 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Interpretability of Lexical Semantic Change with Neurobiological Features
Feb 10, 2026Lexical Semantic Change (LSC) is the phenomenon in which the meaning of a word change over time. Most studies on LSC focus on improving the performance of estimating the degree of LSC, however, it is often difficult to interpret how the meaning of a word change. Enhancing the interpretability of LSC is a significant challenge as it could lead to novel insights in this field. To tackle this challenge, we propose a method to map the semantic space of contextualized embeddings of words obtained by a pre-trained language model to a neurobiological feature space. In the neurobiological feature space, each dimension corresponds to a primitive feature of words, and its value represents the intensity of that feature. This enables humans to interpret LSC systematically. When employed for the estimation of the degree of LSC, our method demonstrates superior performance in comparison to the majority of the previous methods. In addition, given the high interpretability of the proposed method, several analyses on LSC are carried out. The results demonstrate that our method not only discovers interesting types of LSC that have been overlooked in previous studies but also effectively searches for words with specific types of LSC.
Discovering Highly Influential Shortcut Reasoning: An Automated Template-Free Approach
Dec 15, 2023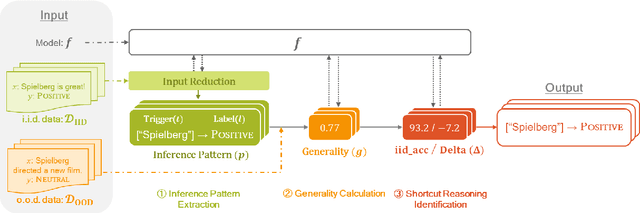
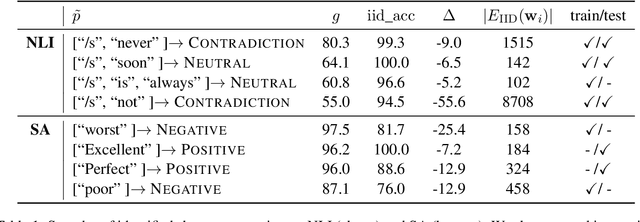

Shortcut reasoning is an irrational process of inference, which degrades the robustness of an NLP model. While a number of previous work has tackled the identification of shortcut reasoning, there are still two major limitations: (i) a method for quantifying the severity of the discovered shortcut reasoning is not provided; (ii) certain types of shortcut reasoning may be missed. To address these issues, we propose a novel method for identifying shortcut reasoning. The proposed method quantifies the severity of the shortcut reasoning by leveraging out-of-distribution data and does not make any assumptions about the type of tokens triggering the shortcut reasoning. Our experiments on Natural Language Inference and Sentiment Analysis demonstrate that our framework successfully discovers known and unknown shortcut reasoning in the previous work.
TabEAno: Table to Knowledge Graph Entity Annotation
Oct 05, 2020
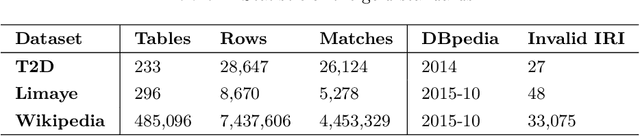
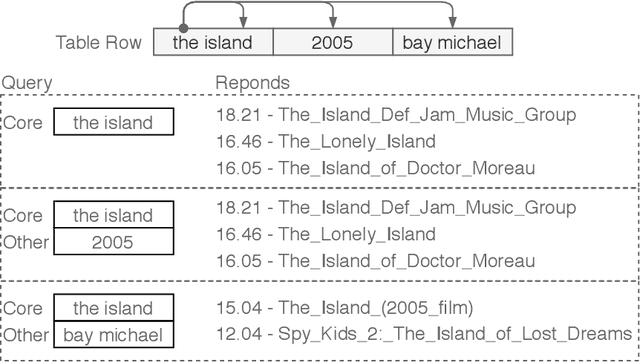
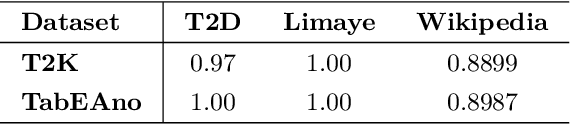
In the Open Data era, a large number of table resources have been made available on the Web and data portals. However, it is difficult to directly utilize such data due to the ambiguity of entities, name variations, heterogeneous schema, missing, or incomplete metadata. To address these issues, we propose a novel approach, namely TabEAno, to semantically annotate table rows toward knowledge graph entities. Specifically, we introduce a "two-cells" lookup strategy bases on the assumption that there is an existing logical relation occurring in the knowledge graph between the two closed cells in the same row of the table. Despite the simplicity of the approach, TabEAno outperforms the state of the art approaches in the two standard datasets e.g, T2D, Limaye with, and in the large-scale Wikipedia tables dataset.
MTab: Matching Tabular Data to Knowledge Graph using Probability Models
Oct 01, 2019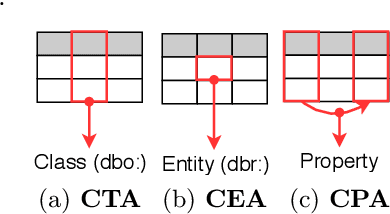
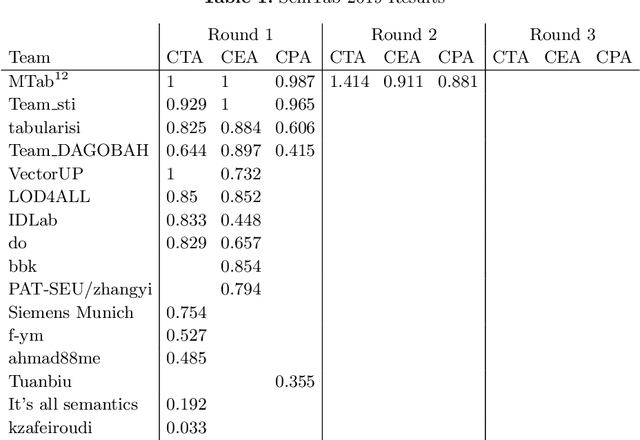
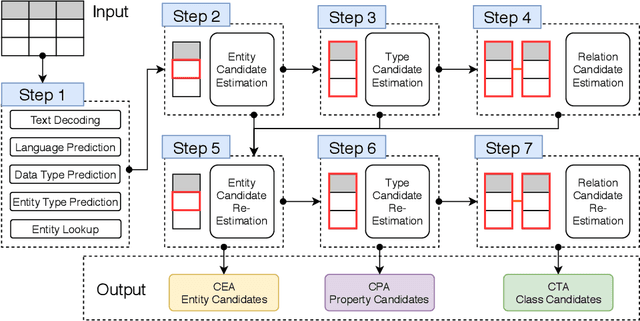
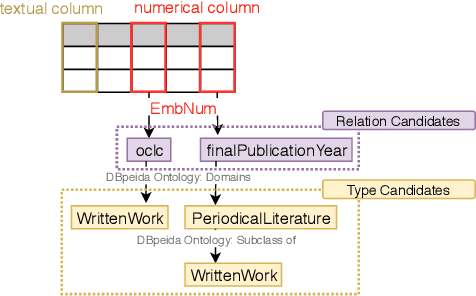
This paper presents the design of our system, namely MTab, for Semantic Web Challenge on Tabular Data to Knowledge Graph Matching (SemTab 2019). MTab combines the voting algorithm and the probability models to solve critical problems of the matching tasks. Results on SemTab 2019 show that MTab obtains promising performance for the three matching tasks.