 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Guidance for Transformer Language Models
Paper and Code
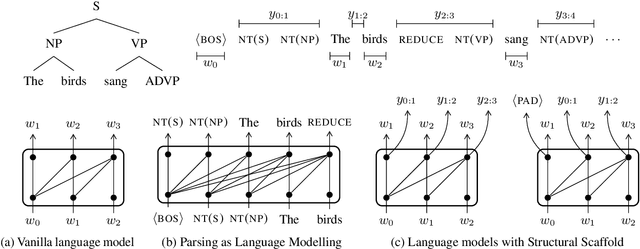
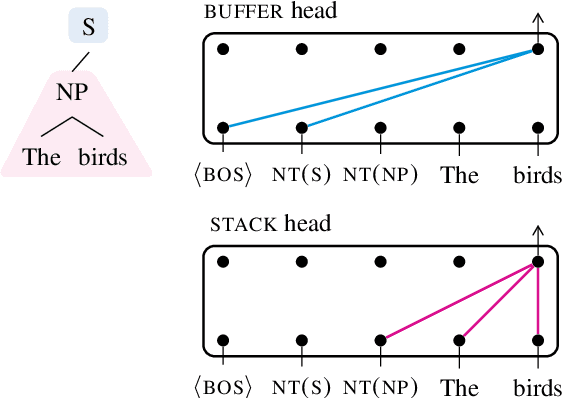
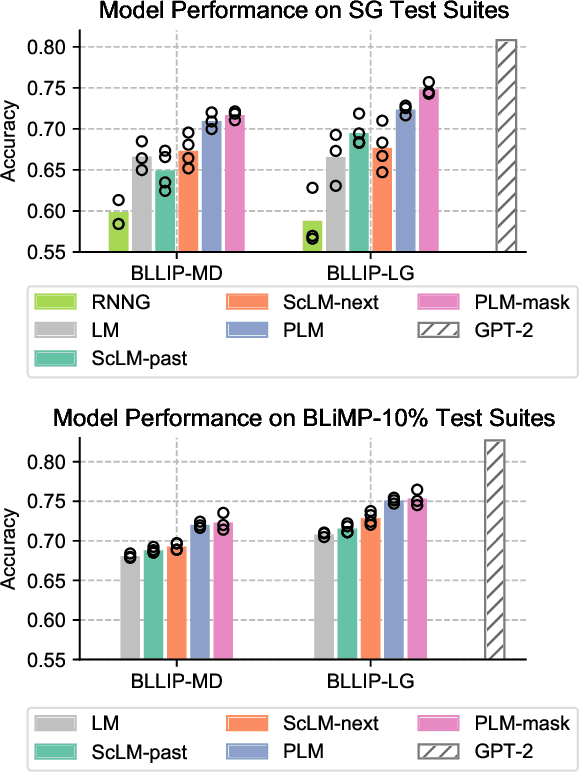
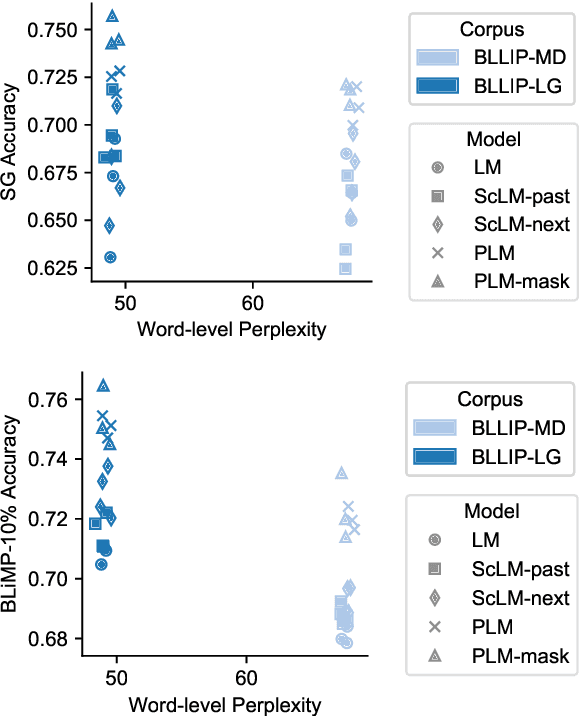
Transformer-based language models pre-trained on large amounts of text data have proven remarkably successful in learning generic transferable linguistic representations. Here we study whether structural guidance leads to more human-like systematic linguistic generalization in Transformer language models without resorting to pre-training on very large amounts of data. We explore two general ideas. The "Generative Parsing" idea jointly models the incremental parse and word sequence as part of the same sequence modeling task. The "Structural Scaffold" idea guides the language model's representation via additional structure loss that separately predicts the incremental constituency parse. We train the proposed models along with a vanilla Transformer language model baseline on a 14 million-token and a 46 million-token subset of the BLLIP dataset, and evaluate models' syntactic generalization performances on SG Test Suites and sized BLiMP. Experiment results across two benchmarks suggest converging evidence that generative structural supervisions can induce more robust and humanlike linguistic generalization in Transformer language models without the need for data intensive pre-training.