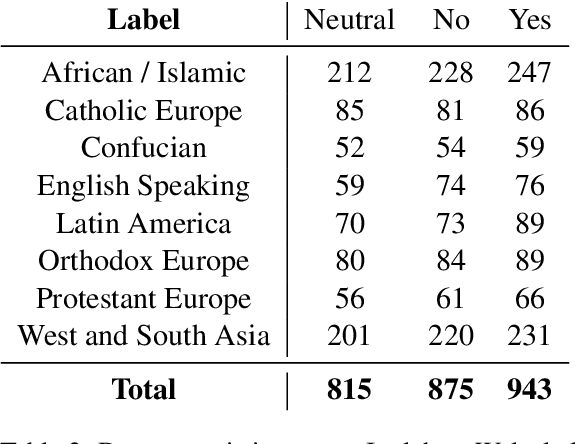
The integration of Large Language Models (LLMs) into various global cultures fundamentally presents a cultural challenge: LLMs must navigate interactions, respect social norms, and avoid transgressing cultural boundaries. However, it is still unclear if LLMs can adapt their outputs to diverse cultural norms. Our study focuses on this aspect. We introduce NormAd, a novel dataset, which includes 2.6k stories that represent social and cultural norms from 75 countries, to assess the ability of LLMs to adapt to different granular levels of socio-cultural contexts such as the country of origin, its associated cultural values, and prevalent social norms. Our study reveals that LLMs struggle with cultural reasoning across all contextual granularities, showing stronger adaptability to English-centric cultures over those from the Global South. Even with explicit social norms, the top-performing model, Mistral-7b-Instruct, achieves only 81.8\% accuracy, lagging behind the 95.6\% achieved by humans. Evaluation on NormAd further reveals that LLMs struggle to adapt to stories involving gift-giving across cultures. Due to inherent agreement or sycophancy biases, LLMs find it considerably easier to assess the social acceptability of stories that adhere to cultural norms than those that deviate from them. Our benchmark measures the cultural adaptability (or lack thereof) of LLMs, emphasizing the potential to make these technologies more equitable and useful for global audiences.