 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-evaluating Theory of Mind evaluation in large language models
Feb 28, 2025The question of whether large language models (LLMs) possess Theory of Mind (ToM) -- often defined as the ability to reason about others' mental states -- has sparked significant scientific and public interest. However, the evidence as to whether LLMs possess ToM is mixed, and the recent growth in evaluations has not resulted in a convergence. Here, we take inspiration from cognitive science to re-evaluate the state of ToM evaluation in LLMs. We argue that a major reason for the disagreement on whether LLMs have ToM is a lack of clarity on whether models should be expected to match human behaviors, or the computations underlying those behaviors. We also highlight ways in which current evaluations may be deviating from "pure" measurements of ToM abilities, which also contributes to the confusion. We conclude by discussing several directions for future research, including the relationship between ToM and pragmatic communication, which could advance our understanding of artificial systems as well as human cognition.
Shades of Zero: Distinguishing Impossibility from Inconceivability
Feb 27, 2025Some things are impossible, but some things may be even more impossible than impossible. Levitating a feather using one's mind is impossible in our world, but fits into our intuitive theories of possible worlds, whereas levitating a feather using the number five cannot be conceived in any possible world ("inconceivable"). While prior work has examined the distinction between improbable and impossible events, there has been little empirical research on inconceivability. Here, we investigate whether people maintain a distinction between impossibility and inconceivability, and how such distinctions might be made. We find that people can readily distinguish the impossible from the inconceivable, using categorization studies similar to those used to investigate the differences between impossible and improbable (Experiment 1). However, this distinction is not explained by people's subjective ratings of event likelihood, which are near zero and indistinguishable between impossible and inconceivable event descriptions (Experiment 2). Finally, we ask whether the probabilities assigned to event descriptions by statistical language models (LMs) can be used to separate modal categories, and whether these probabilities align with people's ratings (Experiment 3). We find high-level similarities between people and LMs: both distinguish among impossible and inconceivable event descriptions, and LM-derived string probabilities predict people's ratings of event likelihood across modal categories. Our findings suggest that fine-grained knowledge about exceedingly rare events (i.e., the impossible and inconceivable) may be learned via statistical learning over linguistic forms, yet leave open the question of whether people represent the distinction between impossible and inconceivable as a difference not of degree, but of kind.
Write, Execute, Assess: Program Synthesis with a REPL
Jun 09, 2019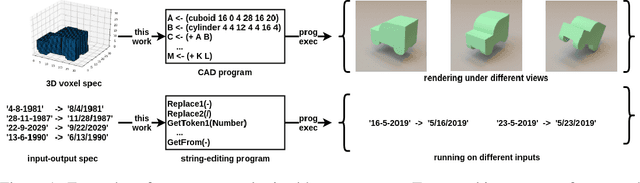
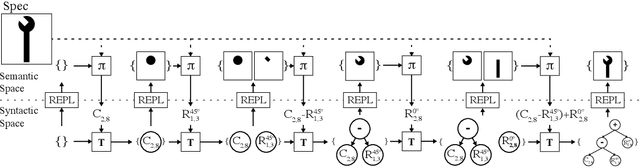
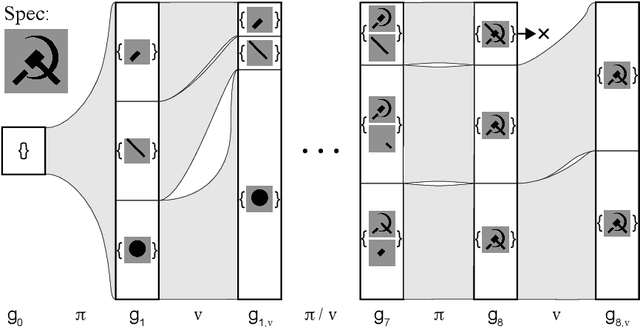
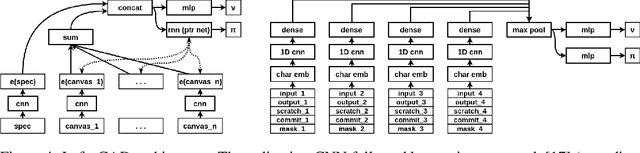
We present a neural program synthesis approach integrating components which write, execute, and assess code to navigate the search space of possible programs. We equip the search process with an interpreter or a read-eval-print-loop (REPL), which immediately executes partially written programs, exposing their semantics. The REPL addresses a basic challenge of program synthesis: tiny changes in syntax can lead to huge changes in semantics. We train a pair of models, a policy that proposes the new piece of code to write, and a value function that assesses the prospects of the code written so-far. At test time we can combine these models with a Sequential Monte Carlo algorithm. We apply our approach to two domains: synthesizing text editing programs and inferring 2D and 3D graphics programs.