 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learned Performance Model for the Tensor Processing Unit
Aug 03, 2020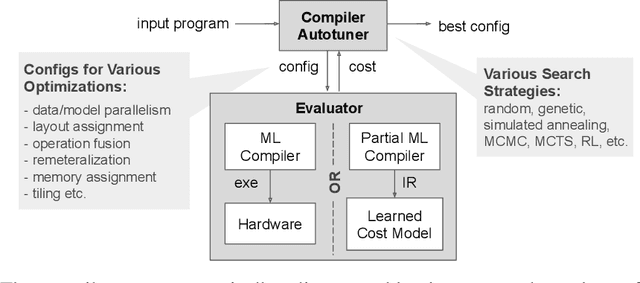
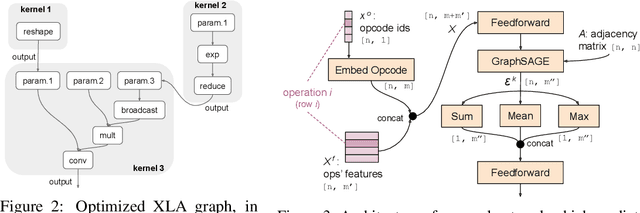
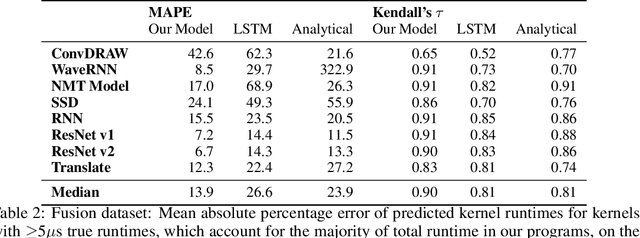
Accurate hardware performance models are critical to efficient code generation. They can be used by compilers to make heuristic decisions, by superoptimizers as an minimization objective, or by autotuners to find an optimal configuration of a specific program. However, they are difficult to develop because contemporary processors are complex, and the recent proliferation of deep learning accelerators has increased the development burden. We demonstrate a method of learning performance models from a corpus of tensor computation graph programs for the Tensor Processing Unit (TPU). We train a neural network over kernel-level sub-graphs from the corpus and find that the learned model is competitive to a heavily-optimized analytical cost model used in the production XLA compiler.
Dynamic Control Flow in Large-Scale Machine Learning
May 04, 2018

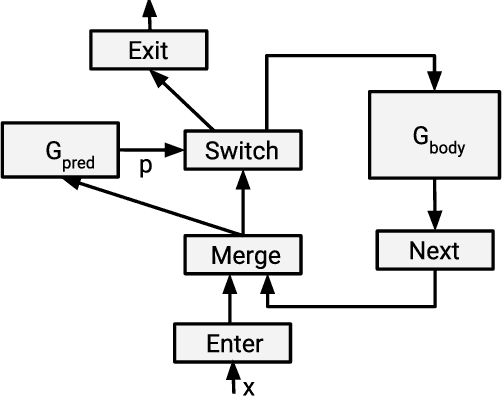
Many recent machine learning models rely on fine-grained dynamic control flow for training and inference. In particular, models based on recurrent neural networks and on reinforcement learning depend on recurrence relations, data-dependent conditional execution, and other features that call for dynamic control flow. These applications benefit from the ability to make rapid control-flow decisions across a set of computing devices in a distributed system. For performance, scalability, and expressiveness, a machine learning system must support dynamic control flow in distributed and heterogeneous environments. This paper presents a programming model for distributed machine learning that supports dynamic control flow. We describe the design of the programming model, and its implementation in TensorFlow, a distributed machine learning system. Our approach extends the use of dataflow graphs to represent machine learning models, offering several distinctive features. First, the branches of conditionals and bodies of loops can be partitioned across many machines to run on a set of heterogeneous devices, including CPUs, GPUs, and custom ASICs. Second, programs written in our model support automatic differentiation and distributed gradient computations, which are necessary for training machine learning models that use control flow. Third, our choice of non-strict semantics enables multiple loop iterations to execute in parallel across machines, and to overlap compute and I/O operations. We have done our work in the context of TensorFlow, and it has been used extensively in research and production. We evaluate it using several real-world applications, and demonstrate its performance and scalability.
* Appeared in EuroSys 2018. 14 pages, 16 figures