 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
Feb 02, 2026Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics
Nov 06, 2025When a language model generates text, the selection of individual tokens might lead it down very different reasoning paths, making uncertainty difficult to quantify. In this work, we consider whether reasoning language models represent the alternate paths that they could take during generation. To test this hypothesis, we use hidden activations to control and predict a language model's uncertainty during chain-of-thought reasoning. In our experiments, we find a clear correlation between how uncertain a model is at different tokens, and how easily the model can be steered by controlling its activations. This suggests that activation interventions are most effective when there are alternate paths available to the model -- in other words, when it has not yet committed to a particular final answer. We also find that hidden activations can predict a model's future outcome distribution, demonstrating that models implicitly represent the space of possible paths.
Forking Paths in Neural Text Generation
Dec 10, 2024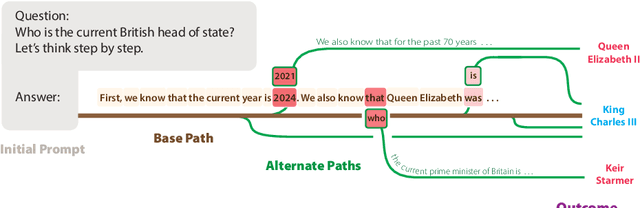
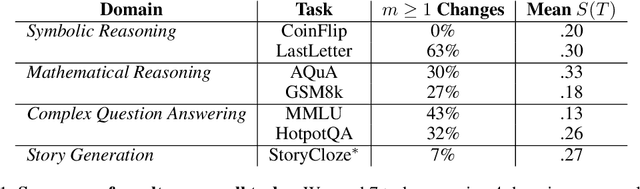
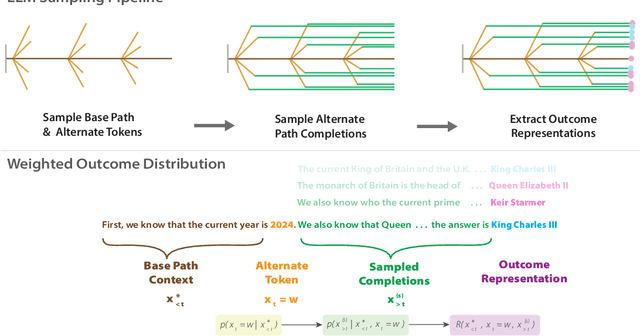
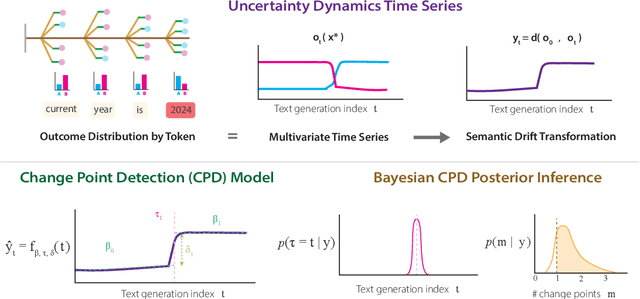
Estimating uncertainty in Large Language Models (LLMs) is important for properly evaluating LLMs, and ensuring safety for users. However, prior approaches to uncertainty estimation focus on the final answer in generated text, ignoring intermediate steps that might dramatically impact the outcome. We hypothesize that there exist key forking tokens, such that re-sampling the system at those specific tokens, but not others, leads to very different outcomes. To test this empirically, we develop a novel approach to representing uncertainty dynamics across individual tokens of text generation, and applying statistical models to test our hypothesis. Our approach is highly flexible: it can be applied to any dataset and any LLM, without fine tuning or accessing model weights. We use our method to analyze LLM responses on 7 different tasks across 4 domains, spanning a wide range of typical use cases. We find many examples of forking tokens, including surprising ones such as punctuation marks, suggesting that LLMs are often just a single token away from saying something very different.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.