 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyjuice: Automated, General-purpose Counterfactual Generation
Paper and Code


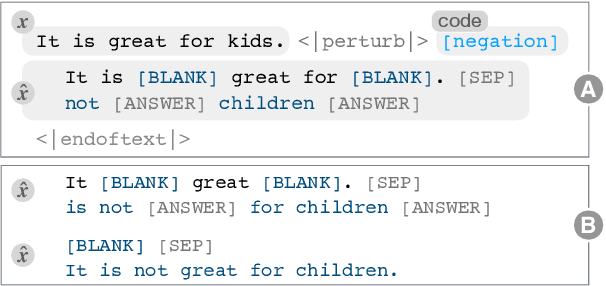

Counterfactual examples have been shown to be useful for many applications, including calibrating, evaluating, and explaining model decision boundaries. However, previous methods for generating such counterfactual examples have been tightly tailored to a specific application, used a limited range of linguistic patterns, or are hard to scale. We propose to disentangle counterfactual generation from its use cases, i.e., gather general-purpose counterfactuals first, and then select them for specific applications. We frame the automated counterfactual generation as text generation, and finetune GPT-2 into a generator, Polyjuice, which produces fluent and diverse counterfactuals. Our method also allows control over where perturbations happen and what they do. We show Polyjuice supports multiple use cases: by generating diverse counterfactuals for humans to label, Polyjuice helps produce high-quality datasets for model training and evaluation, requiring 40% less human effort. When used to generate explanations, Polyjuice helps augment feature attribution methods to reveal models' erroneous behaviors.