 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbNum: Semantic labeling for numerical values with deep metric learning
Paper and Code
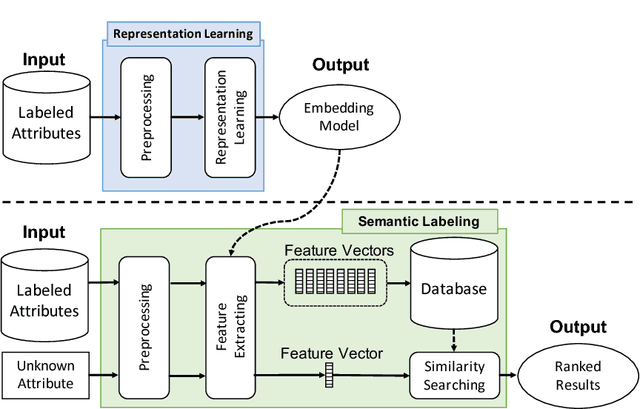

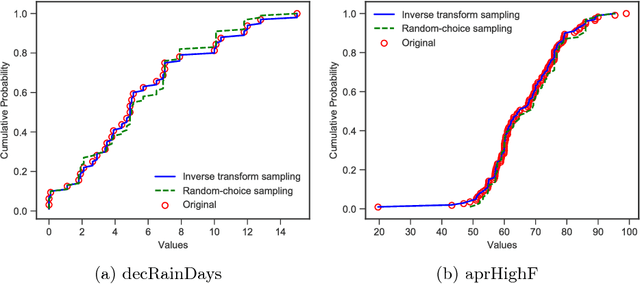
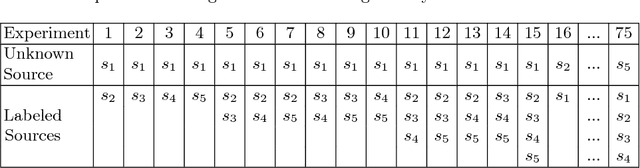
Semantic labeling for numerical values is a task of assigning semantic labels to unknown numerical attributes. The semantic labels could be numerical properties in ontologies, instances in knowledge bases, or labeled data that are manually annotated by domain experts. In this paper, we refer to semantic labeling as a retrieval setting where the label of an unknown attribute is assigned by the label of the most relevant attribute in labeled data. One of the greatest challenges is that an unknown attribute rarely has the same set of values with the similar one in the labeled data. To overcome the issue, statistical interpretation of value distribution is taken into account. However, the existing studies assume a specific form of distribution. It is not appropriate in particular to apply open data where there is no knowledge of data in advance. To address these problems, we propose a neural numerical embedding model (EmbNum) to learn useful representation vectors for numerical attributes without prior assumptions on the distribution of data. Then, the "semantic similarities" between the attributes are measured on these representation vectors by the Euclidean distance. Our empirical experiments on City Data and Open Data show that EmbNum significantly outperforms state-of-the-art methods for the task of numerical attribute semantic labeling regarding effectiveness and efficiency.