 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorello: Compiling Fast Neural Networks with Dynamic Programming and Spatial Compression
May 03, 2025

High-throughput neural network inference requires coordinating many optimization decisions, including parallel tiling, microkernel selection, and data layout. The product of these decisions forms a search space of programs which is typically intractably large. Existing approaches (e.g., auto-schedulers) often address this problem by sampling this space heuristically. In contrast, we introduce a dynamic-programming-based approach to explore more of the search space by iteratively decomposing large program specifications into smaller specifications reachable from a set of rewrites, then composing a final program from each rewrite that minimizes an affine cost model. To reduce memory requirements, we employ a novel memoization table representation, which indexes specifications by coordinates in $Z_{\geq 0}$ and compresses identical, adjacent solutions. This approach can visit a much larger set of programs than prior work. To evaluate the approach, we developed Morello, a compiler which lowers specifications roughly equivalent to a few-node XLA computation graph to x86. Notably, we found that an affine cost model is sufficient to surface high-throughput programs. For example, Morello synthesized a collection of matrix multiplication benchmarks targeting a Zen 1 CPU, including a 1x2048x16384, bfloat16-to-float32 vector-matrix multiply, which was integrated into Google's gemma.cpp.
A Learned Performance Model for the Tensor Processing Unit
Aug 03, 2020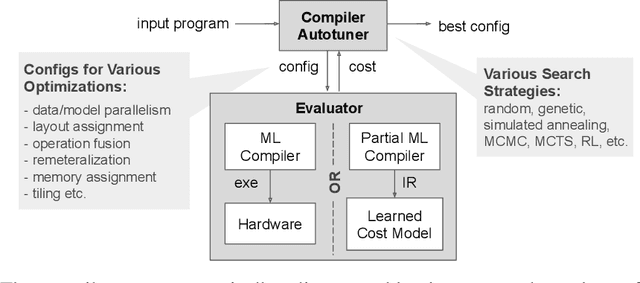
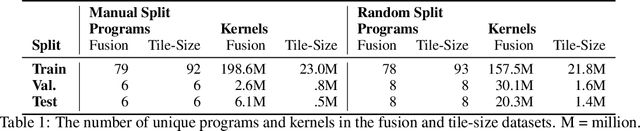
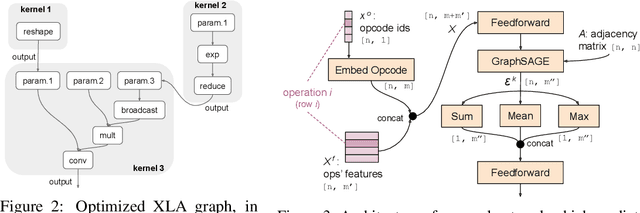
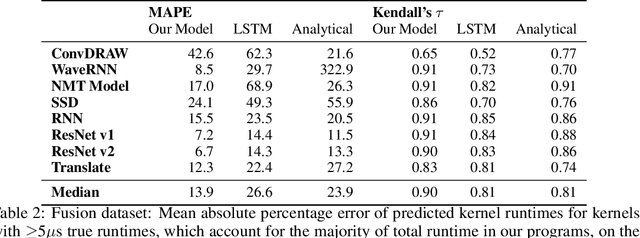
Accurate hardware performance models are critical to efficient code generation. They can be used by compilers to make heuristic decisions, by superoptimizers as an minimization objective, or by autotuners to find an optimal configuration of a specific program. However, they are difficult to develop because contemporary processors are complex, and the recent proliferation of deep learning accelerators has increased the development burden. We demonstrate a method of learning performance models from a corpus of tensor computation graph programs for the Tensor Processing Unit (TPU). We train a neural network over kernel-level sub-graphs from the corpus and find that the learned model is competitive to a heavily-optimized analytical cost model used in the production XLA compiler.