 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Aware Automatic Verbalizer for Few-Shot Text Classification
Oct 19, 2023



Prompt-based learning has shown its effectiveness in few-shot text classification. One important factor in its success is a verbalizer, which translates output from a language model into a predicted class. Notably, the simplest and widely acknowledged verbalizer employs manual labels to represent the classes. However, manual selection does not guarantee the optimality of the selected words when conditioned on the chosen language model. Therefore, we propose Label-Aware Automatic Verbalizer (LAAV), effectively augmenting the manual labels to achieve better few-shot classification results. Specifically, we use the manual labels along with the conjunction "and" to induce the model to generate more effective words for the verbalizer. The experimental results on five datasets across five languages demonstrate that LAAV significantly outperforms existing verbalizers. Furthermore, our analysis reveals that LAAV suggests more relevant words compared to similar approaches, especially in mid-to-low resource languages.
A Summary of the ALQAC 2021 Competition
Apr 25, 2022


We summarize the evaluation of the first Automated Legal Question Answering Competition (ALQAC 2021). The competition this year contains three tasks, which aims at processing the statute law document, which are Legal Text Information Retrieval (Task 1), Legal Text Entailment Prediction (Task 2), and Legal Text Question Answering (Task 3). The final goal of these tasks is to build a system that can automatically determine whether a particular statement is lawful. There is no limit to the approaches of the participating teams. This year, there are 5 teams participating in Task 1, 6 teams participating in Task 2, and 5 teams participating in Task 3. There are in total 36 runs submitted to the organizer. In this paper, we summarize each team's approaches, official results, and some discussion about the competition. Only results of the teams who successfully submit their approach description paper are reported in this paper.
A Comparative Study of Pretrained Language Models on Thai Social Text Categorization
Dec 17, 2019


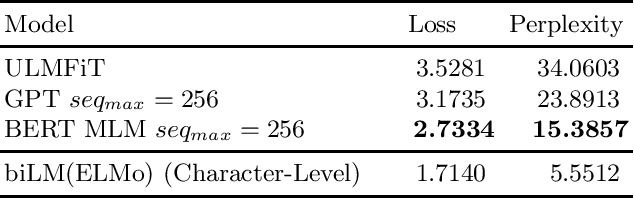
The ever-growing volume of data of user-generated content on social media provides a nearly unlimited corpus of unlabeled data even in languages where resources are scarce. In this paper, we demonstrate that state-of-the-art results on two Thai social text categorization tasks can be realized by pretraining a language model on a large noisy Thai social media corpus of over 1.26 billion tokens and later fine-tuned on the downstream classification tasks. Due to the linguistically noisy and domain-specific nature of the content, our unique data preprocessing steps designed for Thai social media were utilized to ease the training comprehension of the model. We compared four modern language models: ULMFiT, ELMo with biLSTM, OpenAI GPT, and BERT. We systematically compared the models across different dimensions including speed of pretraining and fine-tuning, perplexity, downstream classification benchmarks, and performance in limited pretraining data.
Semi-supervised Thai Sentence Segmentation Using Local and Distant Word Representations
Aug 25, 2019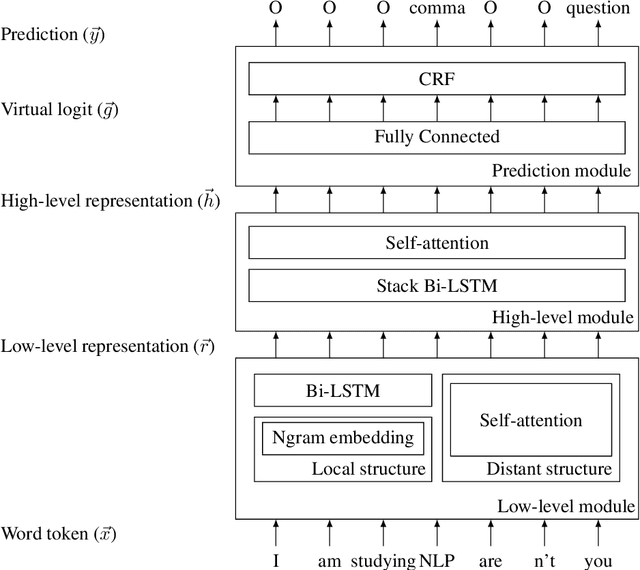

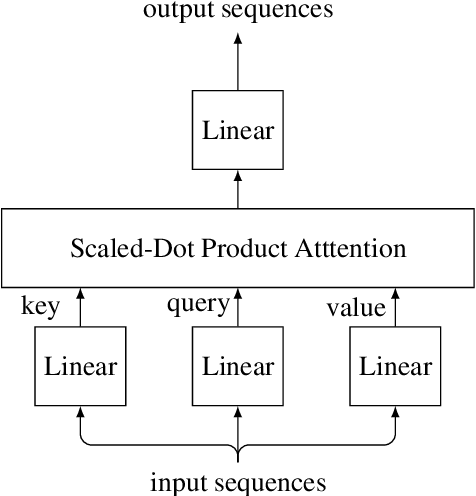
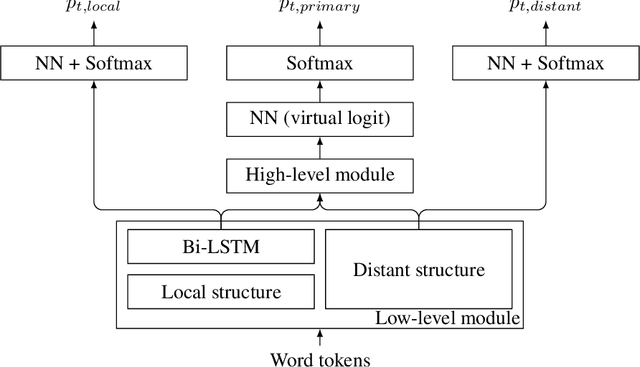
A sentence is typically treated as the minimal syntactic unit used for extracting valuable information from a longer piece of text. However, in written Thai, there are no explicit sentence markers. We proposed a deep learning model for the task of sentence segmentation that includes three main contributions. First, we integrate n-gram embedding as a local representation to capture word groups near sentence boundaries. Second, to focus on the keywords of dependent clauses, we combine the model with a distant representation obtained from self-attention modules. Finally, due to the scarcity of labeled data, for which annotation is difficult and time-consuming, we also investigate and adapt Cross-View Training (CVT) as a semi-supervised learning technique, allowing us to utilize unlabeled data to improve the model representations. In the Thai sentence segmentation experiments, our model reduced the relative error by 7.4% and 10.5% compared with the baseline models on the Orchid and UGWC datasets, respectively. We also applied our model to the task of pronunciation recovery on the IWSLT English dataset. Our model outperformed the prior sequence tagging models, achieving a relative error reduction of 2.5%. Ablation studies revealed that utilizing n-gram presentations was the main contributing factor for Thai, while the semi-supervised training helped the most for English.